One test I found helpful at the start of using rhasspy to see what rhasspy was actually getting. Was to
choose raven.
Record your wake word then listen to each one.
Firstly you can see if it’s a microphone problem.
A sound server problem.
or a recognition problem.
Raven false triggers a bit but as it’s more closely tied to your own voice and wake word it does trigger so it’s a great point to start.
Because of my accent I had trouble witjh the other more generalised wake word solutions.
This is my 2nd problem. Until now I couldn’t get the playback to work (see Playback doesn't work).
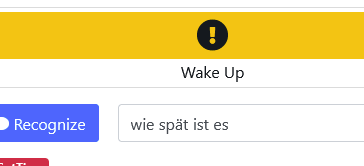
I click the yellow wakeup button and spoke “wie spät ist es?” into the microphone. And is is written then into the textbox:
Or I’m completely wrong and this isn’t really recognised. But If i use arecord I can record a sample from my remote compute (where the micro is connected).
press the record button
record your wakeword
press the play button next to it and see if you can hear it clearly.
then you know what you recorded is actually recorded and if it’s clear and can be played back.
My setup is quite specific to my setup and wouldn’t help here.
I presume you are getting a response when you trigger it manually. (on the home page). If that’s not happening then the problems not the wakeword.
Sorry @romkabouter I didn’t notice it was your reply. I’m an idiot.
if you watch the logs
ie tail -f /var/log/syslog
you will see output when the wakeword is recognised
like
[DEBUG:2021-08-22 21:43:26,841] rhasspydialogue_hermes: ← HotwordDetected(model_id=‘default’…
also if you have mosquitto clients installed you could watch the audio going over the mqtt bus with
mosquitto_sub -h localhost -t rhasspy/audioServer/#
if you don’t have udp enabled on the audio all the sound picked up by rhasspy goes on that topic
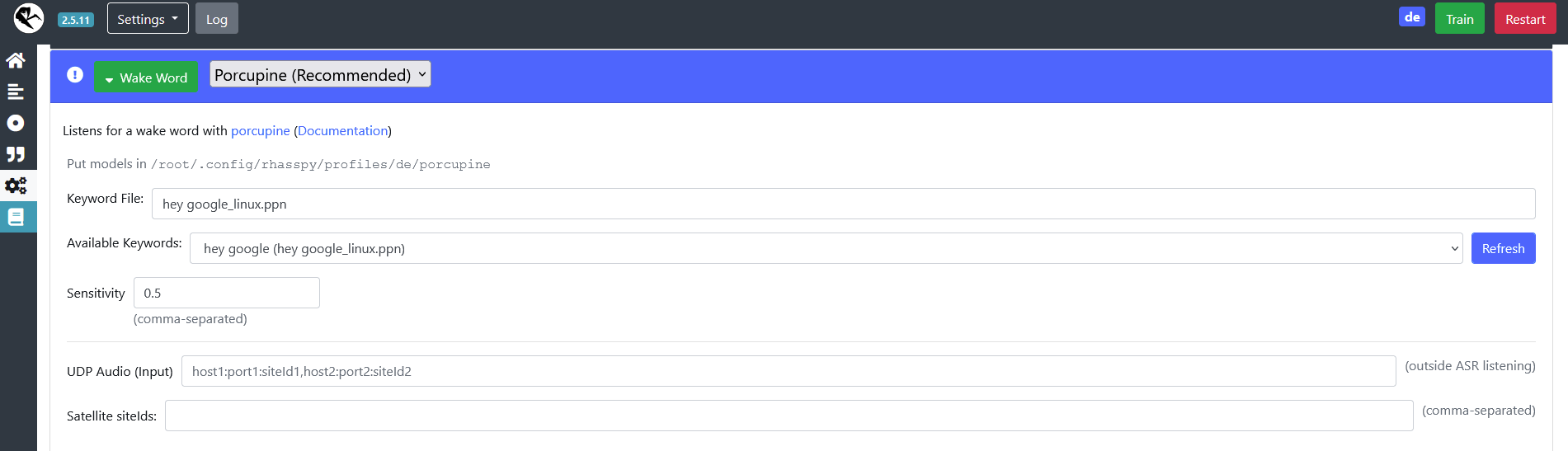
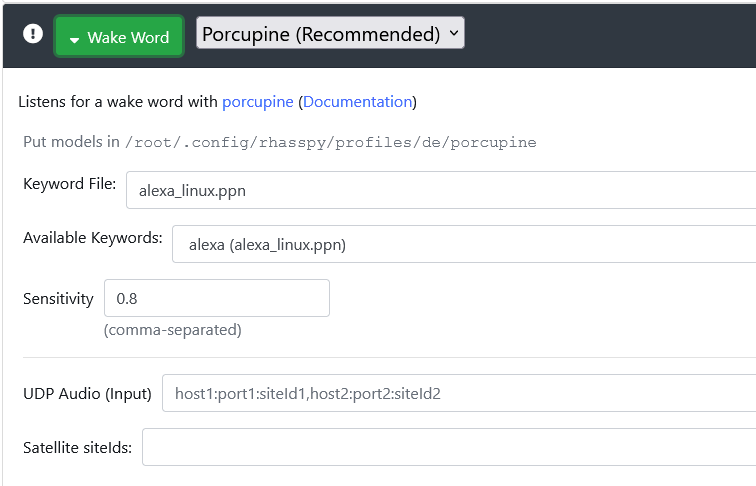
I connected to the log over websocket. But no luck. Seems that rhasspy simply doesn’t listen or doesn’t react. I’ve now setup porcupine. Do I have to do some manual training? There is sadly 0,0 reaction…
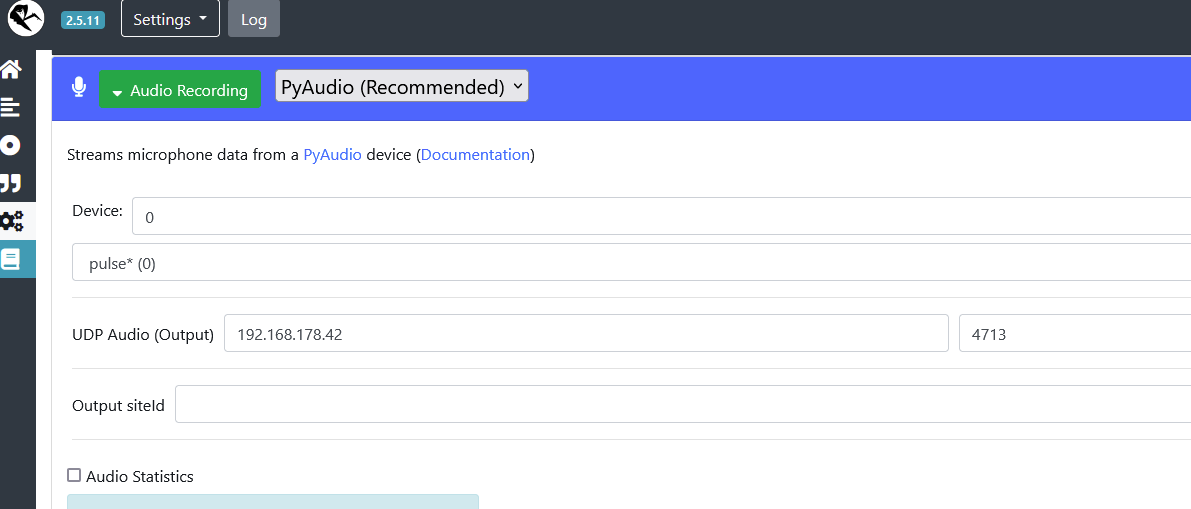
These are my seetings… So I have to setup UDP in this case? I was thinking that pyaudio / pulse audio are indpendent from rhasspy. It should always work. Doesn’t porcupine use the pyaudio interface?
Is 0.1 a high sensitivity? Oder is 0.9 a high sensitivity? And what I have to speak into to mic is “hey google?”. Is there an optical feedback in the gui?
Perhaps some of the developers can say something? We are celebration a guessing hour, aren’t we?
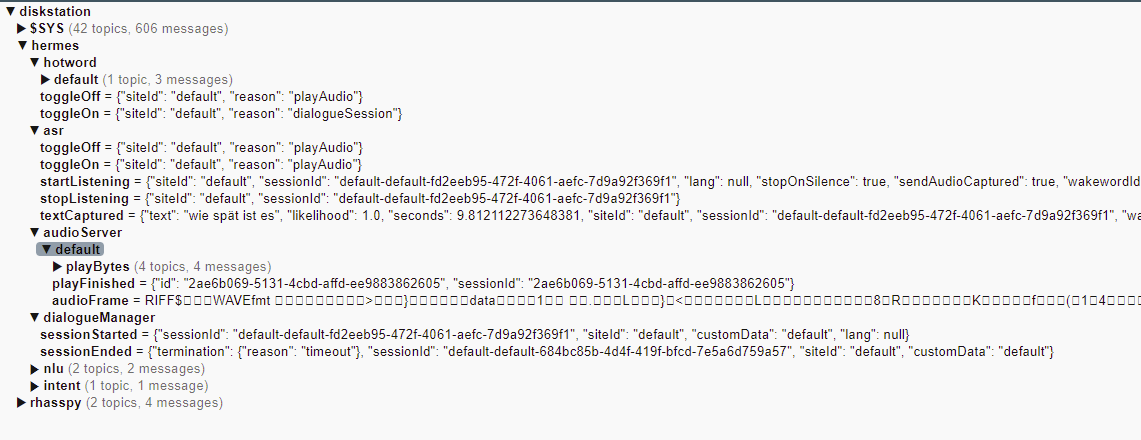
Can you subscribe to your mqtt broker and see if messages are flowing to hermes/audioServer/#
There should be a lot of them, the audioFrames topic ( a subtopic) shouild receive those.
I think you will see messages, because you say the recognition works. Which implies correct workings of the audio recording
Do you still have the UDP settings on pyadio? Might be best to remove them for now