I successfully set up my first satellite and it is working fine so far. However, when I have my Node-Red flow running, I pass the spoken confirmation to the master via a text to speech node. Then the master say something like “Switched on the kitchen light”. But I would like to get the confirmation on the satellite I issued the command on, how is ths possible?
Okay, I found it out already. I set the dialogue management on the rhasspy satellite to rhasspy and in Node-RED I read the siteId and route it to the satellite tts url with a switch node.
Is it intended like that? Problem is I get the output four times now
Update: It seems that when I enter an intent on the satellite and recognize it, the Node-Red webhook recieves two inputs: one from the satellite and a second one originating from the master. Any idea why that happens?
To be more precise: When I recognize an intent on the satellite, the Node-RED webhook recieves two msg inputs with siteId from the satellite and one with siteId from the master. confused
Hello,
I’m doing my first steps in node red.
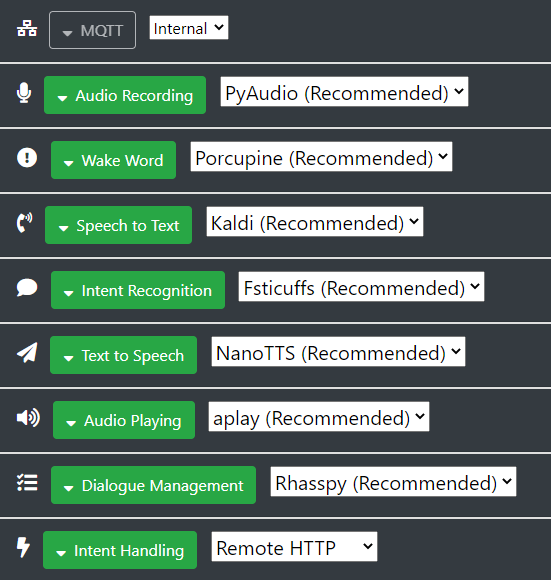
I use server / satellite install with external MQTT.
I created my first node red for the getTime intent and it works well.
My question is how to send the tts to the satellite?
When i send it this way it works: http://192.168.1.xxx:12101/api/text-to-speech?siteId=satellite_name
How can i make satellite_name to be dynamic?
I am not so active here right now, being busy with a lot of other stuff. Seeking to find more time to bring my Home Automation projects forward again soon and participate here more again…
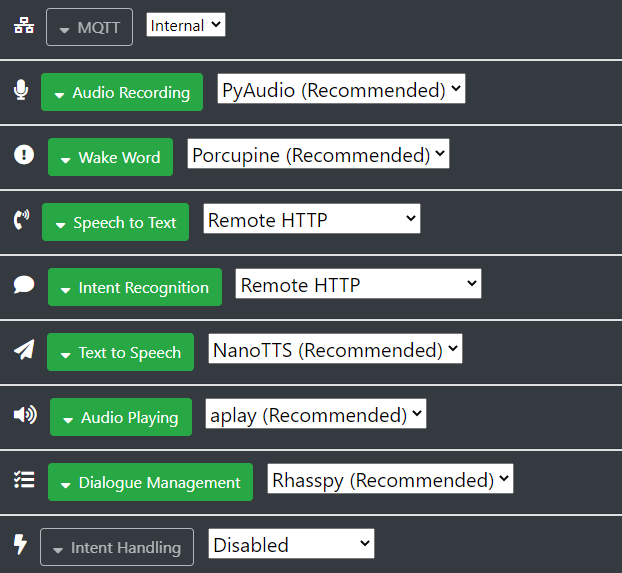
However you could have a look here, how I solved the dynamic satellite output in my Node red flows:
how exactly are you doing your intent handling and TTS responses. To do it similar to my example the msg to the http node needs to contain the SiteId in some way.
There is an issue in 2.5.6 where the server isn’t passing along the site id’s. There is a fix in 2.5.7, that will hopefully be out soon.
I’ve been watching the progress on GitHub.
Yes, can you give some more details on your issue?
Although this is topic is using text-to-speech api, I suggest for intent handler to use
hermes/dialogueManager/endSession with the correct sessionid and a text to be spoken,
This will close the session instead of producing a timeout.
I have a server and a satellite both running with docker and working good.
But in node-red I want to use the API to send output to the speech-API like so : ws://YOUR_SERVER:12101/api/
Here I must replace YOUR_SERVER with the IP ( 192.168.x.x) to send it to one of the machines.
But now I want only the one of them to answer where I spoke the wakeword.
To my siteID (like “server” or "satellite) node-red is unable to post the command.
How can I replace the YOUR_SERVER with the real IP of my siteID or how can I resolve the hostnames in docker (and of course dynamically replace the YOUR_SERVER with a variable to my siteId.
Is it then something like : http://{{{msg.payload.siteId}}}:12101/api/text-to-speech
siteID is not included in the payload.
This is my “server” setup :
where yoursiteid is the satellite you want the text to be spoken.
Obviously you need to get the siteid from the payload or another way to use it dynamically