Hello everybody,
I need some help to troobleshoot the following problem please:
I am using Rhasspy 2.5 running on docker and I am trying to perform Speech and intent recognition recognition on audio chunks of length ~= 40 seconds and containing few moments of silence.
I am using MozillaDeepspeech for Speech recognition and fsticuffs for intent recognition.
Here is an example of the structure of my audio chunk
[speech_1(3 secs) , silence_1(15 secs), speech_2(5 secs), silence_2(10 secs), speech_3(5 secs)].
And here is the the parameters selected for Deepspeech.
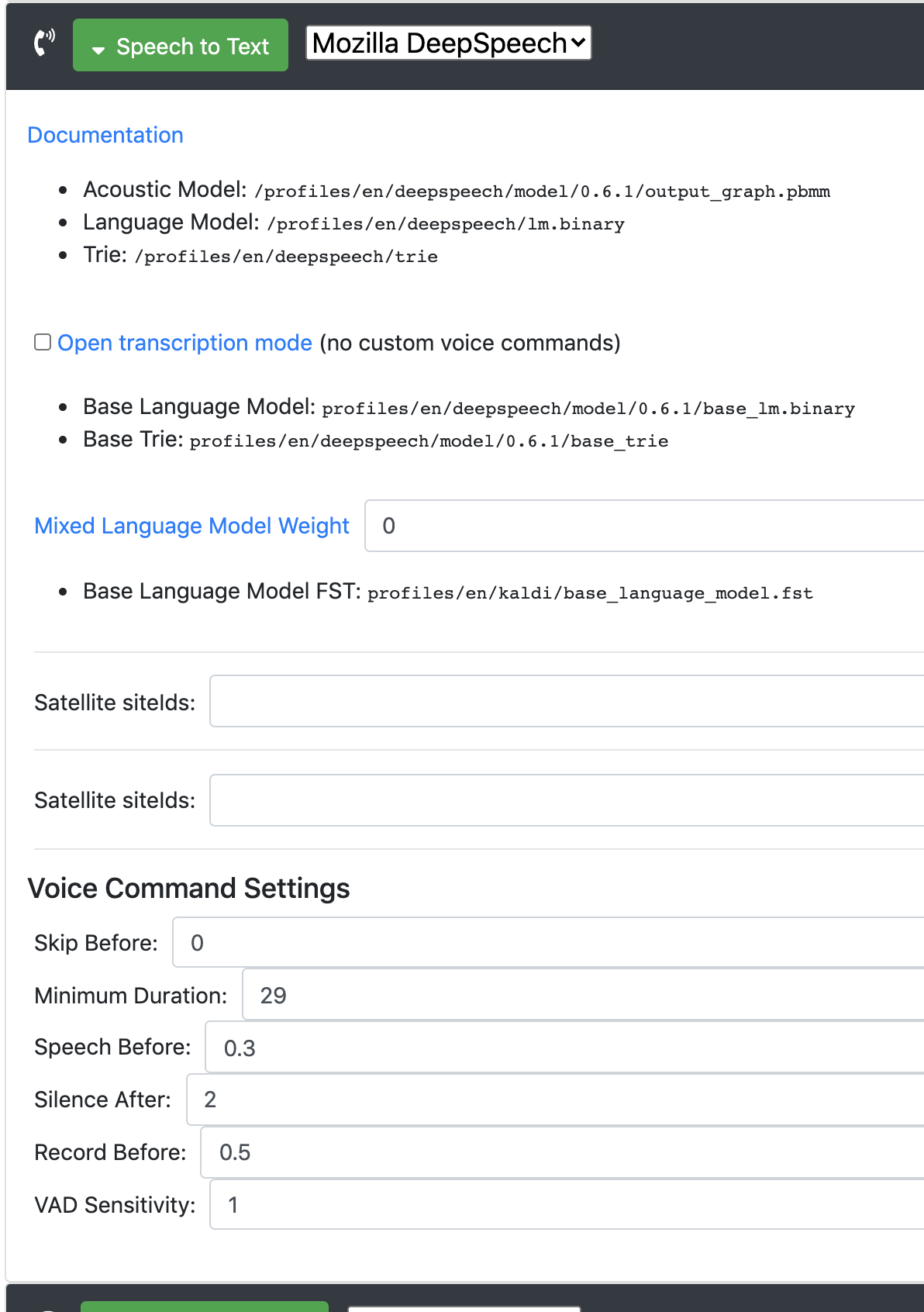
I have managed to obtain good results for audio chunks of length < 30 seconds and don’t contain very long moments of silence ( silence ~= 5 seconds ) .
But if my audio chunk > 30 seconds, Rhasspy returns TimeoutError.
I guess that Timeout = 30 seconds, I have tried to change this parameter using : http://127.0.0.1:12101/api/listen-for-command?timeout=40,
But it failed.
I have noticed that in rhasspy 2.4, there is a parameter named timeout_sec alongside the other parameters (min_sec, silence_sec … ) But I didn’t find this parameter in rhasspy 2.5.
- Dou you have any idea how to make Rhasspy listen for voice command for a duration > 30 seconds ?
And I have noticed that the results of speech and intent recognition are better when I use Upload WAV File that contains the audio chunk rather then using Wake Up and say the voice command.
- Do you know what is the difference between Upload WAV File and Wake Up?
I know that when I use Wake up, Rhasspy use rhasspy silence in order to identify the begin and the end of a voice command. Is this same mechanism used when I use Upload WAV File ?
Thanks for your help !