This made a huge difference in speed, rather than computing the cosine distances as needed inside the DTW for loops
One area where the Zero still as problems is when there’s a lot of audio that activates the VAD but doesn’t match a template. This gets buffered and processed, but can clog it up for a few seconds as the DTW calculations run.
A way to help might be to say if so many frames in a row have very low DTW probabilities (< 0.2) that audio is dropped for a little while. Any thoughts on this? Maybe it will be moot once the DTW calculations are externalized.
Thinking about it 45% isn’t all that bad on a Pi Zero as its just short of horsepower.
Acoustic EC on the Pi3 is really heavy but actually doesn’t matter at all because of the diversification of process.
It only runs heavy when audio is playing, doesn’t run on input and TTS is generally the end result of process.
So it doesn’t matter as it runs at alternative timeslots to other heavy process and diversifies load.
How much load does RhasspySilence produce on its own on a zero as isn’t VAD just the summation of a couple of successive frames of the same FFT frame routine that is duplicated in MFCC creation?
You can actually see the spectra in a MFCC so surely you can grab the spectra bins of the low and high pass filter that VAD uses from MFCC instead of WebRtcVad and log the sum there and do away with RhasspySilence at least on a Zero?
Then use diversification and turn off MFCC/VAD after silence until the audio capture is processed.
You don’t have to halt after silence but I am pretty sure the single frame MFCC calculation could make an excellent successive VAD detection with hardly any more load than MFCC itself.
What is the load of RhasspySilence or is it pretty minimal anyway?
Also again from the above it seems like MFCC is batched and searched after whilst like VAD should be frame by frame?
As if your DTW probabilities don’t fit for X series of frames then doesn’t DTW restart again on the current frame?
With webrtcvad I was seeing maybe a millisecond to process a 30 ms chunk of audio.
I’m betting there’s some savings that could be had by combining the VAD, MFCC, and DTW steps. MFCC/DTW are done on “template-sized” chunks of audio (the average length of your wake word), whereas webrtcvad mandates 10, 20, 30 ms chunks.
Some ways I could think to save CPU:
Use VAD to decide whether a whole template-sized chunk is worth processing
I wait to process audio until VAD says there’s speech, but if the majority of a template-sized chunk is silence I will still process it (MFCC/DTW)
Re-use FFT from VAD in MFCC calculation
Would work well if they’re processing the same chunk size
Abort DTW calculation early if it can’t reach threshold
Not sure if this is possible, but I would guess you could tell at some point in DTW that the final distance can’t ever get above threshold. In that case, abort the rest of the calculation.
Dunno as the FIR filters which are just FFT routines of webrtc are all contained in WebRTCAudioProcessing and as individual FFT routines you don’t have api access just the results.
@fastjack was testing actual FFT libs for MFCC so sounds like at that point you do have access to the FFT routines and they are not just submerged in some lib.
You mean use the FFT frame for both MFCC frame and VAD calculation and drop webrtcvad?
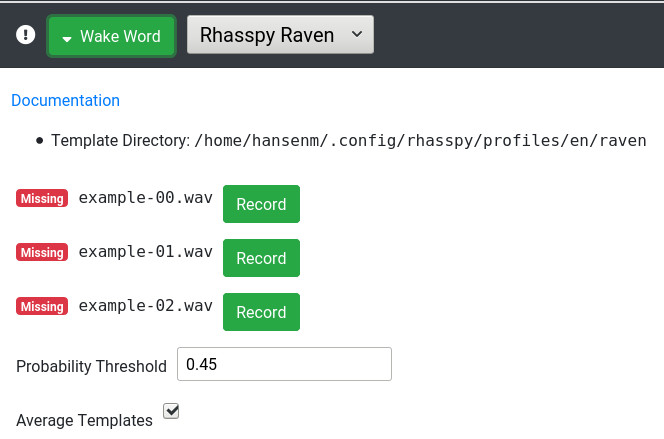
I added a place in the web UI to record the examples:
You click “Record” next to each example and speak it. Right now, the web UI doesn’t support multiple wake words but this is absolutely possible in Raven
Per @fastjack’s suggesting, I’m also working on the ability for Raven to save any positive detections to WAV files so you can train another system like Precise down the road.
Looking at Raven WAV templates dir, it seems there is no way to have a keyword use multiple templates (for later averaging per keyword). Averaging templates from different speakers will result in very poor accuracy.
As this is “personal” wake words, it would be nice to have the ability to setup multiple keywords (one for each family member) with multiple templates each (reducing calculation by averaging templates per keyword).
Yeah its always been the same prob due to KWS always using an external VAD but on each frame the data the FFT frame provides can be used for the MFCC frame and VAD frame.
But yeah 2x FFT runs because VAD & MFCC are usually separate projects/libs not sure why KWS don’t have a VAD function that does.
@fastjack Could you do a sort of feature extraction with VAD that looks for a tonal quality and then switch to a family member?
I think the way to do this in Raven would be to just have multiple keywords, one for each family member. Assuming MFCCs retain some information about tone, this should allow you to differentiate who spoke the command.
This is why I think a specific C++ library should be made to do all this directly in an optimized fashion (Audiochunk->VAD->Preemphasis->windowing->MFCCs).
Another C++ library can eventually help with the templates DTW comparison.
The wakeword is the main CPU bottleneck for a vocal assistant project (satellite). The rest easily run on a Pi 4.
PS just to name drop https://github.com/JuliaDSP/MFCC.jl#pre-set-feature-extraction-applications once more as I am not a Python programmer or any language any more, I do want to ask if some of the guys will take a look as supposed the interfacing between Python and Julia is supposedly quite straight forward.
Also julia for python experts is also supposedly more native whilst challenging C optimization speeds.
Also the Julia guys themselves wrote those libs are they are promoting what Julia could, can do and the author might be a very good contact to know.
@rolyan_trauts this looks like a perfect starting point for a native all-in-one system. I was able to piece together Raven thanks to the Snips article and @fastjack’s implementation, but I don’t know if I could create an all-in-one system in any reasonable amount of time from “scratch”.
I looked at the diarization part of feacalc a bit. So it extracts 13 MFCC features and does some normalization. Could this be calculated for the Raven templates, and then again once the wake word is detected, to do speaker recognition? DTW could be used again (probably without windowing), and the smallest cosine between all “diarization” templates would hint at who was speaking.
Yeah think so that it could select Raven templates might need to do a KWS failure once to switch Raven Profiles (not sure how long it needs to run for accuracy, but a single KWS failure to then switch isn’t that bad a proposition to accuracy gained, as only fails once when switch is needed)
but yeah multi-user templates could be a thing without load increase as raven would be switching profiles rather than trying to process profiles in parallel.
Has quite a few uses from maybe even voice biometrics and security.
It can also do the same for ASR that ASR can also switch profiles (models) based on diarization.
Say swap between 2 models such as gender to gain accuracy.
I like the idea of going native aka Rhasspy Rover but really that is all that is needed is Raven and RTP audio & control.
Its quite possible to have multiple simple satelites of the Simple Rover layout and use the result sensitivity to mix audio and deselect bad input from a distributed satellite array or just use best satellite single input signal, which a simple local KWS recognition can very much attain as that can be RTP info from each satellite to an ASR/Intent server that accompanies a stream.
In fact it can be just a asound channel mix as the KWS failures don’t initiate a stream.
MFCC+DTW already does speaker identification as the template is speaker specific.
That’s why I wrote above about multiple keywords (each with multiple templates) so each family member can provide multiple templates for the same keyword.
With this, Raven will be able to detect which person (keyword) has uttered the wakeword (even if it is the same for everyone).
I’ve tested with everyone in the household and it works flawlessly
Yeah but what we where talking is that your MFFC+VAD+DTW are all separate libs and multiples of load whilst they might not have to be.
If you are running against multiple keywords and multiple profiles then surely that is multiples of load also?
So if you can do diarization via VAD to select current profile at least then its only the multiples of keywords if you have them.
Also if you use the Julia Lib Vad+MFCC FFT use are off the same load and that is why the Julia Lib was forwarded so webrtcvad could be dropped from the load.
The diarization of JuliaMFCC is just another bonus that Julia lib has that could be used to cut load.
I’m quite satisfy at the moment, but now in Production with lot of current conversation around, I have a few false positive and increase sensibility step by step. would hit the point where sensitivity is too high.
Actually I use Minimum Matches 1 and VAD sensitivity 1 (average checked)
Does Minimum Matches to 2 provide good result ? Does it allow to decrease sensitivity with still good detection and low false positive ? What about cpu charge ?
Anyone sharing experience regarding these settings would help I will have to get some Pis for testing setup but right now, just got production setup, can’t break it