If you could just give the %CPU column output of the top command for Snips hotword and Snowboy, that could be helpful.
Will do both idle and detecting hotword for both once at home.
To be looking for new software and solutions its not a good idea to use something as the pi-zero as a critical selection for choice.
The zero is great but its design and hardware is absolutely antiquated by today’s standard and quite likely will be superceded.
Rockchip and Allwinner both have similar priced Socs that leap up A35 or even have codecs or accelerators.
The RockPi-S is $13.99 quad core A35 with audio codec.
I expected a few new releases and boards but much seems to of gone covid shape in the current uncertainty.
@fastjack I am not sure about gnu-ne10-mfcc as its not used by Linto as in their code to my surprise its Sonopy (think that was its name) but the Mycroft python lib.
I have posted this before but https://github.com/JuliaDSP/MFCC.jl looks really awesome and Julia for you Python guys isn’t supposed to be that much of a big deal, but hey that is all I have read 
I have been looking at how MFCC & VAD is created and they seem to share a common heavy FFT process that for some reason is always split into two libs and threads whilst a MFCC lib could very well have a few additional parts of the VAD added to it.
Its been a hunch by me, but if someone had the talent it would prob definitely reduce a considerable amount of what is the heavy process feed to KWS.
I you are going to start programming and adopting something for the future then the critical selection would be to have neon support and not to exclude it.
The ne10 FFT routines are supposed to be really slick but maybe something more generic like FFT3W should be used as it will compile for many platforms as you never know someone might be bat shit crazy enough to want to use it on X86
I think that Julia lib does share process with VAD & MFCC but its SAD (Speech Activity Detection) not VAD and don’t joke about being SAD if you wish the author to ever converse again
PS the GPU FFT is a cul-de-sac as the memory transfer cost outweighs any benefit its actually on all pis in the opt directory samples and is really a relic.
I agree, that the hardware is not completely up to date, but on the other hand it is used by a ton of people and has reasonable software support, while all the rockchip/allwinner chips usually have a pretty small user base. And since it is quite cheap aswell it will be used a lot for satellite devices, thats why at least for the wakeword engine it is important to consider the pi zero aswell as long as it is used so much. (In my eyes what all these “raspberry pi killer boards” do not get is that the reason to use the pi is not not the superior performance, but the huge community behind it)
2 Likes
@rolyan_trauts I agree. The FFT part is indeed the heavier piece of the MFCC extraction. Offloading the FFT and maybe the DTW to the GPU might provide quite an improvement.
As I have said above, the gpu-ne10-mfcc lib looks like something that was never really used or even completed. A dead end for me (though the idea to use Neon might be valid)
Using the GPU of the Pi Zero (and of all the other Pis that use VideoCore IV) should not hurt performance and should greatly improve the CPU load (since at the moment everything is done by the CPU).
I’ll be testing FFTW3 on a Pi zero soon to see if it provides improvements on CPU usage (the Gist library I’m using can already use FFTW instead of the default Kiss FFT).
I hope (not a C++ dev so… fingers crossed  ) to also add GPU FFT into Gist to see the difference between the 3 libs on a Pi Zero… I’ll keep you all posted.
) to also add GPU FFT into Gist to see the difference between the 3 libs on a Pi Zero… I’ll keep you all posted.
Cheers
2 Likes
The GPU method for the zero you can email andrew@aholme.co.uk if you wish as he is a nice guy and will reply.
Hello Stuart,
Although GPU_FFT was faster than the ARM on the original RPi, Peter Onion told me he got equivalent or better performance from FFTW using NEON instructions on a newer RPi.
Forgot what it was as did do more research might be the DMA access of the GPU but small but rapid frame swaps don’t really suit and anything PiII or above is slower.
I remember thinking zero increases are marginal and its slower on all the rest, sod that.
Its pure daft to waste time on a Pi Zero as a Pi3A+ gives approx 10x capacity for just 10x more.
The problem with the zero now is because its not good enough for purpose as you wouldn’t be looking for magic speedups.
Magic speedups don’t exist and all you are going to do is make something not fit for purpose fractionally faster.
@maxbachmann yeah in general use RaspiOS has much more support but when you have a very specific use like we have here you can be very specific.
I am not even suggesting use the RockPiS as I was just using that board to show how antiquated the Pi0 has become when a small scale supplier can provide Pi3 perf at Zero price.
My suggestion would be to tell users that a Pi3A+ is the minimum supported and there are alternatives such as the RockPiS and Pi0 but don’t waste time hampering the project.
When you are talking $15 satellites we are actually not in the realms of a general purpose SoC but much more akin to embedded of very specific purpose and the only criteria for many is price as costs can quickly add up when talking about the multiples that could be common.
Both the RockPiS & Zero come in at that price but the zero instantly hits walls of process wise the answer to any additional audio processing is no. The answer to further security (stunnel) is no, because there is no load space left and all that lovely compatible OS is worth jack shit because the Zero is already maxxed out and it has no room to fit any more.
Its totally pointless to be focussing on what is likely a product to soon be superceded that is different to every model since the Pi2.
There are raspberry products that solve all the problems with the Zero and its much better to be honest an say yeah spend $10 more than roll out crap where a community thinks what you supply is rather poor.
You are actually better with a Pi3 and a USB sound card as there is very little difference with end result price with 10x process load of the zero.
Or you can use a RockPiS and I have took the plunge and doing a systematic evaluation of cost, function, performance and quality you can expect but will do a write up here and yeah its very much a Zero killer for audio orientated applications as that was what it was designed for.
Its a modern A35 design specifically designed for VoiceAi style apps even has a DSP VAD that runs on interrupts for 4 mics and when in sleep mode monitors VAD on a single mic to wake.
Its so specific and at such a good cost price its totaly a brain fart of bean overload to ignore, but yeah for satellites as I commonly say my favourite Raspberry SoC by far is the Pi3A+ as it is still a kick ass piece of kit whilst the PiI inherited Zero really is starting to groan.
The RK3399 became very popular when we where stuck with the Pi3 but the Pi4 has sort of dented the Pine & Radxa offerings quite badly now.
RK3308 until we get a Zero-2 is actually a good option but when the zero-2 comes out probably less so.
Raspberry being Raspberry its likely to be later but as a betting man next year there might be a chance we see all that Pi2-Pi3 IP in a smaller process @ Zero prices.
As a betting man any Zero specific work you do now prob has a max of 2 years life.
I do agree that the Pi3A+ is an often underestimated part of the Raspberry Pi family, and it makes an excellent (although probably too powerful) satellite device.
However, many people still have Raspberry Pi Zero Ws lying around, once used as Snips satellites. And with the right optimized software, these devices should be perfectly capable of executing this task (Snips managed to do it), and they are cheaper than the Pi 3A+.
I also wouldn’t call the Pi Zero W “soon to be superceded”. The Raspberry Pi Foundation claims that:
Raspberry Pi Zero W will remain in production until at least January 2026
So even if there comes a successor, it’s not like the Pi Zero W will disappear.
So, I wouldn’t focus all our resources on getting the wake word engine on the Pi Zero W working, but I think it’s still worthwhile to have it as a cheap option.
2 Likes
The Pi3B+ will be available to January 2023 and @ $35 its obsolete by the Pi4 2gb which is a 1$ cheaper.
The Pi Zero will run till January 2026 but that doesn’t mean Raspberry will not have a replacement way before then and the January 2026 date has Zero relevance (Like what I did there ) to what we might see.
If we don’t there are already alternatives that are far better at the same price or a step up to Pi3A+.
It doesn’t matter what Snips did as its extremely debatable what Snips would do now as they had a team who were extremely forward thinking.
For me who likes EC functionality then the Zero isn’t an option as it just can not do it, full stop.
It’s also not a cheaper option as with Hat’s and ancillaries the difference to the RockPiS is extremely minimal and doesn’t need a Hat Codec.
A Pi3A+ with 2x I2S mics can use the 3.5mm and still upgrade to a HDMI2HDMI+Audio extractor without need to jettison the extremely cost effective mics.
Then again on both its still prob better to go for just an extremely cheap sound card and couple with an active mic module, but is the zero cheaper is debatable as it needs extra $ to make a working solution.
But this is why I am writing as yeah you can say the Pi0W is a cheap option or like me who has several gaining dust would I use one to create a complete satellite.
Hell no with all the extra cost to complete as it doesn’t make sense now never mind in a year or 2 and as for the off chance they may have a ZeroW it’s equally likely for the Raspberry niche that a Pi2,3 or even a new Pi4 to be collecting dust.
If your focus is existing owners its not true that the Pi0W is the most common and if they are already owned they are certainly no cheaper.
But why are you even thinking about the odd occurance of a Pi owner thinking I could repurpose that than someone with an interest in voiceAI who wants to try a working best price/perf solution of an opensource design?
Well, let’s agree to disagree there, but I actually agree with your other remark that for a $15 price range we should probably look at embedded solutions. If you have some input there, I would love to hear it in the other forum topic.
I don’t think the embedded devices cut the mustard anymore as they are of a similar cost to many dedicated Socs of much more flexibility and capability.
You can take an embedded direction with those socs and create a Buildroot or Yocto ‘embedded’ solution as there is no advantage in cost with say what might be used such as the ESP32-LyraT-Mini.
That was my point as the new function specific low cost Arm boards can be specific embedded solutions and the advantages of a general purpose OS is not so much of an advantage.
If you have a matrix voice its great that a repo is supplied but to purchase one now @$75 with what is available is an extremely dubious choice in terms of $.
MATRIX Voice ESP32 Version (WiFi/BT/MCU)
They are more of a legacy to all what was available a year or more ago when Snips was around that is no longer true now and definitely not of the future.
I’ve tested FFTW3 in place of KISS FFT and there was no noticeable change in the CPU usage on a Pi Zero (still 45% CPU min only for MFCCs).
45% min is pretty hefty but good to know you got it working as FFTW3 if compiled for A53 should use neon from memory.
Anyone got any clues to interfacing Julia libs to Python? But got a feeling could even be worse.
I was able to get the CPU % down significantly and have Raven run pretty well on a Pi Zero by:
- implementing @fastjack’s MFCC optimization (or some flavor of it)
- MFCC is calculated once on an incoming audio chunk and the matrix is reused when sliding windows
- Pre-computing the DTW distance matrix using scipy.spatial.distance.cdist
- This made a huge difference in speed, rather than computing the cosine distances as needed inside the DTW for loops
One area where the Zero still as problems is when there’s a lot of audio that activates the VAD but doesn’t match a template. This gets buffered and processed, but can clog it up for a few seconds as the DTW calculations run.
A way to help might be to say if so many frames in a row have very low DTW probabilities (< 0.2) that audio is dropped for a little while. Any thoughts on this? Maybe it will be moot once the DTW calculations are externalized.
MFCC doesn’t seem to be the bottleneck so far.
3 Likes
Thinking about it 45% isn’t all that bad on a Pi Zero as its just short of horsepower.
Acoustic EC on the Pi3 is really heavy but actually doesn’t matter at all because of the diversification of process.
It only runs heavy when audio is playing, doesn’t run on input and TTS is generally the end result of process.
So it doesn’t matter as it runs at alternative timeslots to other heavy process and diversifies load.
How much load does RhasspySilence produce on its own on a zero as isn’t VAD just the summation of a couple of successive frames of the same FFT frame routine that is duplicated in MFCC creation?
You can actually see the spectra in a MFCC so surely you can grab the spectra bins of the low and high pass filter that VAD uses from MFCC instead of WebRtcVad and log the sum there and do away with RhasspySilence at least on a Zero?
Then use diversification and turn off MFCC/VAD after silence until the audio capture is processed.
You don’t have to halt after silence but I am pretty sure the single frame MFCC calculation could make an excellent successive VAD detection with hardly any more load than MFCC itself.
What is the load of RhasspySilence or is it pretty minimal anyway?
Also again from the above it seems like MFCC is batched and searched after whilst like VAD should be frame by frame?
As if your DTW probabilities don’t fit for X series of frames then doesn’t DTW restart again on the current frame?
With webrtcvad I was seeing maybe a millisecond to process a 30 ms chunk of audio.
I’m betting there’s some savings that could be had by combining the VAD, MFCC, and DTW steps. MFCC/DTW are done on “template-sized” chunks of audio (the average length of your wake word), whereas webrtcvad mandates 10, 20, 30 ms chunks.
Some ways I could think to save CPU:
- Use VAD to decide whether a whole template-sized chunk is worth processing
- I wait to process audio until VAD says there’s speech, but if the majority of a template-sized chunk is silence I will still process it (MFCC/DTW)
- Re-use FFT from VAD in MFCC calculation
- Would work well if they’re processing the same chunk size
- Abort DTW calculation early if it can’t reach threshold
- Not sure if this is possible, but I would guess you could tell at some point in DTW that the final distance can’t ever get above threshold. In that case, abort the rest of the calculation.
1 Like
Just so the new Raven doc : https://rhasspy.readthedocs.io/en/latest/wake-word/#raven
Does it support multiple personal wakewords ? How to set them ?
Dunno as the FIR filters which are just FFT routines of webrtc are all contained in WebRTCAudioProcessing and as individual FFT routines you don’t have api access just the results.
@fastjack was testing actual FFT libs for MFCC so sounds like at that point you do have access to the FFT routines and they are not just submerged in some lib.
You mean use the FFT frame for both MFCC frame and VAD calculation and drop webrtcvad?
I added a place in the web UI to record the examples:
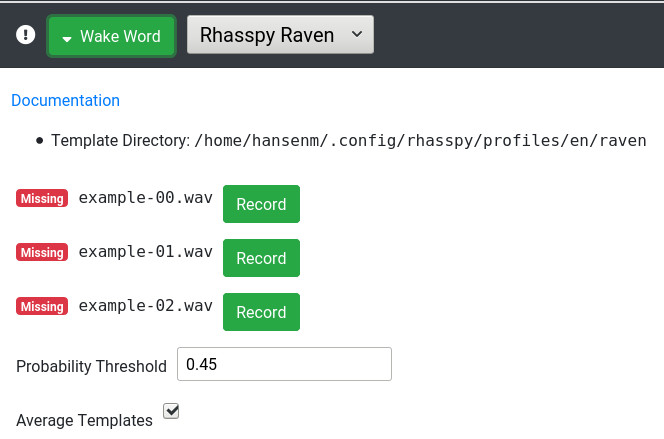
You click “Record” next to each example and speak it. Right now, the web UI doesn’t support multiple wake words but this is absolutely possible in Raven
Per @fastjack’s suggesting, I’m also working on the ability for Raven to save any positive detections to WAV files so you can train another system like Precise down the road.
4 Likes
Right. Seems like there are multiple FFTs being done on the same audio.
1 Like
Looking at Raven WAV templates dir, it seems there is no way to have a keyword use multiple templates (for later averaging per keyword). Averaging templates from different speakers will result in very poor accuracy.
As this is “personal” wake words, it would be nice to have the ability to setup multiple keywords (one for each family member) with multiple templates each (reducing calculation by averaging templates per keyword).
Maybe something like:
templates_dir/
keyword1/
template1.wav
template2.wav
keyword2/
template3.wav
template4.wav
...
And a CLI args like:
--keywords "./templates_dir/"
or
--keyword "keyword1=./templates_dir/keyword1/*.wav,sensitivity=0.54"
--keyword "keyword2=./templates_dir/keyword2/*.wav"
PS: Not a CLI expert 
2 Likes