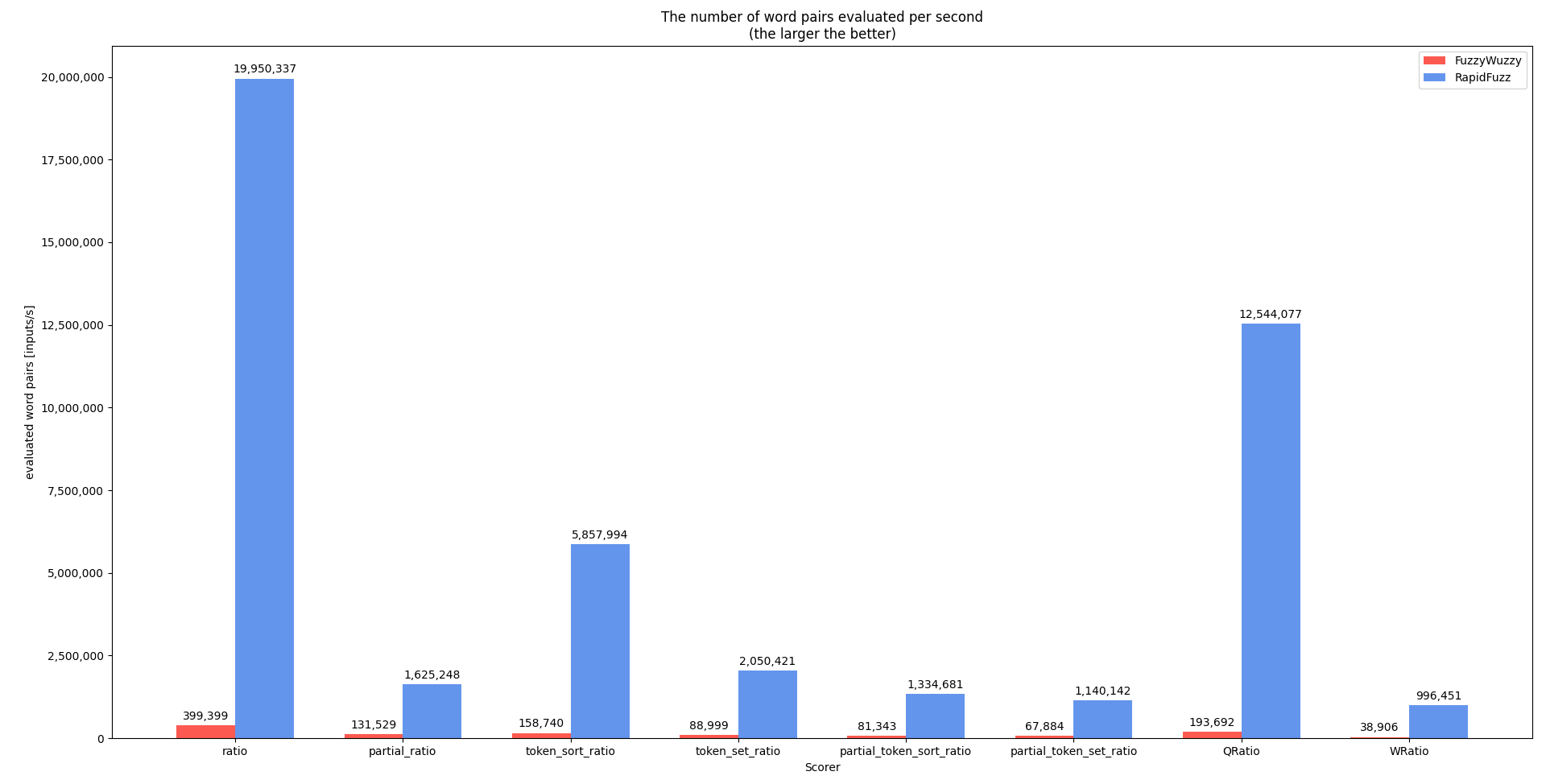
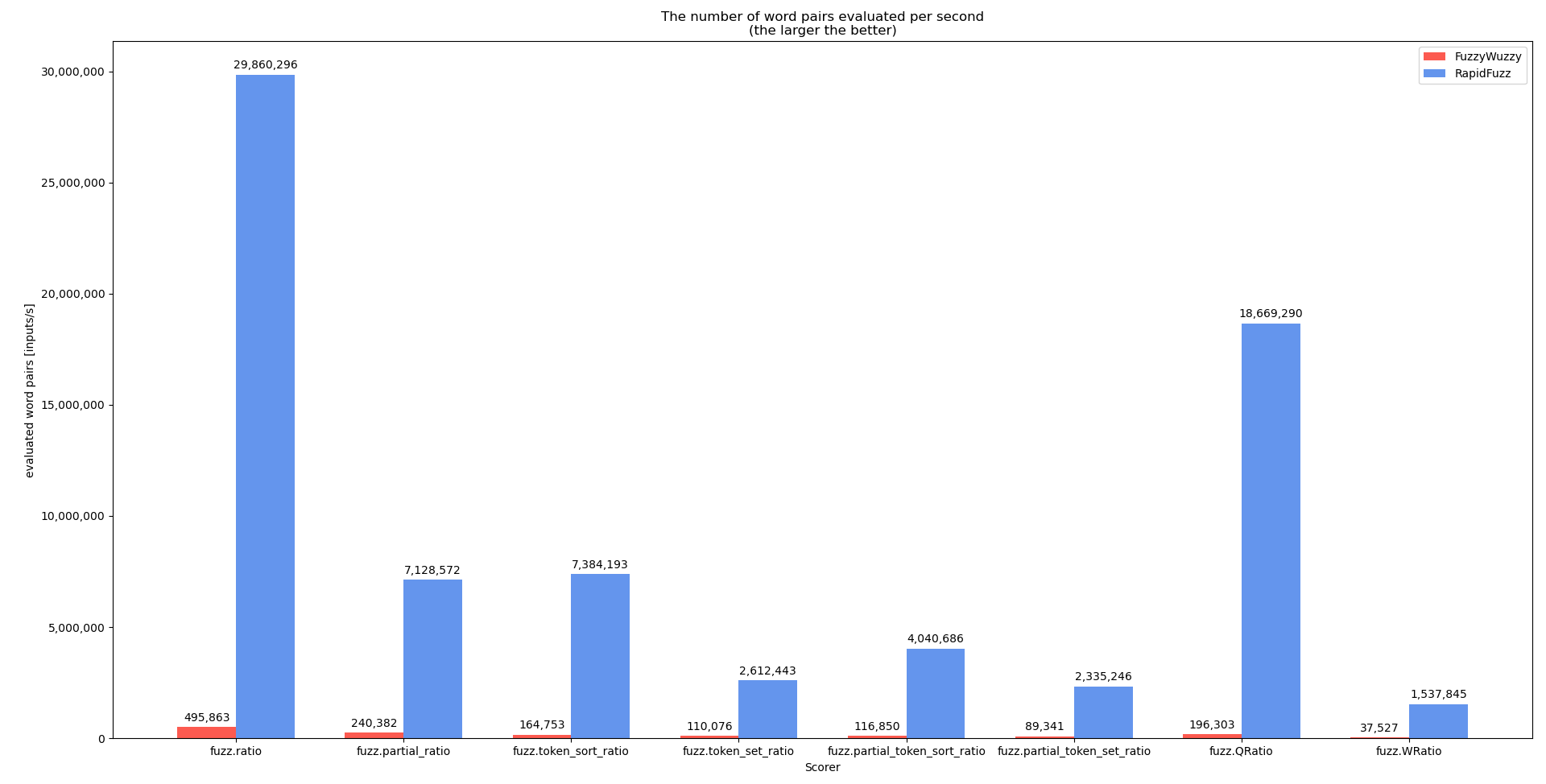
I did spend the last days improving the performance of the RapidFuzz library, that can be used for Intent Matching in Rhasspy. There are still some parts missing, but here are some first graphs on the upcoming performance improvements:
The benchmark tests how fast the library processes a list of 1 million words.
words = load_word()
sample = random.sample(words, 10)
[scorer(x, y) for x in sample for y in words]
I The graph shows how many words are processed per second:
This first image shows the state of the latest released version
This second one the state of the current work towards version 1.0.0

The reason for the performance difference is mostly, that I implemented bitparallel versions of a lot of the Levenshtein calculations. This means, that I store the string in blocks of 64 characters into 64 bit integers, that can be compared at the same time. So the time complexity is O(N/64 * M) instead of O(N*M) in the previous implementation.
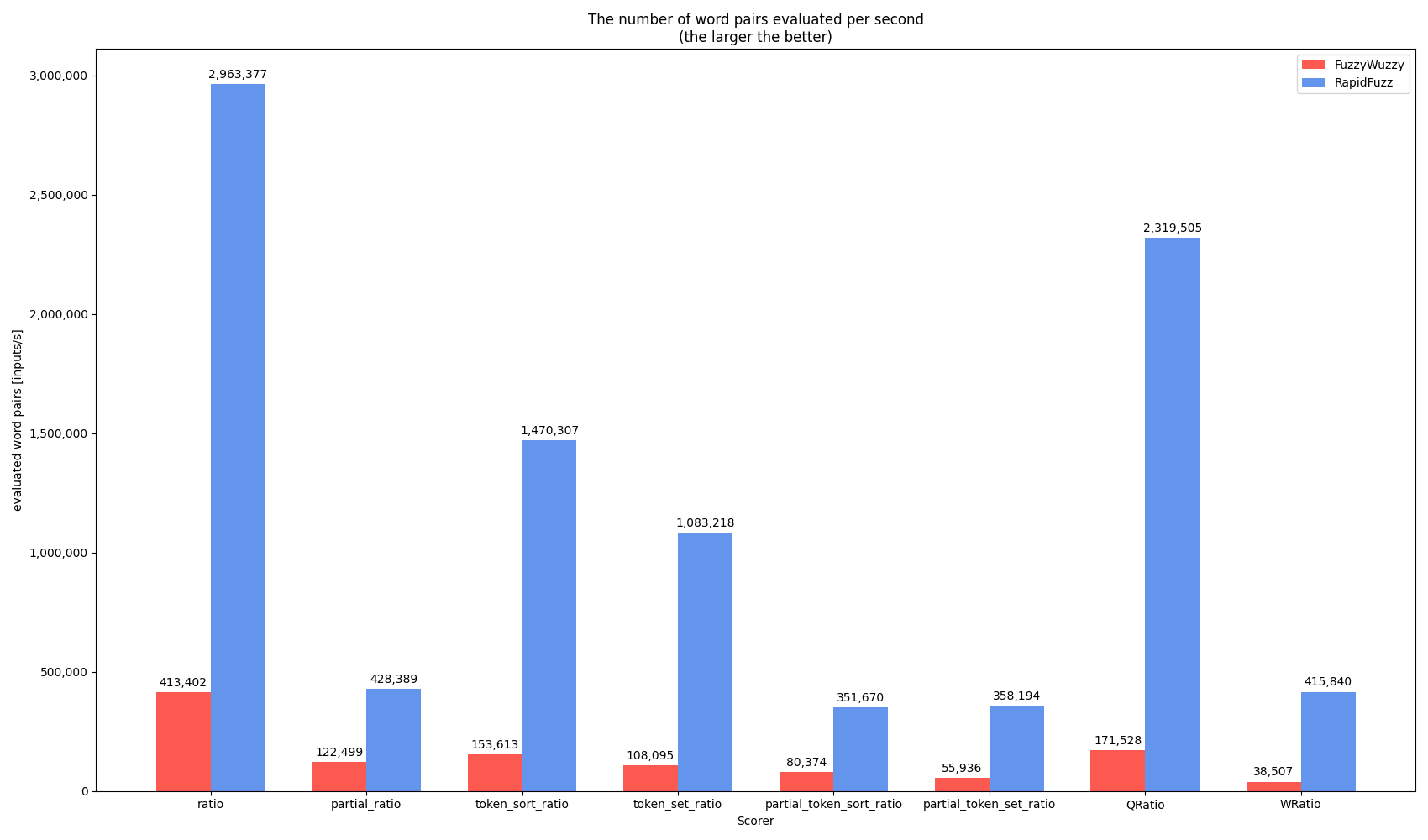
I reality large amounts of data are usually searched using one of the process functions. E.g. in Rhasspy
process.extractOne(query, choices, scorer=fuzz.WRatio)
is used. The following benchmark shows a similar performance measurement for 1 million strings using process.extractOne with the same scorer functions.
[process.extractOne(x, words, scorer=scorer) for x in sample]
For the benchmark I slightly changed the code of RapidFuzz, since extractOne uses an optimization, that allows it to compare strings faster, after it found a good match. Since I test the performance using a subset of the list it would find a good match at different times on each benchmark run, which would make the results impossible to interpret. This behavior is removed during the benchmark. In reality this can cause huge performance benefits.
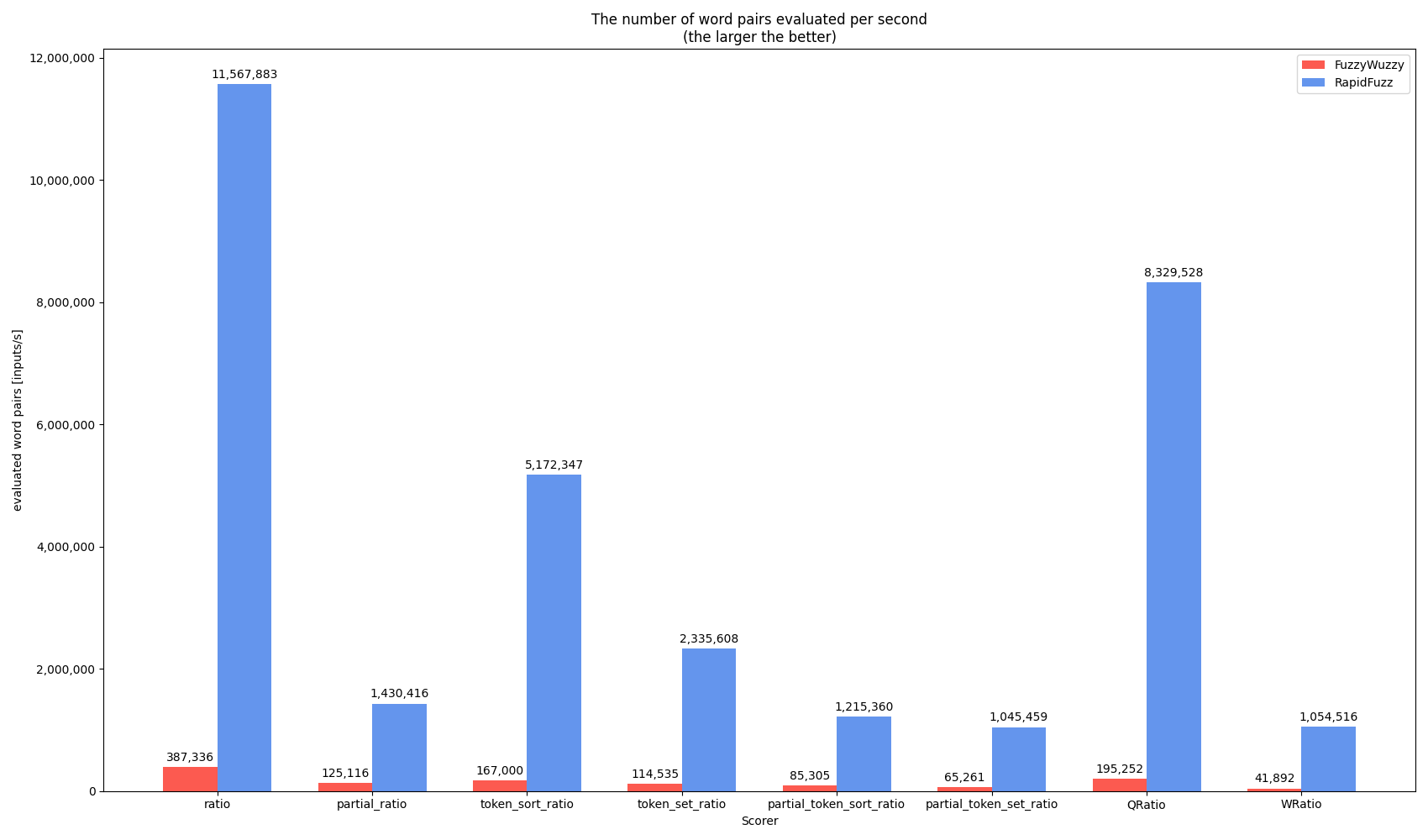
Even with this disabled the throughput is a lot higher when using the process function for several reasons:
- Each query is only preprocessed once (preprocessing lowercase’s the strings and removes non alphanumeric characters)
- The scorers can be directly called in the C++ code instead of calling them through Python. Function calls in python are very expensive, since it has to create a Tuple and a Dictionary on each call for *args and **kwargs + parse them inside the functions.
- I can optimize some of the scorers. E.g. for token_sort_ratio I can sort the words in the query once ahead of time and then reuse the already sorted query.