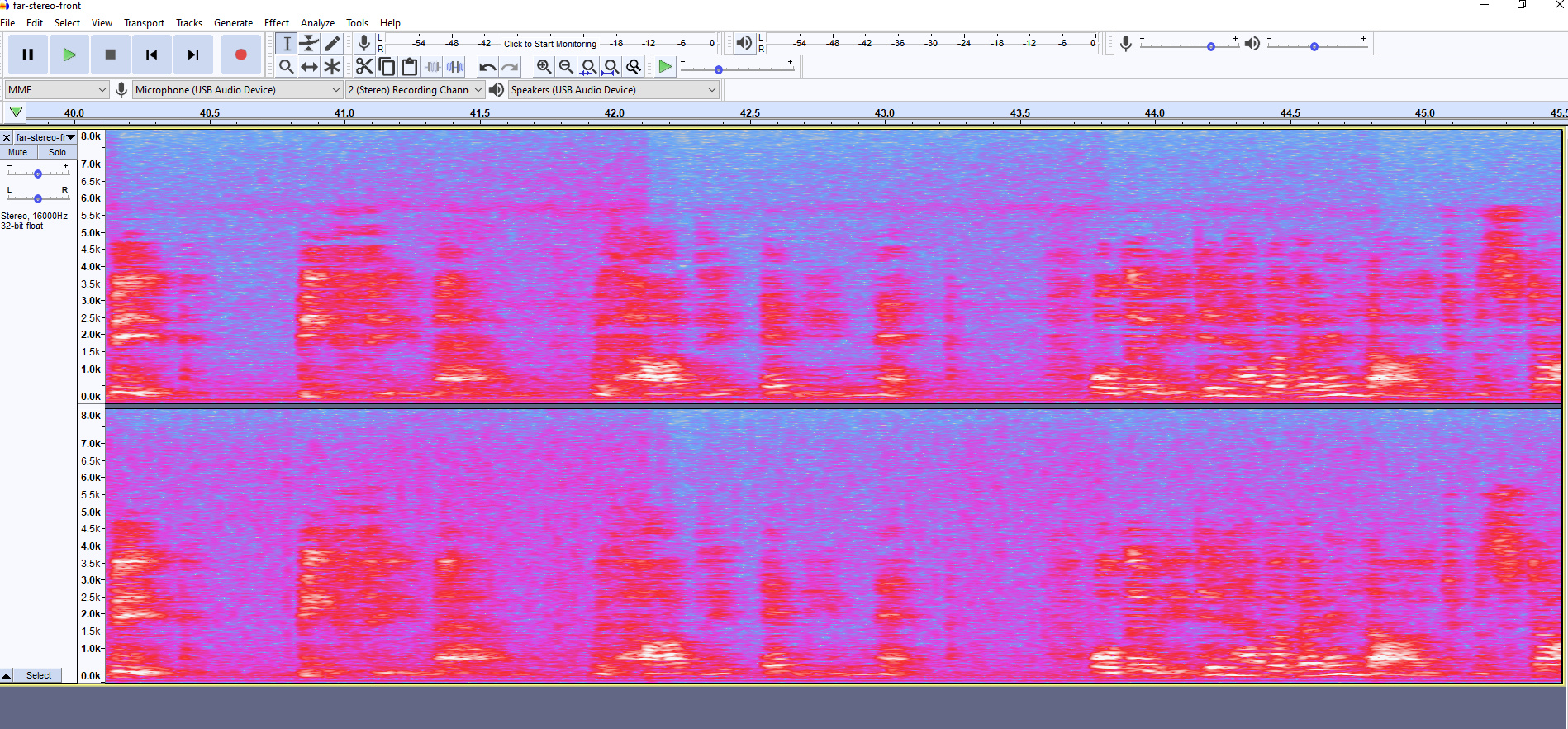
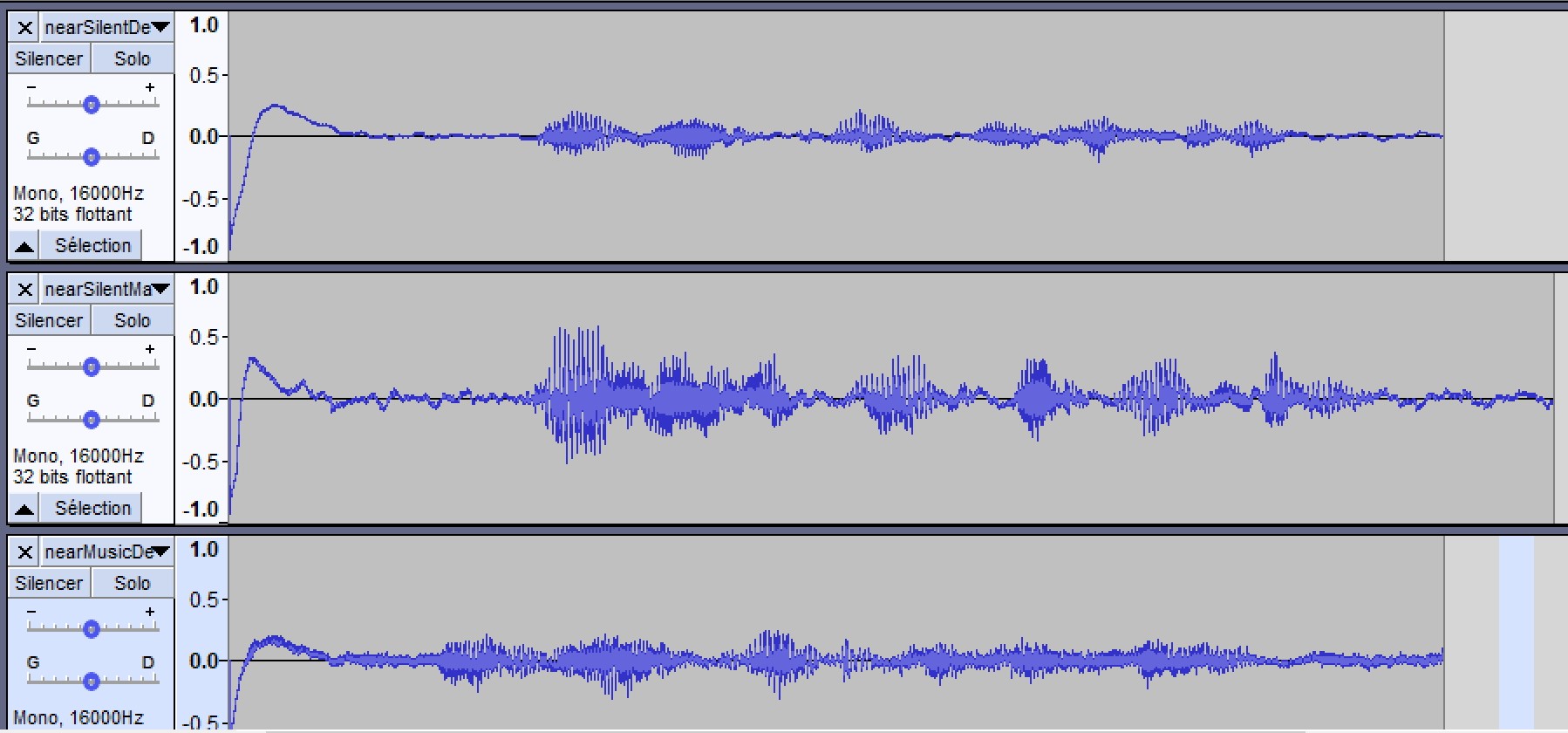
Here is another set of test recordings for you to look at and import into audacity @rolyan_trauts :
This is 4 recordings. Each one is me reading the first paragrapgh of the hobbit.
Near is less than 1m distance to 2 mics pi hat and far is 3.5 meters distance.
There is one with and one without background music for each.
Background music is normal tv level 4.5 meters from the mic.
This is the Respeaker 2 mics hat stock installation alsa mixer settings of capture gain 31 and alc target 20. No recording effects applied and the room is about 35 square meters big.
I really can’t know if such mic would help, no experience in this field. Also, I understand echo cancellation comes from the DSP having the music input to invert it and cancel it, which will never be the case for me (hifi amp).
Example right now ;
I’m sitting beside Triangle Antal playing normal music level, at 5 meters from snips (rpi3 + respeaker 2 mic).
I call snips, bip, ‘shutdown the music’, boum… no more music.
Actually I can’t get even near such result with rhasspy on exact same hardware. So before paying such advanced mic (which I can), with no mic experience and audio knowledge, I’m not sure the problem comes from the mic when I see what snips can achieve with this hardware, being totally usable day to day as of a living with it.
I will definitely test gain / ALC settings and record in such environment. As snips was selling dev kit with pi hat, maybe they have tweak a lot their algo for such hardware. Dunno. @fastjack also mentioned the khaldi versus vad detection.
Here are my mic.
You can see the last one behind with the black mic (all other parts exact same).
I use a custom precise model I trained myself on 100+ samples from both my girlfriend and me with and without background noise. It’s trained against about 20 hours of pieces of random noise. This gave me a pretty noise resistant responsive keyword model.
When it comes to recording the command after a wake Word was spotted as I use voice2json I have set up the command recoding differently to what Rhasspy does with vad.
I use sox with a combination of silence detection and a max record length of 5 seconds as I found that no command takes me longer than that. So it records either until silence or for max 5 seconds and than sends the recorded audio to the voice2json Kaldi stt component if silence was detected or not. (I also use sox vad on the audio After rec before stt to trim the end and the beginning for non speech).
I found this approach quite robust.
I have talked to @synesthesiam before about doing something similar for voice2json and maybe Rhasspy.
For example adding an option to send the audio even if a time out was reached instead of erroring. This would allow to effectively do the same I do with sox and configure a short timeout and if no end of speech was detected when the timeout was reached try the best stt wise with what was recorded.
Agree about the timeout. I also suggested to have a max duration settings as yes I rarely speak command more than 5 or 7 seconds. And the yes it should try to recognise this instead of error.
Talking about snips it does stop listening when I stop talking, with near same level music.
Maybe your solution should be implemented into rhasspy for everyone.
Yes that’s the Kaldi endpoint strategy. It stops not when you stop talking but when the stt thinks it understood a sensible command from the language model as the the stt happens streaming while you speak. So it doesn’t need silence to stop.
Voice2json actually does something like this already but I don’t use it for robustness reasons.
Record with arecord position yourself how you wish to control rhasspy with your music or whatever and post on here.
Do what I do and just paste it to google drive.
But as far as I am concerned with current Rhasspy setup if you are sat by a speaker playing music and you are trying to control Rhasspy you haven’t a chance because of a total lack of any audio processing.
I never used Snips but it sounds like they must of had some form of audio processing to enable that.
Kibo did you play the music through snips or just have the hifi on as if playing from rhasppy we can do something about that.
It’s much more than that. They had a whole team working on this. They optimized every part of the pipeline probably doing audio pre processing as @rolyan_trauts proposed. Having custom language and acoustic models and so on. Sonos didn’t pay for nothing. They were a talented bunch.
Sure, but when I see all things rhasspy do better, it’s frustrating to not be able to use it due to this problem. Even if I understand this problem is not a small one.
Its a strange one as the bit Rhasspy seems to fail on is the input audio processing with a total lack of.
Its a bit of a disaster as in terms of recognition and computers the phrase is ‘garbage in, garbage out’.
Speech recognition is actually image recognition and whilst you have Audacity out switch to spectrogram mode as speech recognition just uses MFCC’s which are just fancy spectrographs where KWS looks for a match of the spectrogram of your keyword.
ASR looks for individual phonemes and is backed by a dictionary and has some idea of sentence sense so it tries to get the most plausible return on a sentence.
If you have audio coming in of a level then the spectrograms of keyword and phonemes will be just lost in a jumble of noise.
We have the race track, the stadium but for some reason we are missing the starting blocks and until something is sorted we are not going to win this race.
PS I never used Snips and have no idea how clever or what it was capable and Sonos may of purchased Snips but there products use Alexa or Google.
Snips may of just been a multiword KWS as Keywords and a KWS are far more resilient to noise than ASR but I have no idea, my introduction was Mycroft and that suffers the same.
Snips was based on something quite similar to raven for custom hotwords and their own universal model for hey snips.
Their asr/stt was actually based on kaldi same as we are using in Rhasspy or Voice2json but they were using a few features Rhasspy isn’t yet.
If the above is true then the only thing true about Snips is that you have no idea how it worked.
There is a fundamental huge gaping hole in your knowledge of how snips worked where you might know how later parts worked but are missing key elements of importance.
As the above is fantastically good and without any algs for audio processing its an absolute lack of knowledge on display this had anything to do with custom hotwords or Kaldi as the audio processing nessacary to give true results by the nature of audio physics comes before.
What’s the point of you’re message ? If true ? You mean if I’m not lying ? And I don’t think I have hide the fact that my expertise isn’t in audio.
I use snips for two years now with three custom wakeword and lot of intents, all family use it several time daily. So yes I know how we can use it and in which situation it works or not.
I am not saying your lying at all but a bad attempt at copying snips without obviously knowing is why you are getting the results you do.
There is no audio processing and that is why your results are so bad.
Your 2 mic respeaker is completely absent of any of the methods they employ.
I don’t like the respeaker mic array v2 as dependent on the volume of the speaker you are sat next to, it still is dependent on the predominant noise at the mic and can quickly start to create a synthetic ‘vocode’ effect.
Yes they are a lot better than the mic you have but there is still an argument distributed mics to a single processor will always be better.
Ps here is a reply from James Hughes (raspberry) if you know who that is.
Demand for HQ audio products on Pi. Very High. Demand for DSP to do beamforming calculations, 3.