I’m totally stumped, maybe somebody can help me. I have a program where I’m able to subscribe to and process intents using internal MQTT via mosquitto. Everything is working fine on this end, but when I try to publish text to be spoken to “hermes/tts/say”, nothing shows up in the weblog and nothing happens. I have already verified that I can generate speech through the web interface.
Should I be seeing messages relating to the publishing in the weblog? What can I do to track down this problem?
Here is the code I am using to publish. I am not receiving an error code from the publish call.
static constexpr unsigned int l_MessageBufferCapacity = 100;
char l_MessageBuffer[l_MessageBufferCapacity];
snprintf(l_MessageBuffer, l_MessageBufferCapacity,
"{ \"siteId\": \"default\", \"text\": \"%s\" }", "This is a test");
// We need to count the number of bytes, which includes the terminator.
auto const l_MessageLength = strlen(l_MessageBuffer) + 1;
char const* l_Topic = "hermes/tts/say";
int const l_QoS = 0;
bool const l_Retain = false;
auto l_ReturnCode = mosquitto_publish(s_MosquittoClient, nullptr, l_Topic, l_MessageLength,
l_MessageBuffer, l_QoS, l_Retain);
if (l_ReturnCode != MOSQ_ERR_SUCCESS)
{
LoggerAddMessage("Publish to MQTT topic \"%s\" failed with return code %d", l_Topic,
l_ReturnCode);
}
else
{
LoggerAddMessage("Published message \"%s\" to MQTT topic \"%s\"", l_MessageBuffer,
l_Topic);
}
Yes, I’m not using any satellites or anything like that. If I enter text into the text-to-speech field on the Rhasspy webpage, it will generate the speech and I can hear it just fine. I will also see entries in the weblog corresponding to those events. But when I publish from code, I get nothing. To answer your question about sound configuration, it’s just using aplay.
Yeah, the site ID is default. Here is an excerpt from the log when I use the webpage to play text-to-speech. When I use the code to publish to the topic, I see nothing in the log whatsoever. My guess is that something is incorrect about the message, but I cannot seem to find any mistakes, and I haven’t been able to find good documentation for the message format.
[DEBUG:2022-04-25 12:34:48,622] rhasspyserver_hermes: Handling TtsSayFinished (topic=hermes/tts/sayFinished, id=8208e6c9-fcb4-4704-b9d4-9f2abc420873)
[DEBUG:2022-04-25 12:34:46,897] rhasspyserver_hermes: Handling AudioPlayBytes (topic=hermes/audioServer/default/playBytes/035443ad-753d-4d2f-a48b-97ee64d0aa29, id=8208e6c9-fcb4-4704-b9d4-9f2abc420873)
[DEBUG:2022-04-25 12:34:46,797] rhasspyserver_hermes: Publishing 147 bytes(s) to hermes/tts/say
[DEBUG:2022-04-25 12:34:46,795] rhasspyserver_hermes: -> TtsSay(text='Hello, this is a test.', site_id='default', lang=None, id='035443ad-753d-4d2f-a48b-97ee64d0aa29', session_id='', volume=1.0)
[DEBUG:2022-04-25 12:34:46,792] rhasspyserver_hermes: TTS timeout will be 30 second(s)
Hi Light,
Just something to try, change lang=None to lang=null. I compared your string to several of mine, and that’s one difference that jumps out. Below is a MQTT string that I send from HA to Rhasspy which I know works.
Hi Jeff. Thanks for the suggestion. I’m not specifying anything besides the site ID and the text itself. Do you think I need all of the other parameters as well, for example volume, ID, and session ID?
If I’m recalling things correctly, I did have to provide all of the parameters. If you’re not using a tool like MQTT.fx, I’d also give that a go; really helped me with troubleshooting how exactly to create the topic and message in MQTT for Rhasspy and HA>
I was thinking about trying to subscribe to the topic to see whether the message arrived. As you say, maybe there is a problem with the code. Although I’m certainly not an MQTT code expert, I was able to get the subscription working for intents, so it should at least be specific to the publishing.
Keep in mind though, that the correct way of handling intents and ending a session is not to publish to hermes/tts/say but the hermes/dialogueManager/endSession.
That way your session is closed and no timeout will occur.
You can read some docs about it here:
I do not know your usecase, but is it not simpler to use Node Red like in the wiki? That is assuming you are not using Home Assistant
Oh, I have primarily been using the documentation found at Services - Rhasspy, for example. I was not aware of this other documentation and I think that will be very helpful, thank you.
Yes, I’m vaguely aware of the dialogue manager and as you suggest it may be the better option. But I have tried that as well and it was not working for me either. Just another reason the publish may not be correct somehow. Not having seen the documentation for the dialogue manager, I guessed about the text-to-speech service might be a simpler way to start with.
I will not only be generating speech in response to intents, there will be other events which cause speech. For example, when the application I’m developing starts up, I intend to have a welcome message. Being ignorant to how the dialogue manager and the timeout for the text-to-speech works, what is the better route in that case?
I have used NodeRED, but decided I wanted to cut out the middleman and interface directly. It was not too difficult to get the intent handling side of this going, just time-consuming. And interesting.
Thank you for all the help so far. Your input has been valuable.
Okay, I have subscribed to the text-to-speech topic, and I see that my message is in fact getting published. I’m going to try specifying more of the arguments as @JeffC suggested.
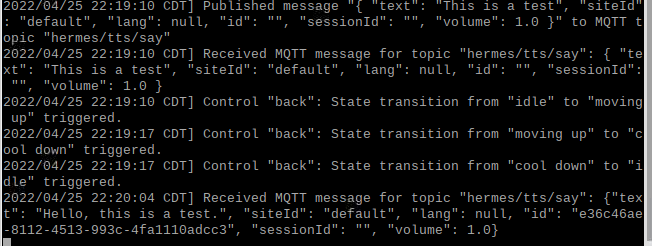
Well, this is strange. At the top of the log here (my log not Rhasspy) you can see that I publish a message to the text-to-speech topic and the message actually appears there. Ignore the quotes around the brackets in the publish log message, those where mistakenly added by me. Nothing shows up in the weblog corresponding to this, and no sound is generated. At the very bottom, there is another message which corresponds to me using the webpage to trigger the speech generation. This one shows up in the weblog and actually generates speech. Puzzling.
Hi Light,
I’d really suggest setting up MQTT.fx (or something similar), subscribing to the MQTT topic, and then publishing the exact json and compare what you’re seeing in the Rhasspy log. Also, it looks like you’re using google/wavenet rather than Larynx from your logs. Are you sure all is good with that part of the equation? Just so you have something to compare, here’s an excerpt of my log (using Larynx):
[DEBUG:2022-04-25 14:34:17,255] rhasspyserver_hermes: Handling AudioPlayBytes (topic=hermes/audioServer/default/playBytes/af87ca1e-bd1e-4c21-b2e5-a98115c8448b, id=07022a83-7254-44ff-8009-0309bf527c23)
[DEBUG:2022-04-25 14:34:17,234] rhasspyserver_hermes: Publishing 147 bytes(s) to hermes/tts/say
[DEBUG:2022-04-25 14:34:17,234] rhasspyserver_hermes: -> TtsSay(text='the front door is open', site_id='default', lang=None, id='af87ca1e-bd1e-4c21-b2e5-a98115c8448b', session_id='', volume=1.0)
[DEBUG:2022-04-25 14:34:17,228] rhasspyserver_hermes: TTS timeout will be 30 second(s)
Yeah, actually I am just using espeak for the text-to-speech at the moment. That’s not really the final plan, but I’m really just trying to get things working before I fiddle with some of the details. I can look into MQTT.fx, but I have already subscribed to the topic using mosquitto and the messages are nearly identical except for the ID, as demonstrated in my screenshot.
An additional thing I tried was to make sure there wasn’t a dialogue in progress when I published the message, but that didn’t make a difference. I also subscribed to the text-to-speech error topic, but there were no errors published there.