When I say music, I mean normal, low level background music.
In such environment, the wakeword (raven) trigger, it turn into listening state, and never ends …
Without music, all is running fine.
Which settings should I look at for this ?
With Snips I never had problems asking commands with low / medium music level, with same hardware (rpi/respeaker 2 mic hat). So I guess it’s a settings thing (hope!).
Yesterday I had exact same thing with dishwasher running at ten meters, really low sound level.
When it finnally end listening (maybe some timeout ?) it goes to thinking mode and stay there for hours (till I disconnect all and throw it through the window).
So what can we do for this ? I don’t live in a dark room
Don’t tell me it is unusable in family living room ??
Also, we have min_sec setting. Maybe we could have max_sec so rhasspy doesn’t stay hours listening for a command. A max_duration to 5 seconds should work for usual commands and help a lot.
Also when is such state, if someone say the wakeword, it is triggered (!!) again before rhasspy have understood anything, and once timeout it will loop again and so on.
But with so low background noise making it unable to understand anything, this is really problematic. If anyone have settings to make thing better, or share experience on this ?
This is what audio algorithms like beam-forming (for barge in and background noise reduction) and AEC (for playback cancellation) are so important when using far field omni directional mic(s) (see posts from @rolyan_trauts).
Raven is sensitive to background noise (as opposed to Precise which can be trained to better handle it) but should work with low to medium level noises (tv, radio, traffic) as you have experienced.
The problem comes from the end of utterance detection. Rhasspy uses VAD to capture ambiant noise at the start of the utterance (before the speaker starts) and trigger the end of the detection when it reaches that level again for a long enough period. With medium background noise I fear that the delta between no-voice+background and voice+background is not sufficient to be detected.
Kaldi provides a better end of utterance detection called « endpointing » that uses speaker adaptation and CMVN to be more robust against noisy environment.
If @synesthesiam could ditch VAD in favor of endpointing when using Kaldi the situation should improve. I think that’s why he is currently working to improve Kaldi acoustic models in more languages so Rhasspy can use Kaldi as the default STT system (which would be awesome as Kaldi provides outstanding STT features: grammar FST, endpointing, etc.).
I think having max_duration settings for command recognition could also help. At least it would not let rhasspy in this listening state for hours. Better to understand nothing during a moment than being stuck for a while.
This is correct. I’d like to have Kaldi be the default so we can focus on having a better default experience for users. Other STT engines will not be as optimal, but they should still be usable. This means, of course, that we need Kaldi models for ALL THE LANGUAGES…
An interesting idea I read was to use a “wake word” to end the utterance too. This side-steps the silence detection problem as long as you have a good wake word system!
So the user could say something like (in English): ", turn on the living room light ". The only issue I can see here is that words like “please” may be a little short.
I have rooted mine out @KiboOst and when you open up alsamixer its a bit of a what the ferk is all that as much to be honest should be hidden.
Going back to WM8960 datasheet will help as Seeed are not that great when it comes to actual info.
Its been so long since I played with the Pi 2 Mic that this is like me starting from scratch again.
I would set the capture gain back to its default of 40 (12db) gain or turn right down to 0db and let ALC take over.
Then set up the ALC.
Hold time is the time delay between the peak level detected being below target and the PGA gain
beginning to ramp up. It can be programmed in power-of-two (2n
) steps, e.g. 2.67ms, 5.33ms,
10.67ms etc. up to 43.7s. Alternatively, the hold time can also be set to zero. The hold time only
applies to gain ramp-up, there is no delay before ramping the gain down when the signal level is
above target.
Decay (Gain Ramp-Up) Time is the time that it takes for the PGA gain to ramp up across 90% of its
range (e.g. from –15B up to 27.75dB). The time it takes for the recording level to return to its target
value therefore depends on both the decay time and on the gain adjustment required. If the gain
adjustment is small, it will be shorter than the decay time. The decay time can be programmed in
power-of-two (2n
) steps, from 24ms, 48ms, 96ms, etc. to 24.58s.
Attack (Gain Ramp-Down) Time is the time that it takes for the PGA gain to ramp down across 90%
of its range (e.g. from 27.75dB down to -15B gain). The time it takes for the recording level to return to
its target value therefore depends on both the attack time and on the gain adjustment required. If the
gain adjustment is small, it will be shorter than the attack time. The attack time can be programmed in
power-of-two (2n
) steps, from 6ms, 12ms, 24ms, etc. to 6.14s.
Usually you want a fast attack somewhere about 20ms with aggressive ramps you create square waves and distortion but with attack its OK we are just going to do that quick and stop any overload / clipping.
Hold is a great feature to have with voice as it can help stop ramping up during pauses between words.
Delay is the time it takes to ramp to max gain.
200ms can be a pause between words and maybe a 100-200ms hold is a good starting point.
The decay the ramp up to max can be much longer 10x that amount as after you stop speaking it will ramp up to the max in any period of silence.
I might have to spend some time with this again as the Seeed implementation seems to be very hacky but the codec is actually great.
Amixer -c2 (your card index) will also show settings as for some reason could not toggle the noise gate in alsamixer amixer -c2 cset numid=35 1 will enable
It always confused the hell out of me as the correlation to what I thought I was setting and actual setting was always confusing.
But running on ALC rather than constant gain with maybe quite a high noise gate level which just drops all low order volume from the capture.
You just have to play but with ALC it should allow you to set those and record and test. arecord -D plughw:seeed2micvoicec -r16000 -fS16_LE -c2 test.wav
Drag into audacity through winscp and check your results and see what your sound card is doing when these noises exist.
The card is a omnidirectional card with no beamforming but at least with ALC it should pick up an the loudest noise and if you shout at it, it will auto level to that input
If you want to help with media it plays then we can cancel that with AEC but with 3rd party noise we have no algs to differentiate you from that noise but VAD should work.
I am not sure why but https://github.com/wiseman/py-webrtcvad which is the one I think your using has a sensitivity setting and why no-one has asked you to tweak this is confusing.
Optionally, set its aggressiveness mode, which is an integer between 0 and 3. 0 is the least aggressive about filtering out non-speech, 3 is the most aggressive. (You can also set the mode when you create the VAD, e.g. vad = webrtcvad.Vad(3)):
vad.set_mode(1)
I am not sure about how all this works but is it the KWS or the ASR that has not released?
If the ALC with the 2 mic drives you crazy you can enable software AGC and follow what I posted here
Also if you want to ‘barge-in’ with media its playing then EC will help much and that is also listed in the above.
There is another strange myth about mems microphones that without the high speed dsp we can just get a omnidirectional array ( >1 mic) and its going to be all wonderful.
The real reason mems where chosen was the tolerance for SNR and sensitivity was extremely tight so they are accurate enough to do high speed DSP on.
We don’t have access to high speed DSP unless you start paying out Xmos powered USB respeaker mics for approx $70.
So even if the session time out is fixed in noisy environs the SNR will be so high that recognition will be poor to fail, as those sensitive mems are omnidirectional and sensitive to all.
There are quite a collection of microphone array hats that are minus DSP and look like they have all the bells and whistles whilst without DSP they are just another microphone.
In fact worse than that as the mics are fixed and of a spacing and geometry that summing can have negative effects as they can form low or high pass filters based on geometry.
The only thing I can think of that is of a lower cost and more comparative to the sort of Pi3A+ price range is a directional electret on a USB sound card that gives a fixed beamformer that can cheaply help with noise suppression.
If you look at the below screen shot we have a cheap $2 USB sound card and a single uni-directional electret on a max9814 board. (The agc is turned off so we get fixed gain). You can estimate the ratio of rear vs forward close up <.5m near & just over 3m far.
Its a pain as yeah there is a bit of soldering involved but if you look at the near wav file above and compare against when the electret is reversed the directionality and noise suppression is excellent but lessens over distance.
You can make a fixed beamformer quite cheaply that can reject noise by placement.
Pimoroni recommend this card.
After testing a wide range of USB audio dongles, this was the winner through being simple, low on noise and artifacts
But even $2 cheapos still seem to do the job.
All the modules with electret are omnidirectional but I love the gain/agc on the Max9814 and I keep killing the cheap ones when desoldering but for a tad more these have headers pins instead and it is 3.6-12v with its own LDO and noticeably quieter.
The cheapo electrets are aliexpress ones Taidacent 9750 or Farnel/RS/Ebay do a Kingstate KEIG4537TFL-N that is better quality.
They have to be uni-directional and simply they have ports on the rear that simply cancel forward sound waves on the mic diaphragm and can do something that mems can not without DSP.
Its that or get a mems array with fast DSP when it comes to predominant 3rd party noise as there is no in between even if we do have some relatively nice looking arrays the strange thing is as an array they are totally pointless and just another microphone.
A broadside array is similar to the PS3eye and a mic spacing of 10-16mm with 9.7mm mics should be Ok (It will only increase in effect by 3-6db not double which is perceived at about 10db ).
You just sum with alsa /etc/asound.conf.
pcm.cap {
type plug
slave {
pcm "plughw:myusb"
channels 2
}
route_policy sum
}
So for about £10 you can make a fixed positional beamformer mono mic, or a stereo sum for approx double that (but not sure its worth it over what mono can do).
Cheap soundcards have woeful mic gain with passive mics but not so when powered by a mic pre-amp.
The stereo cards are line in, but your gain will be OK if less and the card gain will have to be increased over a mono.
Often TV and Media is static in position and we ourselves have common positions such as seats.
Position if you can so pointing away from noise and to the voice actor as much as possible and you will get fixed position noise suppression beamforming.
So after the session timeout fix if you do have predominant noise the above may still work whilst your omnidirectional mems will likely just be flooded with noise.
PS
AGC switch: when you don’t answer the jumper cap, AGC function is open, connected to the jumper cap is closed (with a jumper cap)
Th&S jumper = AGC off open = on had to trace the track as lord knows what the above means.
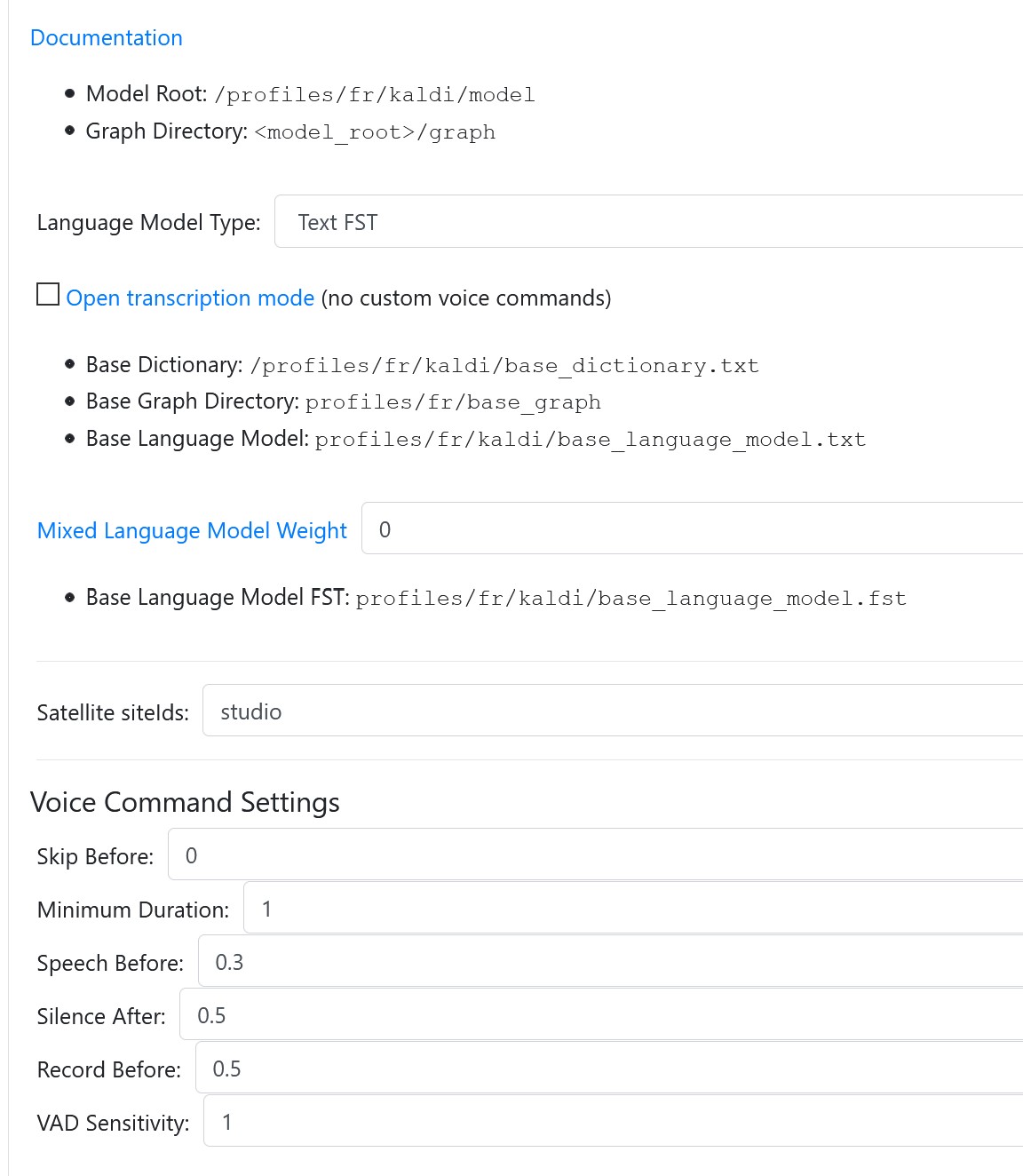
Does anyone played with new STT settigs being VAD, current energy, energy ratio etc ? Any feedback on these settings ?
How to know what sort of value to put as energy threslhold in settings ? is it between 0 and 1 or whatever ?
Just to give a very first/fast feedback test, with background music around normal vocal volume.
I allways speak at least a bit higher than background music, like I would when talking to a real person.
I can see a short sentence after wakeword wait for the 8sec timeout (thanls HLC), but then is recognized correctly, intent goes to Jeedom and action are done !
A lot more test to do of course, but great hope here !
Ok, a small step for Rhasspy but a big one for family:
Rhasspy is in production since yesterday afternoon !!
I had prepare complete integration into house with Jeedom scenarios, scripts, camera recognition etc so on this side all works perfectly with the plugin. Volume, leds along the day, scenarios etc (plugin)
I have a few false positive wake time to time, so the Surface is open to increase wakeword sensitivity step by step for each wakeword with Raven. To a point where I don’t have more false positive than with snips now and it still wake normally when we want.
With background music / noise, all command are recognized But it is only thanks to max duration setting in 2.5.9. I have increased Kaldi max/current energy ratio to 0.85, still have to find the right setting. But it works !
Snips disconnected for near 24h now and family interacting with Rhasspy is a big step, definitely. I now hope it will continue to the point I can dish snips, and convert snips Pis to rhasspy test setup for future evolutions
I have integrated into Jeedom some python Rhasspy Apps, to get weather in country/x days, get previous/next holidays or some friends birthdays etc. I had this in snips, but so easier to get them as python apps into Jeedom, called on intent by Jeedom. I may document this in the future, with python code so anyone can adapt it.
I will have to test with libasound2-plugin-equal to set the TTS voice less bass, more feminine. Had it on the Snips Pis, worked well. Alsa equaliser, here is how I set it with snips
I still miss a good universal duration slot and some date one, snips built-in slots were awesome.
I will also test asking several things to rhasspy. It did worked nice with snips, like Turn on the light in the kitchen and living-room, dunno if rhasspy will handle multiple same slots. Being different intents is another story, like turn off the light and start music.
Can’t wait to clean all snips stuff from Jeedom Decisive week-end
A long road for sure, with some amazing work from @synesthesiam and a lot who help on development or feedback, ideas, etc. We have to keep all this alive and continue to improve !
It makes me happy to read your story, @KiboOst. Thank you for sharing
Rhasspy still has a long way to go to rival a company product like Snips, but we’re making our way. Maybe someday, we’ll be even better.
This is still on the roadmap, but is going to require some serious attention and help. Getting it right across Rhasspy’s many supported languages will be quite the challenge!
Multiple values for the same slot is pretty straightforward. Multiple intents would work best with a different intent recognizer. I’m curious: in this case did Snips generate two Hermes intent messages?
Never done that with Snips. Actually with Snips I could ask same intent and several slots, after checking my old console backup, I hade such sentences into ( Turn on the light in the kitchen and living-room) so I will test adding such this and that into rhasspy sentences. Always looking forward
Well, this seems to be just multiple entities for one intent.
I used this without any scripting inside Jeedom with Snips.
I just updated the jeeRhasspy plugin so now I do it also with Jeedom/Rhasspy.
What would be more interesting is multiple intent handling:
Turn on the light in kitchen and off in the stairs
Or Turn on the light and close the shutter in kitchen
Now, don’t have a clue how to handle multiple intents in same sentence
@synesthesiam After 10 days of Rhasspy in production, I have delete, clean, trash all Snips stuff for my Jeedom
Test configuration is also in place, beginning to test new sentence/slots and ready for next things to come
One way could be to have Rhasspy generate multiple Hermes intents for a single recognition. But the “multi-intent” would need to be marked so I know which single intents were present.








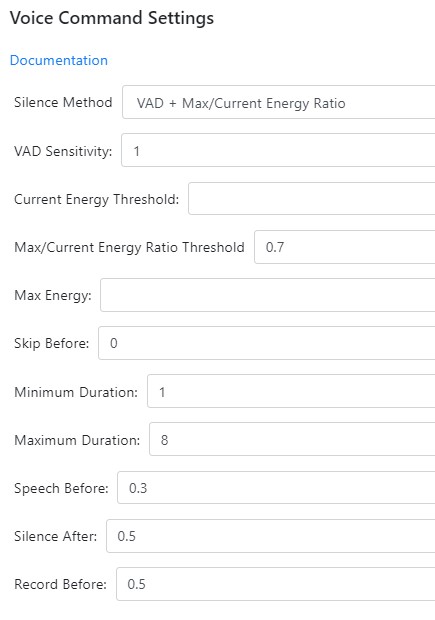


 But it is only thanks to max duration setting in 2.5.9. I have increased Kaldi max/current energy ratio to 0.85, still have to find the right setting. But it works !
But it is only thanks to max duration setting in 2.5.9. I have increased Kaldi max/current energy ratio to 0.85, still have to find the right setting. But it works !
 Decisive week-end
Decisive week-end 