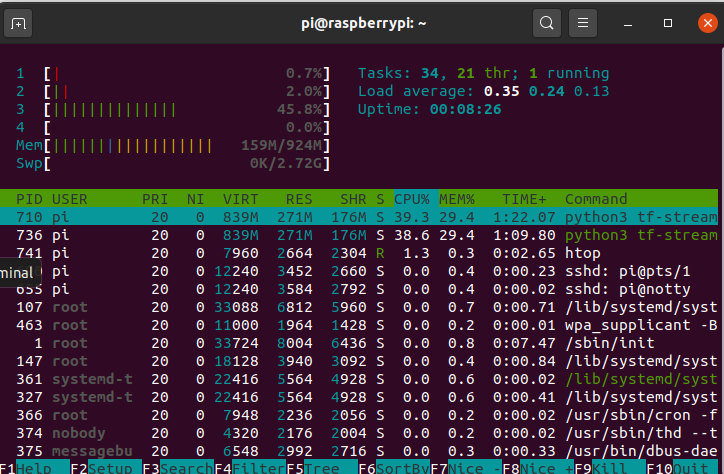
A final one as just a test on a Pi3A+ (my pick for satellite) looks about right as the + has a marginal gain on the 3b I tested earlier.
Not going to bother with the non-stream as before the load was nothing
Nice work! How’s the performance comparing to other kws like Porcupine? Can it spot keywords with background noise or other people speaking?
It seems a lot of work preparing the training samples. Can you share a pretrained model for a quick testing?
I also find this project https://github.com/Turing311/Realtime_AudioDenoise_EchoCancellation, which is based on DTLN. And there’s another DTLN-aec project. I tried it on my MacBook it seems a lot better than voiceengine ec or webrtc aec. But I haven’t been able to set it up on my Pi. Looks like the setup is similar to the google-kws you have done here, maybe you can have a try?
I will have a go just at this moment doing the automated dataset-maker which I am not really a dev or really if it gives you any timescale I was quite exceptionally good with M$ com and then they through .Net @ me.
So I am plodding through but I mangled a dataset and training with some scripts and audacity and got some extremely good results with high noise levels.
Its took me much longer to hack python into a automated dataset builder but will post something.
Its a custom dataset and its my voice really but you might find it easier than you think.
Its just prrof of concept as sure someone more tal;ented than me will make it all pythonic and wonderfull.
I will have a look at the above but there are a few apps that seem to work on X86 and other platforms but the Archv7 raspberry ports don’t seem to work that well maybe just enough clock?
PS if your up to it give this a go and give feedback.
The idea is to get a start dataset that works and then as you use to replace the original augmented dataset with actual usage capture and train when idle which gives updates over days / weeks.
I am just testing initial datasets and seeing how its going.
There is reader.py python3 reader.py that throws up words and the KW onto the CLI and records.
Set you mic up with AGC gain as high as it goes and see what you get in the rec folder.
I have a prefabed background noise folder but really this should be tailored to suit the environ but its just actual recording of your background noise.
Tensorflow 2.5 should be any time soon as we now up to RC4 for tflite the MLIR backend is default and supposedly more optimised for post quantisation which will be interesting to see if its speeded anything up.
Also intel optimisation is built in and turned on by and environment variable and no need for the intel optimised version.
There where also some training aware quantisation options that haven’t got round to see how much they affect but quite a lot of interesting stuff for TF especially embedded linux / microcontrollers.
Thanks a lot. I am downloading your model for a try first. Will use your tool for my custom dataset later if I have time to setup the training environment.
Meanwhile, I had some experiment with the DTLN. The stream noise suppression on my Pi 3B+ itself is working very nicely. However when I tried to chain it after EC it starts to behave strangely. I created a separate post (here)[DTLN Noise Suppression Setup] with details.
Tried your pretrained model. Even playing your samples of “raspberry” won’t trigger it. Seems it’s really overfitted to your voice. Will try to train with my voice later.
Easiest way is to see what you are delivery record it capturing and send the samples like I did the model via Gdrive or something.
The augmentation has a number of settings but here I am recognized no problem so likely your hardware settings and recording and comparing to the dataset will give info to way.
You can record yourself of remix with different parameters.
ython3 mix.py --help
usage: mix.py [-h] [-b BACKGROUND_DIR] [-r REC_DIR] [-R BACKGROUND_RATIO] [-d BACKGROUND_DURATION] [-p PITCH] [-t TEMPO] [-D DESTINATION] [-a ATTENUATION]
[-B BACKGROUND_PERCENT] [-T TESTING_PERCENT] [-v VALIDATION_PERCENT] [-S SILENCE_PERCENT] [-n NOTKW_PERCENT]
optional arguments:
-h, --help show this help message and exit
-b BACKGROUND_DIR, --background_dir BACKGROUND_DIR
background noise directory
-r REC_DIR, --rec_dir REC_DIR
recorded samples directory
-R BACKGROUND_RATIO, --background_ratio BACKGROUND_RATIO
background ratio to foreground
-d BACKGROUND_DURATION, --background_duration BACKGROUND_DURATION
background split duration
-p PITCH, --pitch PITCH
pitch semitones range
-t TEMPO, --tempo TEMPO
tempo percentage range
-D DESTINATION, --destination DESTINATION
destination directory
-a ATTENUATION, --attenuation ATTENUATION
random attenuation range
-B BACKGROUND_PERCENT, --background_percent BACKGROUND_PERCENT
Background noise percentage
-T TESTING_PERCENT, --testing_percent TESTING_PERCENT
dataset testing percent
-v VALIDATION_PERCENT, --validation_percent VALIDATION_PERCENT
dataset validation percentage
-S SILENCE_PERCENT, --silence_percent SILENCE_PERCENT
dataset silence percentage
-n NOTKW_PERCENT, --notkw_percent NOTKW_PERCENT
dataset notkw percentage
Not sure but until I can have a look at your recorded stream can not really say.
It was very hot of the press and have been tweaking some of the defaults and at a very boring stage of doing that and seeing how it affects to gauge some settings.
Might of been not enough attenuation in that 1st model and we have a lot of difference in mic input but post.
I need to pull the latest Google-kws as also they made some changes but here I am using the CRNN tflite quantised model but you can run any model from the dataset.
There are some sample inference code in the g-kws repo tfl-stream.py and the threshold is hardcoded currently but that is where I will likely move next after some tidying of the dataset-builder.
I wasted a couple of days trying to find an alternative to Sox and then realise use /tmp with sox and just create what I want with silence detect in stages.
So it got derailed and rewrote and is still very hot off the press haven’t really done much testing myself.
2hrs old so the dataset_builder can wait as going to have a play with the new version.
Dunno the later models might be better but if you ever get the time send a dataset and model of your own as that will be loads of info and have much to work with.
This is the problem when your one and it works for you.
The pitch does seem to me different maybe the proximity affect of the cardioid of record to one now in use but couldnt say that model was one of not the first.
Just tried your latest model and it’s a lot better. Even with my voice it can hit your default kw threshold sometimes.
The previous one didn’t even trigger the output in kw_count > 3.
Interestingly, playing your samples from my laptop didn’t work as well as me speaking. Maybe the speaker changes some characteristics of the audio?
Also, when I have my vacuum working it can detect nothing. So I guess background noise matters in training set really matters.
Its volume then as I actually reduced pitch as thought some sounded ‘mickey mouse’ and likely out of any norm.
Interesting as didn’t lower much and can go further I just need to play with the params but hopefully it wasn’t noise as another goal is to introduce noise to the max and make it as noise resilient as possible as with KW that should be much easier than ASR and from KW at least you can ‘duck’ playing volumes if not urban noise.
If I am reading right a I5 6600K CPU 32 ms frame executes in 2.08 ms which might mean its possible as x15 still leaves some scope. Whoops still talking AEC.
PS did you try a 64bit version of RaspiOS as maybe ?
Really should switch but for some reason it still fails with a error on custom datasets.
Just remark part of line 260 out so its looks like this for dir_name in dirs: #+ [du.BACKGROUND_NOISE_DIR_NAME]
There is an error if you use TF2.5 but 2.4.1 works fine
Also you should be able to record your own dataset and copy and paste over mine and train and we should have a 2 person custom dataset that is likely to lose some indvidual accuracy but also be a bit more universal and should continue that way with each additional voice actor.
I tried to use your dataset builder to record my kw & !kw. Now the problem is that mix.py always gives “too many samples are oversize” (or undersize). Is it okay to just change the 1.25/0.75 ratio in the code?
Don’t been having a huge brainfart but the NS/AEC was a good diversion and went back to the original g-kws.
In Google-kws the default for silence & notkw is 10% and finally I clicked where I had taken a detour and all my improvements where slowly making false positives worse.
I will load up what I have just been doing as gone back to scratch and should not try to improve things and leave that to someone with more talent than I.
Mix-b.py is a restart as had to make a 2nd take and build up to see where I was going wrong.
Basically you want to ‘overfit’ kw as much as possible and ‘underfit’ silence & notkw so they have higher hit probability.
The --overfit-ratio reduces the settings of KW with pitch & temp of !kw so that the data is more varied in !kw as well as only 10% in the dataset so its ‘more’ ‘underfitted’ and hence accepts more.
Conversly kw has far more items in the dataset with less variance and so is ‘more’ ‘overfitted’ to stop false positives.
The 0.75 default if prob quite high so lower to tighten the variance of KW.
I have been using a cardioid and get really good results with noise but omnidirectional just bleed in equally so much less tolerant to dB noise in.
Without beamforming I find el cheapo cardioid mic & usb soundcard (generalplus chipset) much better than any omnidirectional hat.
If the generalplus chipset the agc is pretty great on the above.
I knocked out the attenuation ranges and do very little with the silence category but need to add back and not further break like I did before.
The mix-b.py works! It has been running quite a while (~1.5hrs) and is still running. It would be great if it supports parallel processing so I can put it to some multi-core server for faster mixing.
I am also curious if g-kws can support training with multiple custom kw?
Yeah it can its just my dataset-builder that builds as such but in reality there are 3 classifications silence, notkw and kw which equally could of been multiple custom.
My idea was to use Raven as that has a really simple alg that capture kw as reader.py and getting initial samples grows on each addition.
With mix-b.py its likely that further resilience to false positives could be by adding notkw from the Google command set but have tried not to include and 3rd party single language dataset.
I have tried to keep to own voice for kw & notkw, silence I have posted a selection of background_noise files that are universal. Actual background_noise can only increase this.
With the cardioid mic I get an element of natural beamforming and resilience to noise is much higher and why I am desperate to find a steerable beamformer and DOA where the result expectations can be quite low as even with the relatively low attenuation of a cardioid mic when you sum with a noise resilient kws the overall sum is seems to be exponential in result.
I picked the CRNN because it has only the GRU is delegated out but is a natural streaming model with only slightly more Ops than a CNN that seems to provide decent accuracy levels.
In the framework though and model from basic CNN to att_mh_rnn could be used and to be honest we are only talking a couple of % in overall accuracy.
A CRNN is basically the GRU of the Precise model but with a post CNN layer section that greatly reduces GRU parameter processing with the delegates the GRU layer is delegated so that TFlite can be used for the majority of processing, then add quantization, Aarch64 the accuracy and load just completely blow precise out of the water, whilst on accuracy its just a little more accurate than GRU alone.