Development has slowed down a bit lately, but don’t worry: Rhasspy is alive and well!
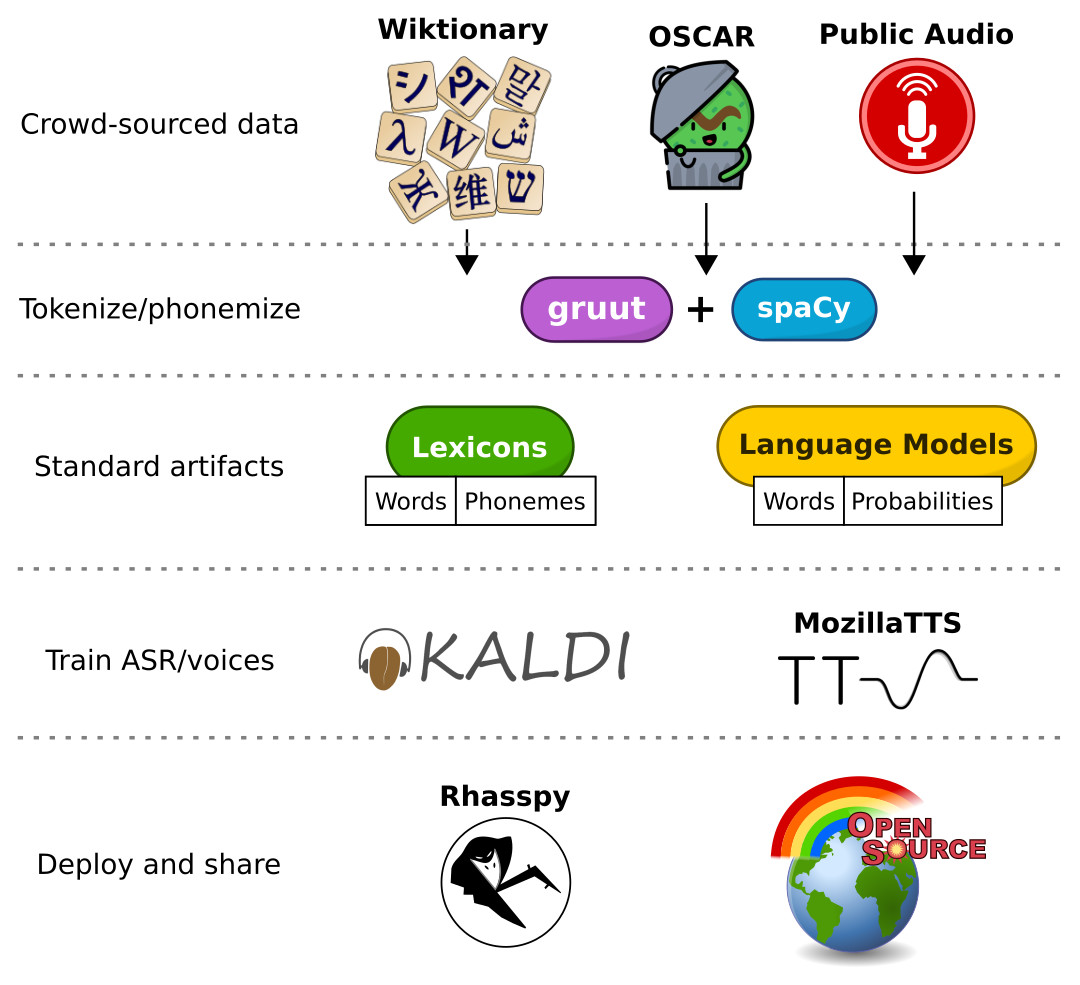
I’ve been learning more about computational linguistics, and formulating a broad Master Plan™ for Rhasspy’s future. At the heart of this is a simple truth: open source voice assistant projects (like Rhasspy) end up being model scavengers. We wait patiently for others to produce or update our speech/language models. Most of these models cannot be reproduced by the community because the data and training methods are not made public.
I believe we’ve reached a point in time where closed models and data are no longer necessary for open source voice assistants. Going forward, I’d like transition Rhasspy to using speech/language models trained entirely from public data using open source software. My ideas are based on what Zamia Speech did years ago for English and German, but generalized to work for many more languages.
In short, the plan is to:
- Use Wiktionary and the international phonetic alphabet (IPA) for pronunciation dictionaries
- Get text data from the OSCAR corpus and tokenize it with spaCy
- Download all available public speech data to train new Kaldi models
- Work with volunteers to record new public speech datasets for training text to speech voices using MozillaTTS
Importantly, this gives just about anyone a way to contribute! Add new words to Wiktionary, record yourself for Common Voice, or volunteer to help us train a voice for your language. Contributions will benefit Rhasspy as well as many other open source projects.
I describe some of the new projects I’m working on to support this effort below. No matter how it turns out, it’ll be an interesting journey:

gruut
A new soon-to-be-released project for the Master Plan is named “gruut” (pronounced /ɡruːt/). This project will clean up text and lookup/guess phonemic word pronunciations for all of Rhasspy’s supported languages. Its tasks include:
- Tokenizing text into words with spaCy
- Expanding numbers into words using babel and num2words
- Looking up IPA pronunciations from downloaded Wiktionary lexicons or guessing them with pre-trained phonetisaurus models
- Converting pronunciations to espeak-ng format for verification
- Ensuring word pronunciations fit within a given language’s phonological inventory (phonemes)
- These same phonemes will be used to train Kaldi speech models and MozillaTTS voices
ipa2kaldi
Training new speech models will involve a second new project whose job is to generate a Kaldi nnet3 recipe for each language using gruut. Transcribed audio from public speech data will have transcriptions cleaned with gruut. Word pronunciations will be looked up or guessed using gruut as well, and the Kaldi recipe’s phonemes will match accordingly.
This same approach could also be used to train a new Pocketsphinx or DeepSpeech. I’ll be focusing on Kaldi initially, but the goal will be to support additional speech to text systems in time.
ipa-tts
The last new project is a fork of MozillaTTS that uses gruut instead of phonemizer for word pronunciations. There are a few reasons for this:
- TTS models can be made smaller and trained faster by using a small set of language-specific phonemes
- Multiple pronunciations for the same word can be supported (think “I will read” and “I had read” in English)
- Text cleaning, number to word expansions, and pronunciation guessing is all handled by
gruut
This last reason is important for supporting many different languages. ips-tts can be greatly simplified because it can delegate text pre-processing to gruut and just focus on IPA. A side benefit is that you automatically get a text to speech voice that can directly speak phonetic pronunciations in IPA!
New Voices
In order to create new text to speech voices, we will need people reading sentences (also called prompts) with good microphones. The sentences they read are important, since they must provide enough examples of the different sounds present in a given language. A good set of sentences is “phonetically rich” if it covers a large number of a language’s possible sounds.
An additional feature of ipa-tts (or a sub-project) will be to help generate small sets of phonetically rich sentences that still do a good job of covering a language’s sounds (technically, pairs of sounds called diphones). The set should be as small as possible so a volunteer isn’t burdened too much. Ideally, the sentences should also be pleasant to read, which is why public domain books are often mined. I’m planning to use sentences from the OSCAR corpus, however, because public domain books tend to be quite old and may use words or phrases differently than a modern speaker (see: language drift).
Feedback
Let me know what you think. Thanks for reading!




 ).
).