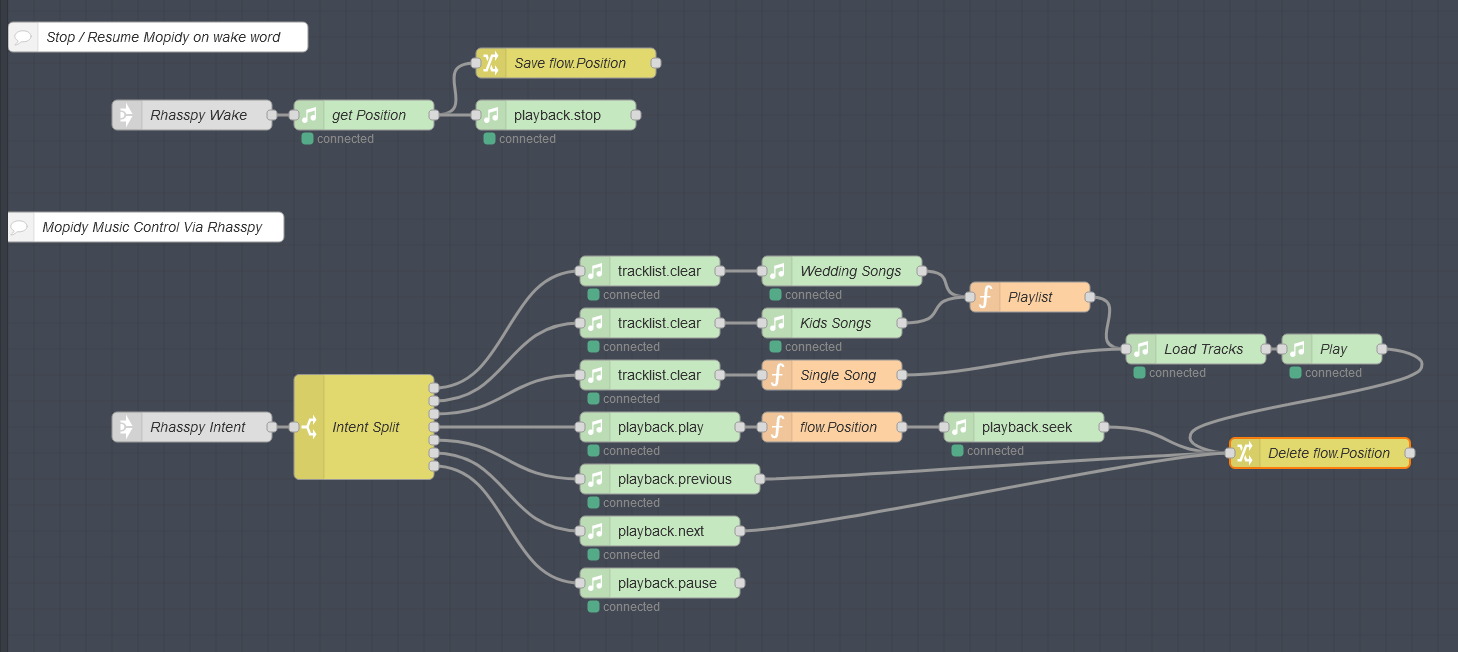
In the end we had the following:
- Mopidy playing music with config:
[audio]
output = alsasink device=default
- Installed and running rhasspy-speakers-cli-hermes:
https://github.com/rhasspy/rhasspy-speakers-cli-hermes
The docker does not work, so build from source and run:
rhasspy-speakers-cli-hermes --host 192.168.43.54 --username xxxx --password xxxx --site-id default --debug --play-command aplay
The host is the MQTT broker you have set Rhasspy to connect to, site-id is the id in the settings of Rhasspy
Both were working correct, Mopidy was playing through the speakers and rhasspy-speaker was also correctly playing.
The problem was mixing those, so rhasspy could play audio while mopidy was playing music.
Without modification, this would not would without modification because both need to use the audio device.
This can be done however with dmix type device
We have changed /etc/asound.conf on the Pi like Bozor indicated.
But there still was a permission error, which prevented mopdiy and the user pi (running rhasspy-speaker) to access the dmix device
We checjed the permissions with:
ls -la /dev/snd
Probably the output will be something like:
drwxr-xr-x 4 root root 180 Apr 24 14:53 .
drwxr-xr-x 16 root root 3860 Apr 24 14:54 …
drwxr-xr-x 2 root root 60 Apr 24 14:53 by-id
drwxr-xr-x 2 root root 60 Apr 24 14:53 by-path
crw-rw---- 1 root audio 116, 32 Apr 24 14:54 controlC1
crw-rw---- 1 root audio 116, 56 Apr 24 14:54 pcmC1D0c
crw-rw---- 1 root audio 116, 48 Apr 24 14:54 pcmC1D0p
crw-rw---- 1 root 18 116, 1 Apr 24 14:54 seq
crw-rw---- 1 root 18 116, 33 Apr 24 14:54 timer
The last line is the problem, the group audio does not have access to the timer.
Also, the user pi is normally not in the group audio (mopidy user is when following installation)
So, add pi to audio group with:
usermod pi -G audio
We gave permission to all users to /dev/snd/timer with:
chmod a+wr /dev/snd/timer
But I think only giving acces to the audio group would be better.
Bozo could now play music from Mopidy through the speakers and Rhasspy would also be able to play sound, mixed together!
Currently, I have taken it a step further and my output is not a speaker, but the snapcast server