I did a lot of testing with different hardware and wakewords. All results are too unsatisfying to use Rhasspy in “production”. Although it seems, some of you are able to use it.
What’s irritating at most is the difference between the old Snips-hotword and Rhasspy on the same hardware. When using Snips on a Raspberry Zero and a Respeaker 2Mic-Hat I can call the wakeword from ~3m away. When using Rhasspy with exactly the same hardware and audio configuration (disabled Snips, enabled Rhasspy), I have to sit in front of the mic and speak into the direction of the microphones.
Doesn’t matter, if Rhasspy is installed via Docker, virtual environment or the debian package.
For testing purposes I use the Docker image on my Windows PC and my Logitech webcam as microphone. Here I can call the wakeword from the other side of my apartment and everything is working fine. The same webcam connected to the Raspberry is exactly as bad as using the Respeaker Hat.
Tried Raspberry Zero, 2B, 4 with the Respeaker 2Mics-Hat, a Respeaker 6Mics Hat, a Respeaker USB Mic Array, a Logitech C930e webcam and a PSEye. Used Raven and Snowboy as wakeword while testing. Nothing is working as expected.
I have always been critical and slightly bemused to why this has not been addressed as Raven or Snowboy are not exactly the best KW systems.
Likely Porcupine & Precise are better and that Porcupine is the best if you can not train Precise.
I never did try Snips but you don’t seem to be alone in your findings but without the code or previous Snips experience I am blind.
If you pick a platform and I am not a fan of trying to use a Zero due to load, your mic and KWS we could try and see what audio rhasspy is receiving by simply recording some samples.
I have always presumed Snips normalised audio input but how some say it worked with noise is a mystery to me.
Also maybe give a thumbs up here as better KW for porcupine in the current situation will just help.
I have a hunch that is you run noise reduction on your dataset say rnnoise then you can use rnnoise to help also and much has been about bad models and implementation, poor mic config, lack of processing but for some reason a complete lack of community focus to the problem and generally ignoring it?!? I dunno why.
That will do can you go onto the container and arecord -Dmymic -r16000 -fS16_LE rec_test.wav and post to a drive somewhere.
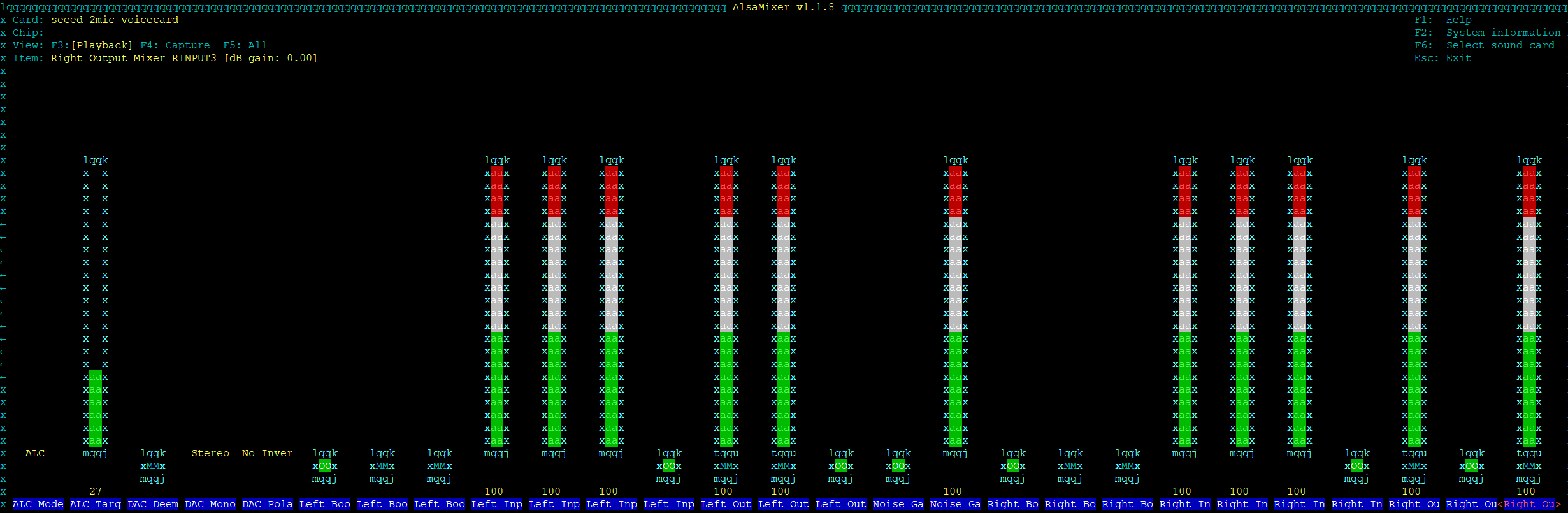
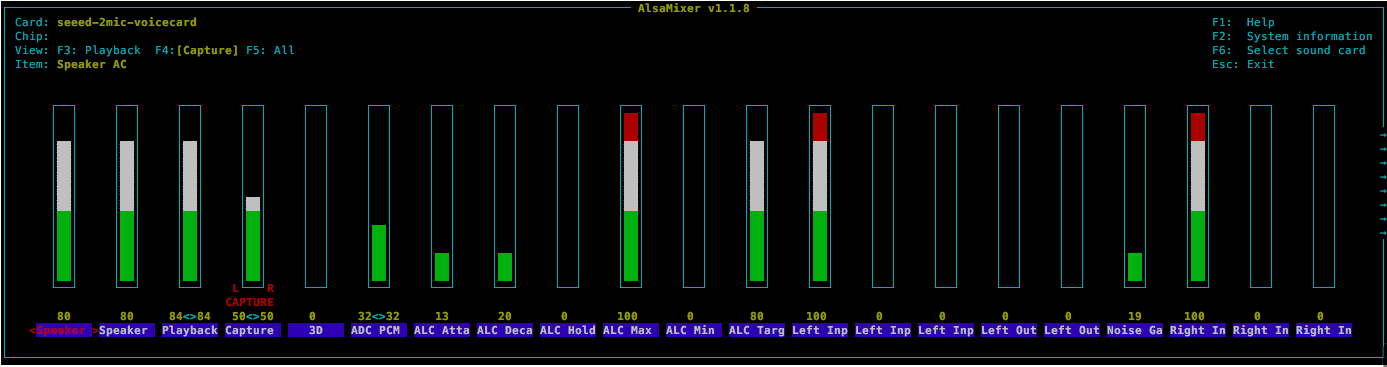
Also amixer -c1 contents
“c1” is the card index of ‘mymic’
You will have to do a aplay -l to list and you may have to stop the rhasspy service to get access to the card.
With help from audio experts like @rolyan_trauts and others, I’m hoping that we can get to this level of performance for wake words (and for speech recognition with music playing).
I don’t know the reason for the difference; I’m not audio expert, so I’m probably being naive by just recording audio at 16Khz, 16-bit mono in fixed-sized buffers and passing that right into the wake word system. Maybe other systems record differently or do some kind of pre-processing?
From my basic understanding, the variables I see are:
Don’t you out me as a pert as in the modern world we all know experts are bad!
It could well be docker syndrome and that what is happening in the container isn’t what people are thinking on the host.
I have a pet gripe with the ability to cope with noise and that yeah maybe if compiled models on processed datasets and fed processed audio we might get much better results than clean audio datasets and trying to feed clean audio.
Also my gripe is that we haven’t created easy tools to create models apart from some fiddly scripts.
Then the myth that a mic array alone is some way better when actually it can create a whole load of audio filters depending on how they are summed and the distance apart.
Arrays with DSP algs work fine as its the algs that correct and beamform but without often a single mic is likely better.
Anyone can be an “expert” now with a little “research” on YouTube, right?
The snowboy wake word creator I posted yesterday is a step towards that. My plan is to repurpose the front-end for a GPU-based training system. Now that I’ve successfully got nvidia-docker to work, it just might be possible to have a single image that can record examples and re-train using CUDA.
Here are the samples: https://cloud.drhirn.com/index.php/s/wAbGeH5TpDcQc3D
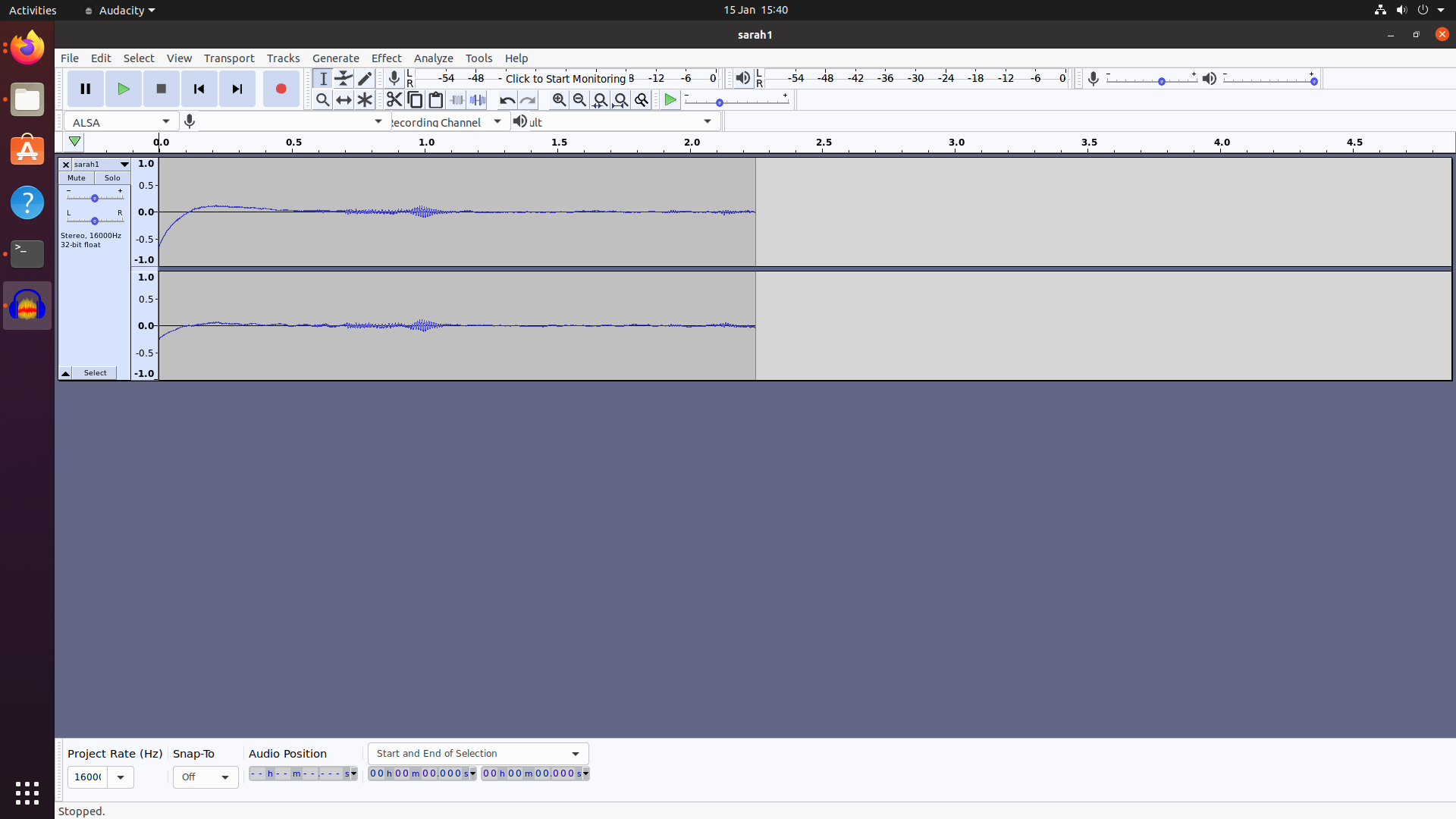
Recorded with arecord --device "hw:2,0" -r16000 -fS16_LE sarah1.wav -c 2 while sitting exactly the same way as if talking to rhasspy.
Output of amixer contents is also there.
Btw., I’m actually testing with the debian package, not Docker.
And no, I’m sorry, no Snips code here. But I could provide an sd-card image.
With KWS I don’t actually think CUDA is a need as yeah its a lot faster but Keras CPU models are not hours to compile.
You are right about Youtube as thank god now I can spot Illuminati @ 20 paces.
The alsa state directories /var/lib/alsa/ maybe should be shared from the host as part of docker run?
If you could take an image then please do as really interested to take a look.
Try setting up your ALC with you soundcard as from audacity your levels are really low.
Might fix your woes but see what @JGKK says for volumes & alc
Audacity is a really good tool as if you select your wav without the start click and then go effects ‘amplify’ before you do it tells you what gain is needed to get to 0db and currently 18db which is pretty huge!
Its Ok yesterday I spent ages trying to get into the car with my front door key.
It only occured to me why the neighbor was so angry when I remembered I don’t have a car.




{kind=link}