I recently found the DTLN project which does quite well on noise suppression and can be used on Pi. The also have a DTLN-aec but not directly usable on Pi as DTLN.
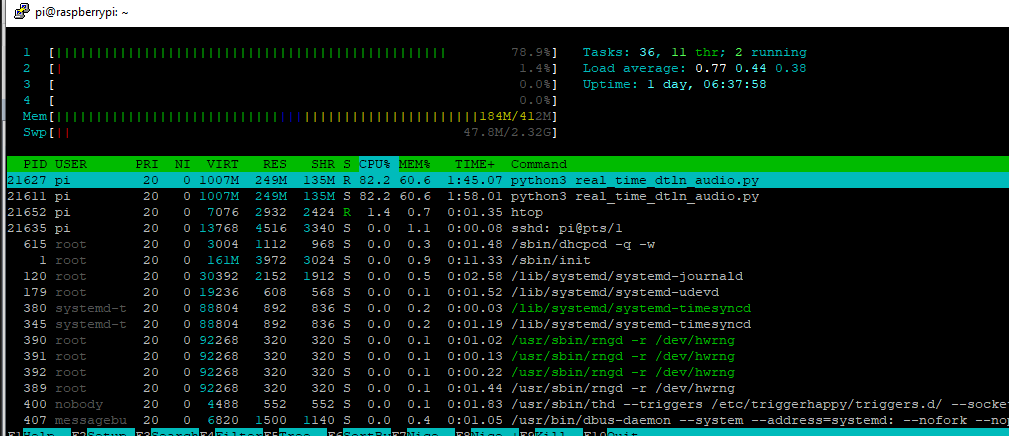
I tested the DTLN on my Pi 3B+. The quantization tflite model actually works with CPU load only around 70%. They have a real_time_dtln_audio.py which can specify an in device and out device to record while playing. I tested with very loud vacuum running and the noise it mostly removed and my voice can be heard.
Now the problem is I want to chain it after some voice cancelling (voiceengine ec) . One way is to modify the Python script and extract the denoised data, but I just want to see if I can use alsa fifo device like what ec does to make a virtual denoised mic. I modified asound.conf as below:
pcm.!default {
type asym
playback.pcm "eci"
capture.pcm "dnc"
}
pcm.dn{
type asym
playback.pcm "dno"
capture.pcm "eco"
}
pcm.eci {
type plug
slave {
format S16_LE
rate 16000
channels 1
pcm {
type file
slave.pcm null
file "/tmp/ec.input"
format "raw"
}
}
}
pcm.eco {
type plug
slave.pcm {
type fifo
infile "/tmp/ec.output"
rate 16000
format S16_LE
channels 2
}
}
# let denoise script output to this device
pcm.dno {
type plug
slave {
format S16_LE
rate 16000
channels 1
pcm {
type file
slave.pcm null
file "/tmp/dn.output"
format "raw"
}
}
}
# use this as a capture device to read denoised audio
pcm.dnc {
type plug
slave.pcm {
type fifo
infile "/tmp/dn.output"
rate 16000
format S16_LE
channels 1
}
}
It works in the sense that I can record and here denoised audio. However, the denoise program generates tons of “input underflow” message and its CPU usage stays 100%. As a result the denoised audio sounds coppy. If I run the real_time_dtln_audio.py script with plughw:0 as in and out there’s no “input underflow” and CPU usage stays around 70%.
I am new to asound.conf and not sure if I did something wrong. Maybe someone familiar with this can help, or can come up with a better solution to use the DTLN.