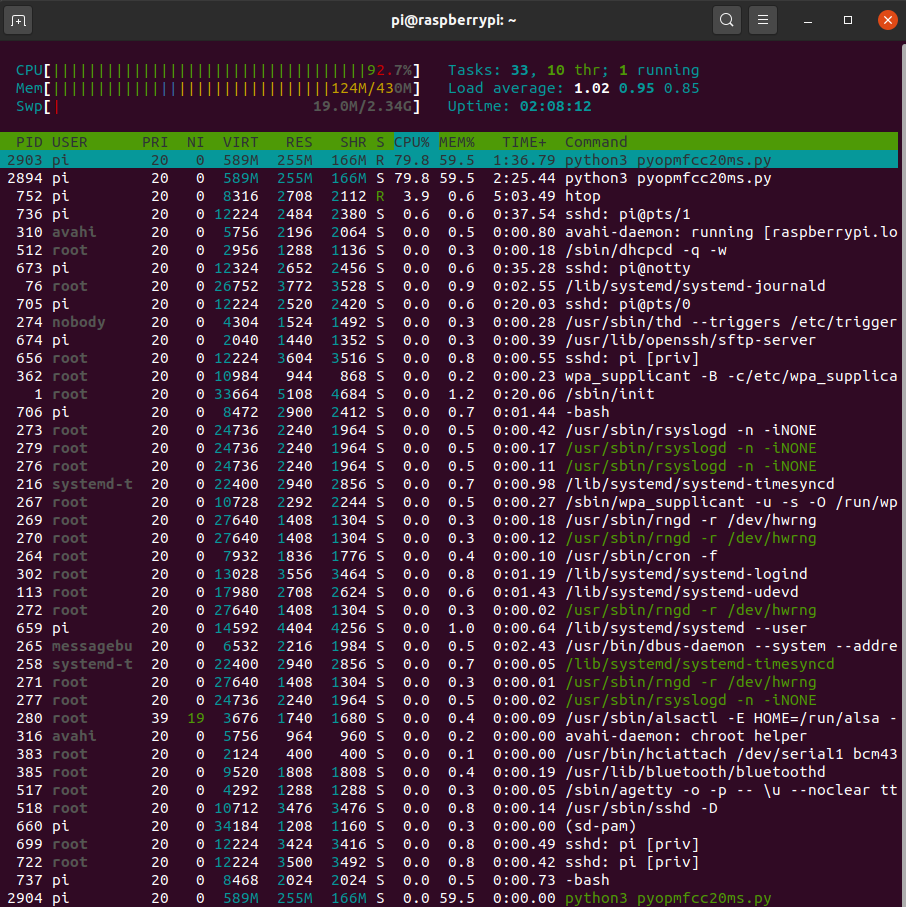
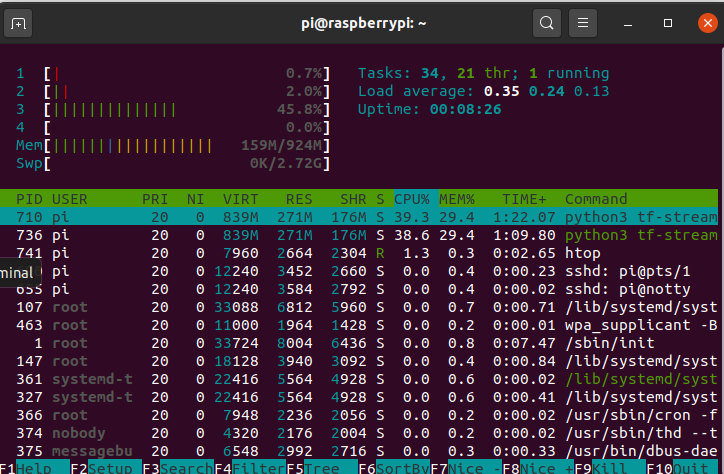
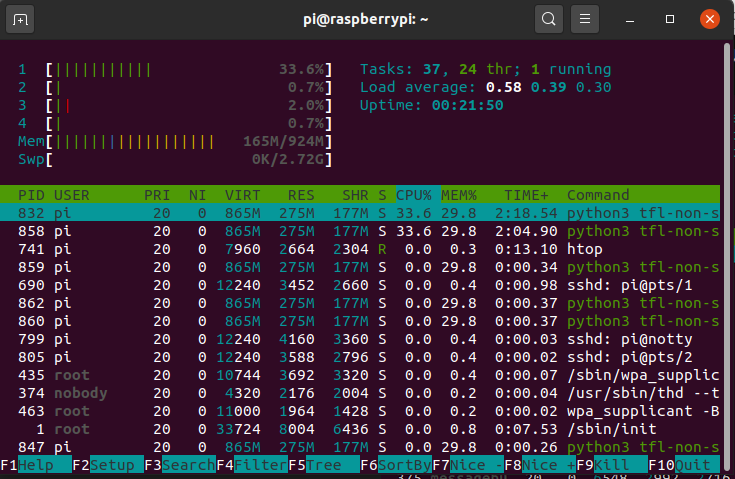
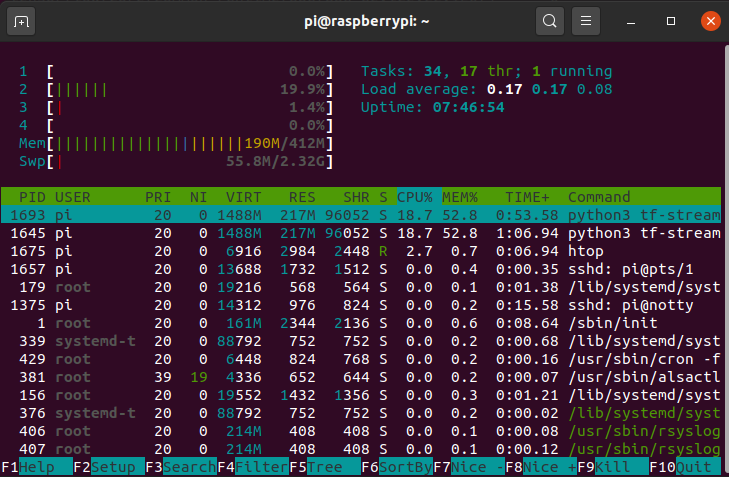
If you want to test one of the non-stream models you can try this.
import sounddevice as sd
import numpy as np
import tensorflow as tf
# Parameters
rec_duration = 0.5
sample_rate = 16000
num_channels = 1
sd.default.never_drop_input= False
sd.default.latency= ('high', 'high')
sd.default.dtype= ('float32', 'float32')
sd.default.device = 'cap1'
# Sliding window
window = np.zeros((int(rec_duration * sample_rate) * 2), np.float32)
# Load the TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="/home/pi/google-kws/tensorflow-lite/cnn/quantize_opt_for_size_tflite_non_stream/non_stream.tflite")
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
last_argmax = 0
out_max = 0
hit_tensor = []
inputs = []
for s in range(len(input_details)):
inputs.append(np.zeros(input_details[s]['shape'], dtype=np.float32))
def sd_callback(rec, frames, time, status):
global last_argmax
global out_max
global hit_tensor
global inputs
# Notify if errors
if status:
print('Error:', status)
rec = np.squeeze(rec)
# Save recording onto sliding window
window[:len(window)//2] = window[len(window)//2:]
window[len(window)//2:] = rec[:]
chunk = np.reshape(window, (1, 16000))
# Make prediction from model
interpreter.set_tensor(input_details[0]['index'], chunk)
# set input states (index 1...)
for s in range(1, len(input_details)):
interpreter.set_tensor(input_details[s]['index'], inputs[s])
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
# get output states and set it back to input states
# which will be fed in the next inference cycle
for s in range(1, len(input_details)):
# The function `get_tensor()` returns a copy of the tensor data.
# Use `tensor()` in order to get a pointer to the tensor.
inputs[s] = interpreter.get_tensor(output_details[s]['index'])
out_tflite_argmax = np.argmax(output_data)
out_max = output_data[0][out_tflite_argmax]
hit_tensor = output_data[0]
print(out_tflite_argmax, out_max, hit_tensor)
# Start streaming from microphone
with sd.InputStream(channels=num_channels,
samplerate=sample_rate,
blocksize=int(sample_rate * rec_duration),
callback=sd_callback):
while True:
pass