Hello,
Now that I’ve had some time to deal with Precise, I’d like to share my experiences. Some information can also be found here. I have the feeling that I am the only one who is not satisfied with Snowboy - but there are advantages with Precise: Completely offline, the model can be trained further in case of problems, e.g. to drive out false positive recognitions. In version 2.5 Precise will be supported - thanks @synesthesiam !
Installation: Since I have installed Linux only on Raspberry Pi and they have too little computing power, I use the Windows Subsystem (WSL) to install Debian on my PC.
In Debian / WSL it is necessary to install some things. Some things may be redundant, but with the following commands I could install everything:
sudo apt-get install python-pyaudio python3-pyaudio
sudo apt-get install python3 python3-all-dev python3-pip build-essential swig git libpulse-dev
sudo apt install libasound-dev portaudio19-dev libportaudiocpp0
pip3 install pyaudio
sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
sudo apt-get install ffmpeg libav-tools
sudo pip install virtualenv
sudo add-apt-repository ppa:mc3man/trusty-media && sudo apt-get update && sudo apt-get install ffmpeg && ffmpeg -version
sudo -s
pip install pyaudio
Then I closed and reopened WSL and installed Precise as described in the instructions
git clone https://github.com/mycroftai/mycroft-precise
cd mycroft-precise
sudo ./setup.sh
After the installation it is important to know how to exchange files between Windows and the WSL. The files are located in the following path:
C:\Users\USERNAME\AppData\Local\Packages\TheDebianProject.DebianGNULinux_SOMENUMBERSANDLETTERS\LocalState\rootfs\home\USERNAME\mycroft-precise
Later, when the wake word is ready, copying from this path is no problem. But I had problems when I copied new files to the above path under Windows (Debian didn’t show the folders and files). So I created the folder structure in Debian:
cd mycroft-precise/
mkdir data/random
mkdir to_be_converted/convert_me
mkdir to_be_converted/converted
mkdir WAKEWORD_NAME/not-wake-word
mkdir WAKEWORD_NAME/test/not-wake-word
mkdir WAKEWORD_NAME/test/wake-word
mkdir WAKEWORD_NAME/wake-word
Create the following files with the contents below (in WSL) :
sudo nano to_be_converted/convert_me/convert_mp3.sh
Then in the nano editor, paste this and save using ctrl o - ENTER and exit using ctrl x
SOURCE_DIR=convert_me
DEST_DIR=converted
for i in $SOURCE_DIR/*.mp3; do echo "Converting $i..."; fn=${i##*/}; ffmpeg -i "$i" -acodec pcm_s16le -ar 16000 -ac 1 -f wav "$DEST_DIR/${fn%.*}.wav"; done
nano to_be_converted/convert_me/convert_wav.sh
Again in nano , paste this and save using ctrl o - ENTER and exit using ctrl x
SOURCE_DIR=convert_me
DEST_DIR=converted
for i in $SOURCE_DIR/*.wav; do echo "Converting $i..."; fn=${i##*/}; ffmpeg -i "$i" -acodec pcm_s16le -ar 16000 -ac 1 -f wav "$DEST_DIR/${fn%.*}.wav"; done
To convert the files you have to copy them to WSL, the easiest way to do this is to store the files in C: under Windows and copy them to WSL:
In Windows, for example, you create a path C:/to_be_converted/convert_me, fill it with the files to be converted and then copy it to Debian (replace USERNAME!).
cp -a /mnt/c/to_be_converted/. /home/USERNAME/mycroft-precise/to_be_converted/
Please copy only the files of one type here: Wakeword or files that do not contain a wakeword.
Now you can convert the files in Debian with the following commands, depending on whether you want to convert mp3 or wav:
sh to_be_converted/convert_mp3.sh
sh to_be_converted/convert_wav.sh
After successful conversion the files can be moved to the respective directory and the convert_me shall be emptied to avoid confusion and mixing:
If wakewords were converted for training
sudo mv to_be_converted/converted/ WAKEWORD_NAME/wake-word/
sudo rm to_be_converted/convert_me/*.*
If wakewords were converted for testing
sudo mv to_be_converted/converted/ WAKEWORD_NAME/test/wake-word
sudo rm to_be_converted/convert_me/*.*
If sounds that do not contain a wakeword were converted
sudo mv to_be_converted/converted/ data/random
sudo rm to_be_converted/convert_me/*.*
Whether the conversion and moving worked, can be tracked under Windows. But as I said, I had problems when I created or moved files under Windows.
When the following three folders are filled, the wakeword can be trained
WAKEWORD_NAME/wake-word/
WAKEWORD_NAME/test/wake-word
data/random
EDIT: The data in data/random is important. In my training, a fairly large amount of data was needed to reduce the number of false positives in Precise’s internal training. It took 2 hours until false positive recognitions occurred only rarely. Therefore many, diverse examples are needed:
- Music
- Film
- Audio books
- Spoken words
- Noise (vacuum cleaners, pets, …)
At first you can search your own flies for such data. In addition, you can be a little creative and collect data according to your own sound background. If e.g. your pets (I have two parrots) or your own conversations cause false positive triggers, you can simply make recordings with your mobile phone or similar for some time, convert them and train precise against them.
Furthermore, I have links here with data that I have packed into data/random after conversion:
- Databases
http://downloads.tuxfamily.org/pdsounds/pdsounds_march2009.7z
http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz
https://www.soundarchive.online/vacuum-cleaner-in-operation-2-1-10060-mp3-audio-sound-free-download-noises-activity/ - Different colours of noise:
https://mc2method.org/white-noise/, https://www.audiocheck.net/testtones_whitenoise.php - Podcasts in relevant languages can help, for example
https://www.tagesschau.de/download/podcast/
I am grateful for further links to sound databases!
Simply use everything that comes your way for training. The only important thing is that the wake word will most likely not appear in the data. This can only be realized by using a wake word that is untypical for your own and the English language.
You can find the parts of the files of /data/random that trigger false positive detection (against which the wake word) shall be trained in the following folder after running precise-train-incremental mentioned below:
WAKEWORD_NAME/not-wake-word/generated
However, there are so many files that it is difficult to check all of them to see if the selected wake word does not appear in these files. More practical is therefore: unusual, improbable wake word.
Now training can be done with a few simple commands:
source .venv/bin/activate
Create Wakeword
precise-train -e 100 WAKEWORD_NAME.net WAKEWORD_NAME/
Train wakeword against false positive detection (can take some time depending on PC and data set - for me with 30 GB it took 4 h using an i7)
precise-train-incremental WAKEWORD_NAME.net WAKEWORD_NAME/
Repeat training!
precise-train -e 100 WAKEWORD_NAME.net WAKEWORD_NAME/
Test performance
precise-test WAKEWORD_NAME.net WAKEWORD_NAME/
Convert to .pb
precise-convert WAKEWORD_NAME.net
Now you can copy the two files WAKEWORD_NAME.pb and WAKEWORD_NAME.pb.params from the folder mycroft-precise to Rhasspy and look forward to Rhasspy 2.5 
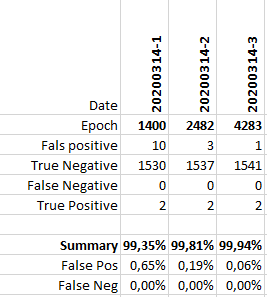
 )
)

 I’d be happy to host the training data in the Rhasspy repos, unless you’d prefer to keep it separate. I’d also be willing to run training on my home server.
I’d be happy to host the training data in the Rhasspy repos, unless you’d prefer to keep it separate. I’d also be willing to run training on my home server.