Hi,
Following this I would like to know what you guys use for your custom wakeword with rhasspy.
I have done my custom wakeword two times with snowboy. Whatever I try for audio_gain (less or greater than 1) and sensitivity, I can’t it to work reliable. If I don’t want many false positive, I can’t wake anymore when needed. Actually I’m using audio_gain 0.6 and sensitivity 0.38, yesterday was looking a movie in the same room and every 5 mins got a false positive.
Comparing with snips it’s just horrible. What is even worse, is that with snips, when there is a false positive (it happens every few days (not few minutes !!)), snips doesn’t recognize an intent. Here, rhasspy always recognize an intent, even with high confidence. So every few minutes I had the weather for tomorrow … Totally unusable like this, can’t even test to put it in a living room with family talking around.
I use a rpi4 buster lite, respeaker 2mic pihat (same hardware with snips). Did recorded the waves files on the pi, uploaded them on snowboy website and generated the pmdl file with default settings. (tried also to record from a surface pro directly on snowboy site).
I absolutely need three custom wakewords (one per family member, as I filter some intent on who is asking).
Porcupine seems a better solution, but seems we have to re generate wakeword files every 30 days even for private personnal use. So not really a solution.
snips wakeword works really great, was easy to generate samples for each wakeword and generate the wakewords, process was entirely offline, so I don’t know if rhasspy could use it.
Anyway, I would really listen what other users use for custom wakeword, how you did generate them, and how it works. And why it works … 
Actually, rhasspy is an amazing solution, all works really nice with easy setup, and with coming full hermes and base/sat setup it will be a beast. But without a reliable wakeword detection, it’s just unusable.
With snips, I had to edit each sample in audacity to cut leading and trailing noise, made a big difference. Didn’t do that for snowboy, I will retry to record new samples and make them as clean as possible before generating the wakeword. But every experience will be wellcome 
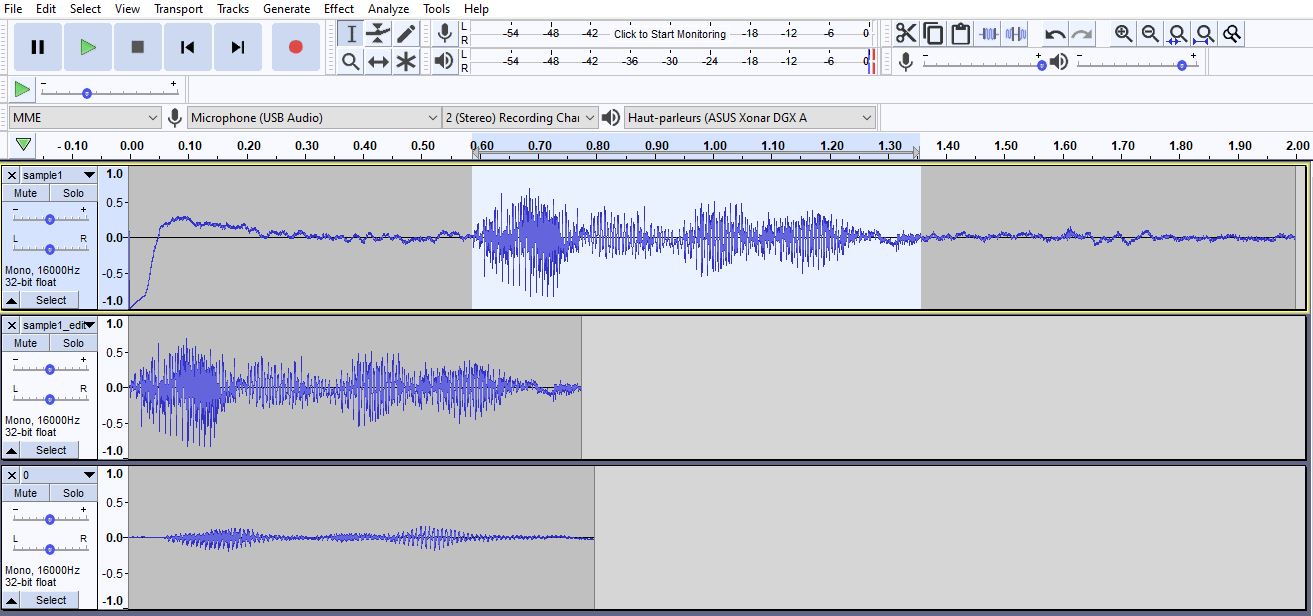





 So that would make double false positive
So that would make double false positive 