Google have created a repo of all state of art NN for KWS.
Really there are only 3 natural streaming KWS GRU, SVDF & CRNN but suggest a look at CRNN.
Its all google stuff but to make things easier its been extracted from the googleresearch repo and a little guide on how to install on Pi3/4 Arm64
The training and a simple KWS test tfl-stream.py is included with a simple custom dataset than the universal google command set.
I have no idea if it will detect you on your mic as its been trained for me on my mic but the example is there.
It depends on how close your voice and accent is to mine but you can look at the output it gives.
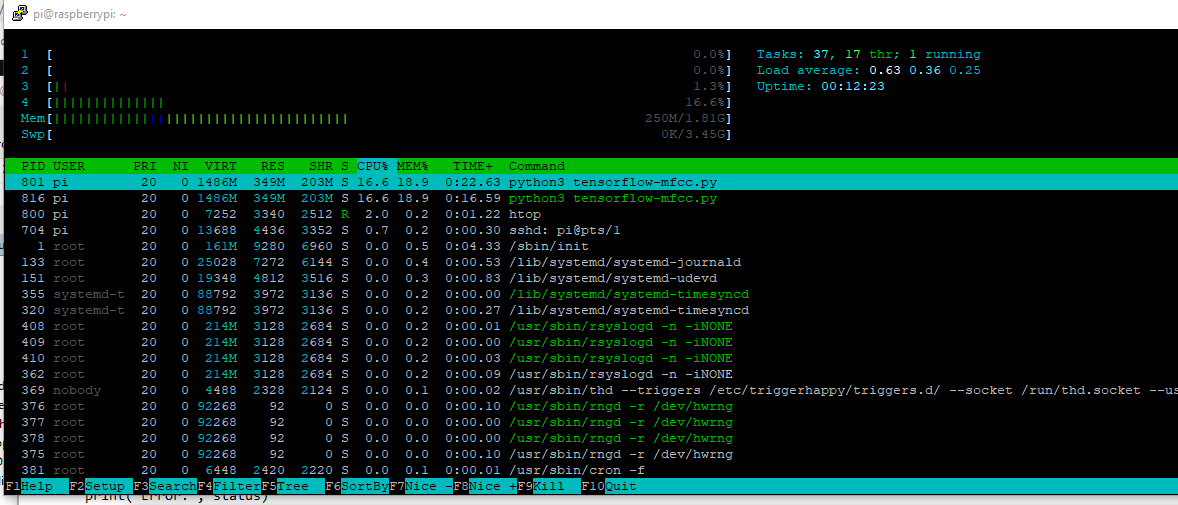
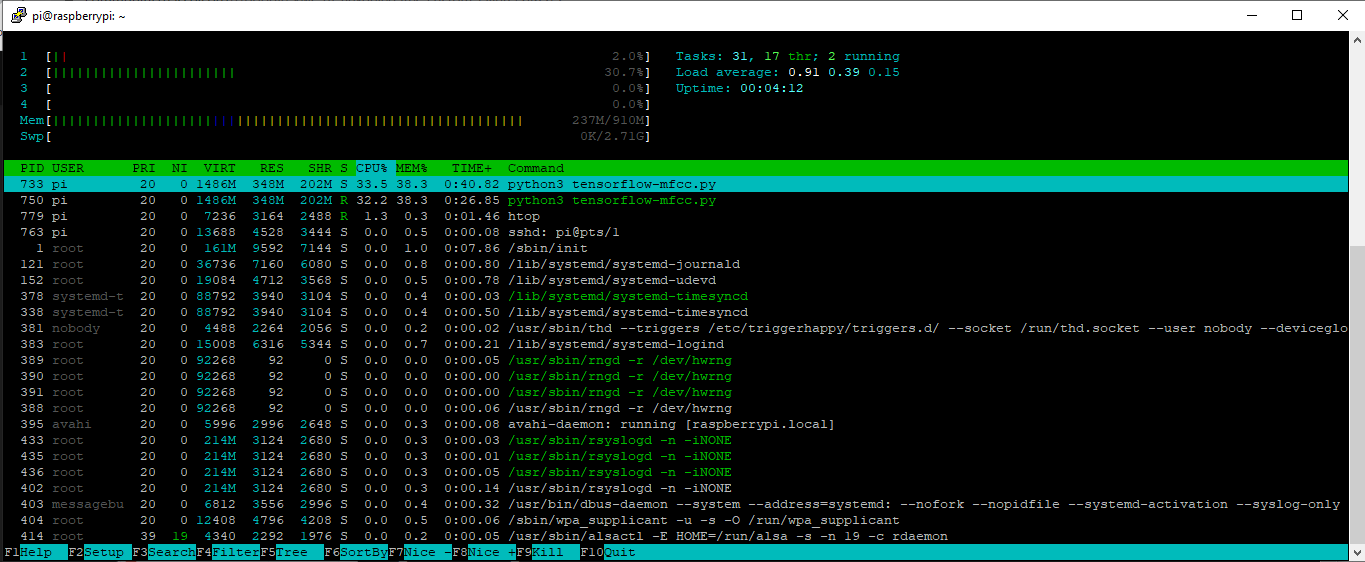
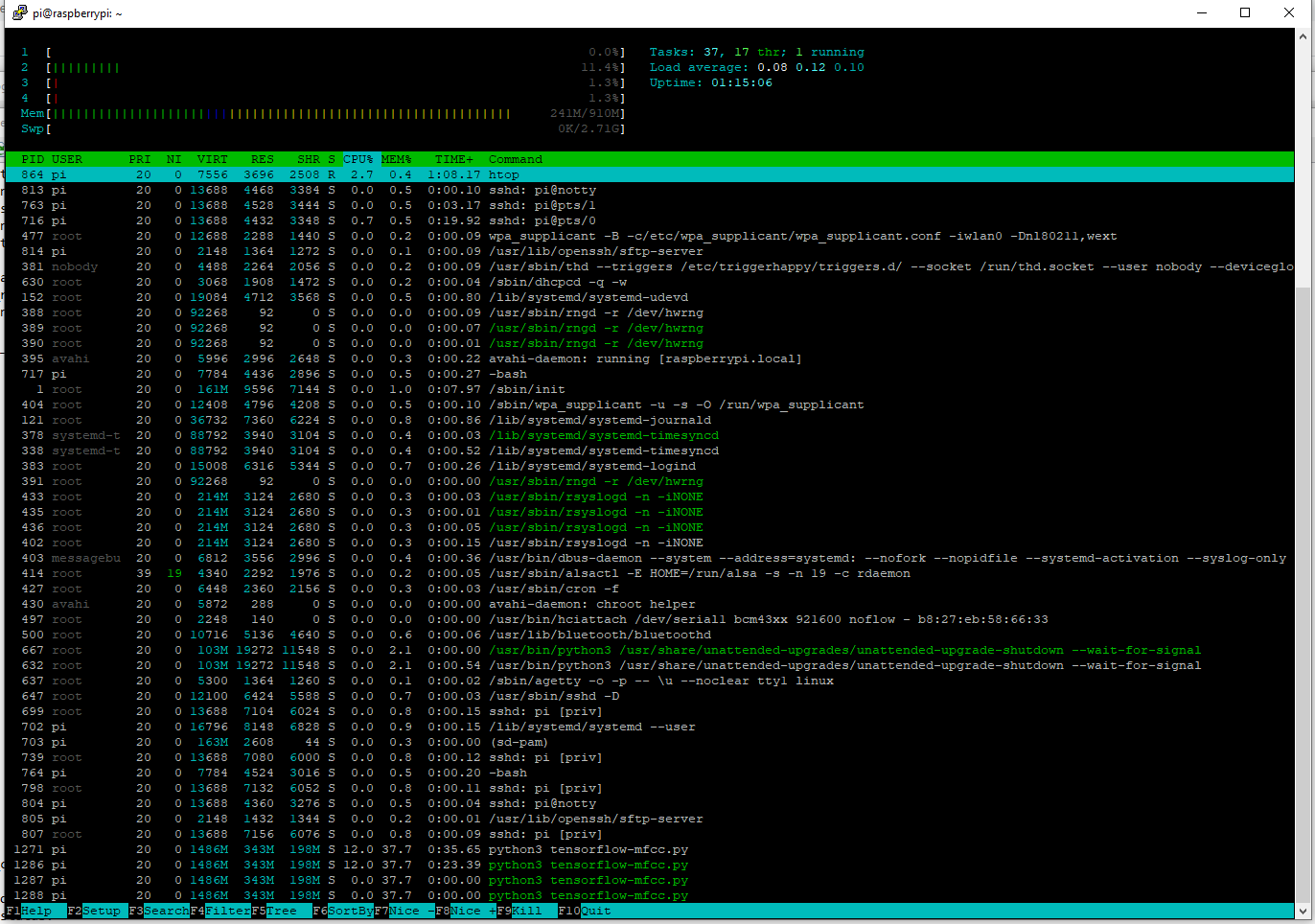
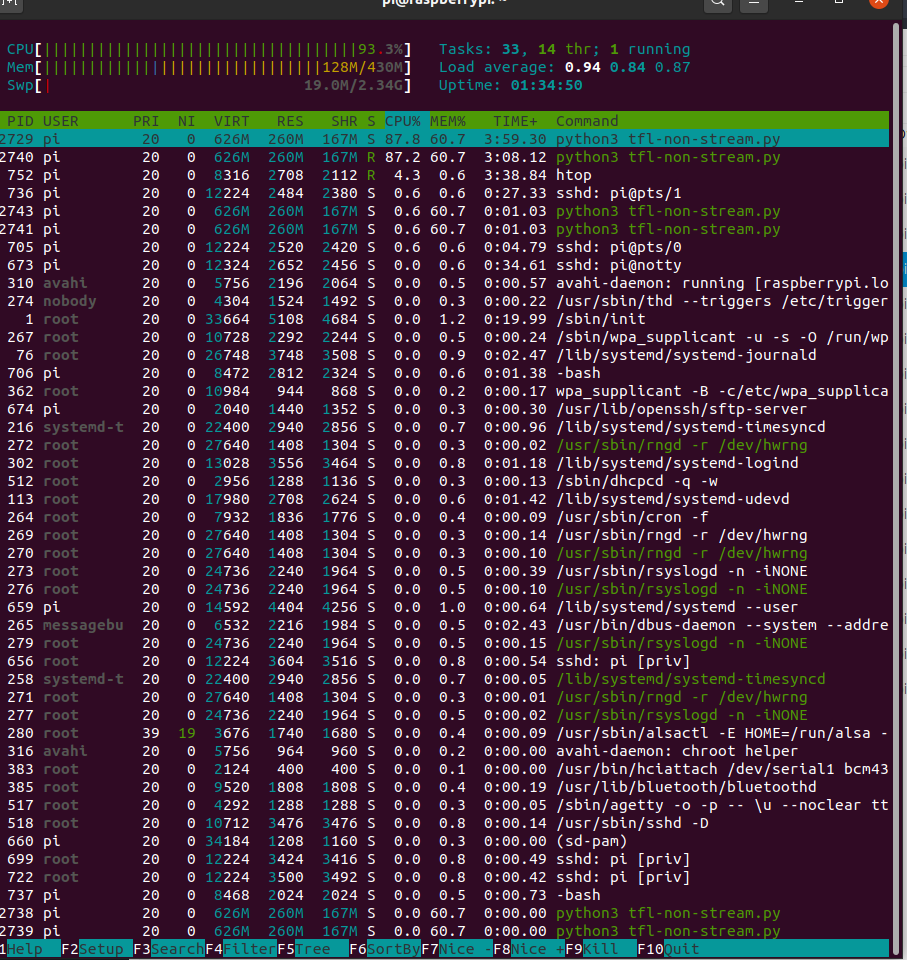
It creates a silence label so does not need vad and runs on a single core of a Pi3, which is exciting for me as finally I can run 2x instances on a Pi3 with 2x directional mics and use the best audio stream for static hardware beamforming.
Raven would be a great dataset collector for this NN but unfortunately it only collects keyword and really with a custom KW you should also provide custom !kw, but guess you could you the universal google command set items for !kw but as said your own would be much better especially for silence detection as we can do something better and detect when you are not speaking rather than silence.
Pi3b (!+) KWS running
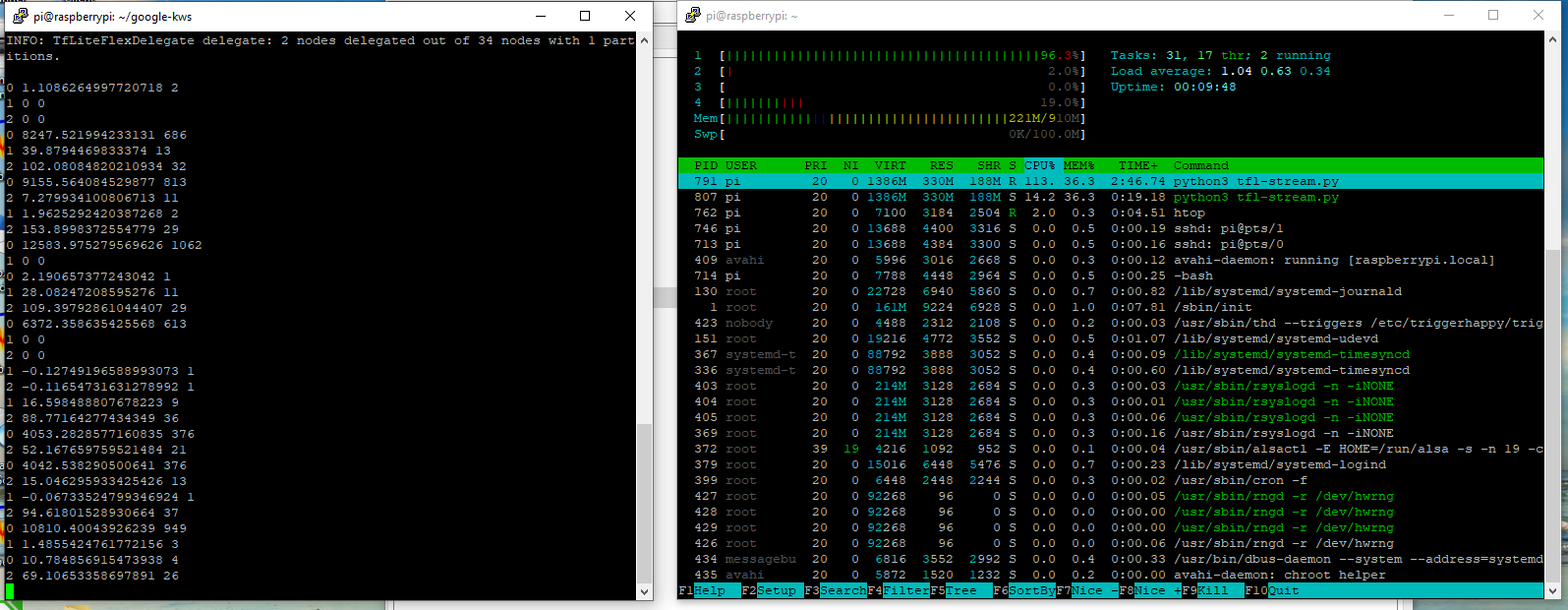
1xPi3b 2x KWS running
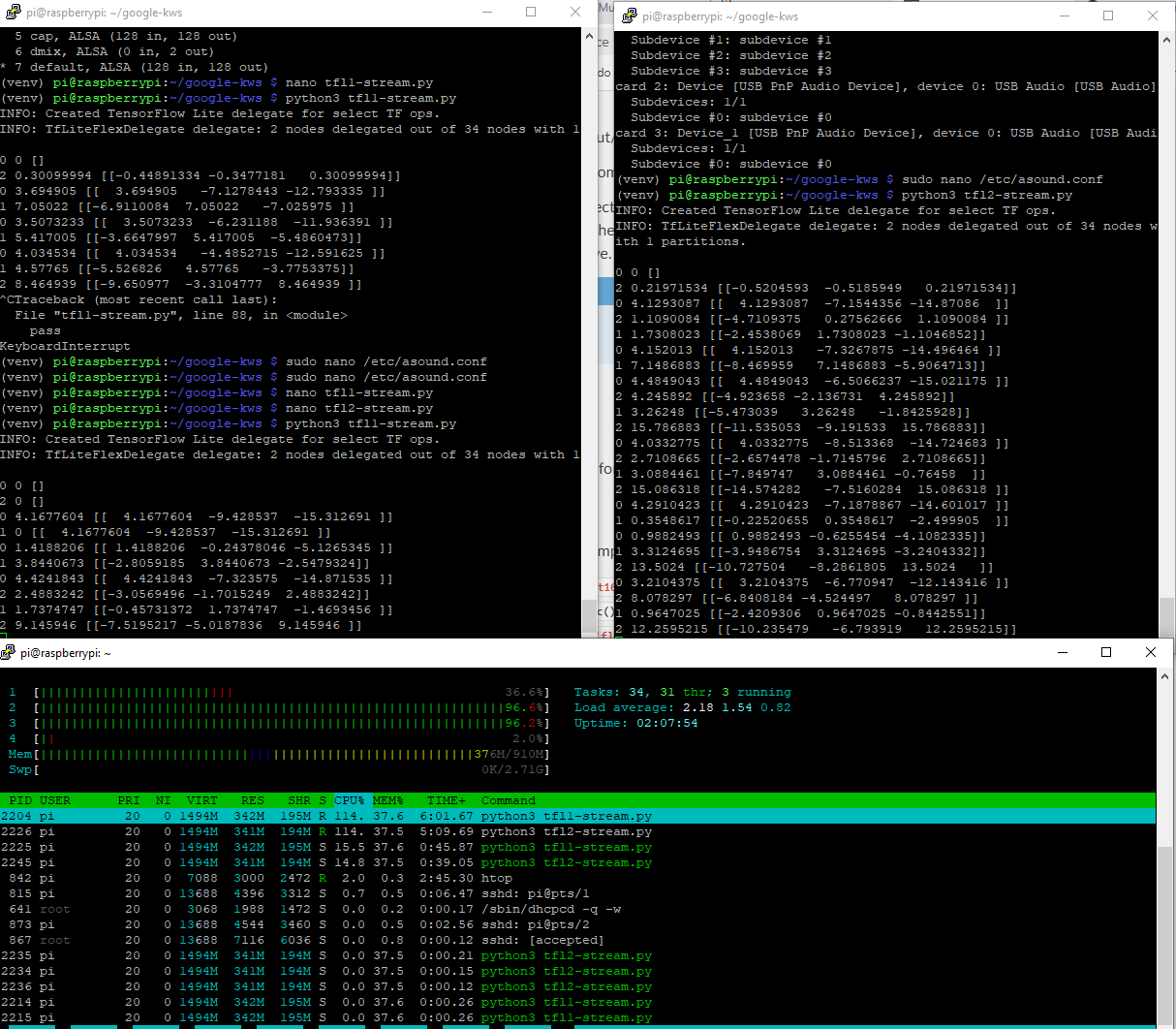
The current input is using sounddevice which creates an array frames, channels but strangely the model wants the axis swapped to 1,320.
# Load the TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="/home/pi/google-kws/models2/crnn_state/quantize_opt_for_size_tflite_stream_state_external/stream_state_external.tflite")
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
last_argmax = 0
out_max = 0
hit_tensor = []
inputs = []
for s in range(len(input_details)):
inputs.append(np.zeros(input_details[s]['shape'], dtype=np.float32))
def sd_callback(rec, frames, time, status):
global last_argmax
global out_max
global hit_tensor
global inputs
# Notify if errors
if status:
print('Error:', status)
rec = np.reshape(rec, (1, 320))
# Make prediction from model
interpreter.set_tensor(input_details[0]['index'], rec)
# set input states (index 1...)
for s in range(1, len(input_details)):
interpreter.set_tensor(input_details[s]['index'], inputs[s])
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
# get output states and set it back to input states
# which will be fed in the next inference cycle
for s in range(1, len(input_details)):
# The function `get_tensor()` returns a copy of the tensor data.
# Use `tensor()` in order to get a pointer to the tensor.
inputs[s] = interpreter.get_tensor(output_details[s]['index'])
out_tflite_argmax = np.argmax(output_data)
if last_argmax == out_tflite_argmax:
if output_data[0][out_tflite_argmax] > out_max:
out_max = output_data[0][out_tflite_argmax]
hit_tensor = output_data
else:
print(last_argmax, out_max, hit_tensor)
out_max = 0
last_argmax = out_tflite_argmax
# Start streaming from microphone
with sd.InputStream(channels=num_channels,
samplerate=sample_rate,
blocksize=int(sample_rate * rec_duration),
callback=sd_callback):
while True:
pass
The above just a pure hack by me and presume a more optimised pythonic script can be made.
But really I shouldn’t be needing to do rec = np.reshape(rec, (1, 320)) but guess the overhead is low in comparison to inference.