To talk about training you can need far more than 200 to get really accurate as just more is better with models especially ones of use.
If you want you can have a go with https://github.com/StuartIanNaylor/Dataset-builder which was just to prove that is put behind a web interface training models could be real easy starting with as low as 20 KW samples & !KW.
It has a record.py, split.py and mix.py to create large datasets by augmented a few provided samples automatically. Its not as good as a large set of usage samples but augmenting to make many is a a good enough second.
The you can train the model with https://github.com/StuartIanNaylor/g-kws which is really just the state-of-art Google stuff that I have done a bit of a write up how to install and get going.
You can create a model on a desktop with or without GPU and ship out tflite models to run on a Pi3A+ a single models runs about 20% of a single core on 64bit of RaspiOS its only the training when any extra muscle helps.
Its not application as this is all about voice what voice commands do you want to use? List them or approx the qty and action of the command as that will make things much clearer.
I think the kernel is limited 2 8 devices on raspi OS but cheaP USB soundcards and unidirectional lavaliere mics as with approx 20% usage of a core you can have multiple inputs and multiple KWS and use the best KW hit channel and you only need to train the model once as its just purely directional instances.
Likely for a bed a stereo pair each covering a side or more would work well with what are relatively tiny Lavalier Microphone
There is a shop on ebay with a large range https://www.ebay.co.uk/str/micoutlet/Microphones/_i.html?_storecat=1039746619 but likely shop around and you can get them for less than $5
The unit can go in or under the bad as you just need to position the mics which are tiny.
The main thing with KW is the more unique and phonetically complex the easier or more accurately you will be able to detect. So ‘Raise up’ is better than 2 KW of ‘Raise’ & ‘Up’, ‘Bed Raise Up’ is better than ‘Raise up’ and so on.
There are loads of ways to do this but many usb mics have software that doesn’t run on Linux especially high quality ones such as Blue Yeti.
The quality varies drastically but often purely due to not knowing any better the alsa parameters and mic settings are just pure bad to start with and low volume.
Beamforming and unidirectional are bad expressions as no mic pics up a beam they just have a narrower pickup than from all directions.
http://www.learningaboutelectronics.com/Articles/What-are-cardioid-microphones# even the ‘beamformers’ are just directional cardioids when in use.
Get any mic the cheaper the better and start training with a frame work as you will soon start to learn the pitfalls and how much noise can affect.
Deciding now before you even try anything is likely going to change.
Get a cheap soundcard and a cheap omni or uni directional from ebay or aliexpress just to test some frameworks it will be no worse than the 2 mic hats that for me have extremely bad recording profiles.
Also you never said is this a universal model for many users or custom for a user of choice as universal models need many voice actors and even though we have many ASR datasets word datasets don’t really exist and why often ASR is used for what really is KW capture.
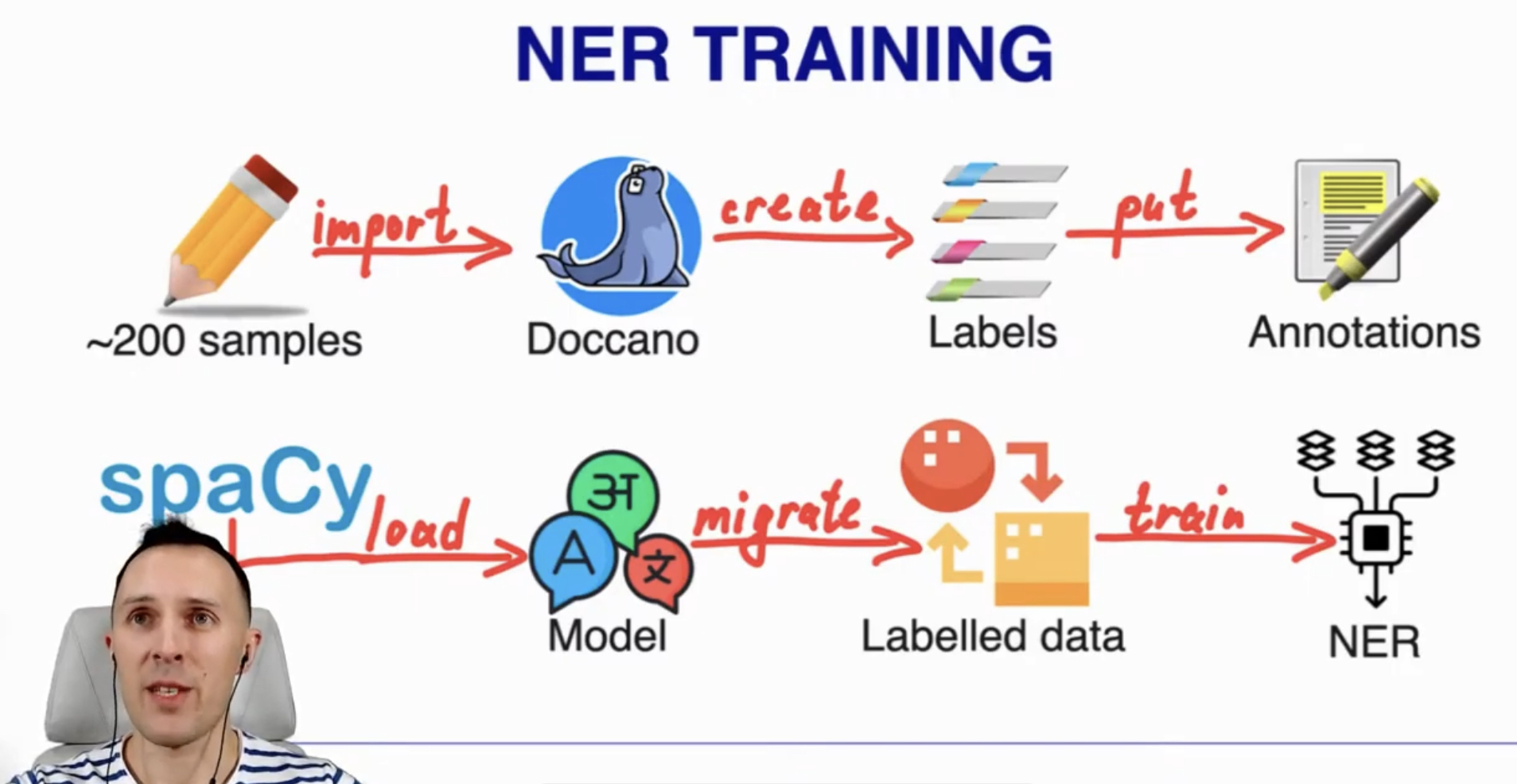
 .
.