Can I use Raven independent of rhasspy?
That is, use the code but for my own assistant.
Because I want a Wake Word recording my voice 3 times.
Can I use Raven independent of rhasspy?
That is, use the code but for my own assistant.
Because I want a Wake Word recording my voice 3 times.
Sure, just follow the steps 
Sure, I’ve done this while testing Raven when it wasn’t integrated yet in Rhasspy. Just look at the command-line interface. It emits a message on stdout when a wake word has been detected.
And if your own assistant uses MQTT, you can use rhasspy-wake-raven-hermes: just let your assistant react to the MQTT messages it publishes on each wake word detection.
I don’t know if I’m doing something wrong, what I did was the following:
I downloaded this git: https://github.com/rhasspy/rhasspy-wake-raven
I renamed the folder. Inside the folder I ran: ./configure
I ran “make”, then “make install”
I recorded 3 wav with the command that places:
arecord -r 16000 -f S16_LE -c 1 -t raw |
bin/rhasspy-wake-raven --record keyword-dir/ ‘keyword-{n:02d}.wav’
That created the folder “keyword-dir”, inside are the 3 wav files.
arecord -r 16000 -f S16_LE -c 1 -t raw | \ bin / rhasspy-wake-raven --keyword <WAV_DIR> ...
I tried putting the new directory name at the end
arecord -r 16000 -f S16_LE -c 1 -t raw | \ bin / rhasspy-wake-raven --keyword keyword-dir
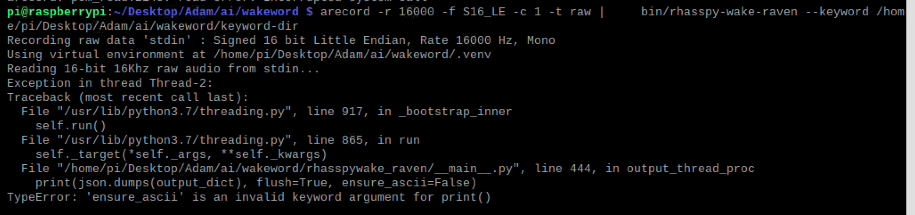
When I pronounce the wakeword I get the following error:
I tried with the other code that gives the instruction but the same error comes out.
arecord -r 16000 -f S16_LE -c 1 -t raw |
bin/rhasspy-wake-raven
–keyword keyword1/ name=my-keyword1 probability-threshold=0.45 minimum-matches=2
–keyword keyword2/ name=my-keyword2 probability-threshold=0.55 average-templates=true
I tried with the example that the steps show, it says that it opens the virtual environment, when I pronounce the wakeword nothing happens.
The error does not appear or anything else, only the "Reading 16-bit 16Khz raw from stdin …
As in the previous case, it appears below what it says about the virtual environment, but as I said, nothing happens.
arecord -r 16000 -f S16_LE -c 1 -t raw |
bin/rhasspy-wake-raven --keyword keyword-dir/
I am doing something wrong?
Some help?
I honestly don’t know what I’m doing wrong, I’m new to this.
Looks like a bug. I’ve created an issue on Github
It looks like that is a code issue with rhasspy-raven
Above they said they have already used it without Rhasspy. Can you tell me what is the stable version?
The last commit has something about ensure_ascii, so I’d try the commit before that.
There are no independent releases, so “stable version” is not appropiate in this case.
I suggest removing this commit to you local branch and try again:
That is, I should remove the “, ensure_ascii=False”. Line 170 of bin/test-raven.py… and from rhasspywake_raven/main.py line 444, right?
I tried it, and it does nothing.
Can you explain what “nothing” is, in this case? Same error?
You have to clean and rebuild as well, did you do that?
Thanks a lot for the help, now it works.
I have a question just to double check: are the recommended wav files only 3? That is, if I place more than 3, does it get confused?
Because I notice that it is not very sensitive, I must say the word with the exact tonality and at the exact distance with which I recorded it.
Note: I tried with probability-threshold = 0.4 and yes it is more sensitive, but, as I said, I want to check if placing more than 3 or 5 wav would work better.
I have no idea, sorry about that. Just place more than 3 and see how it goes
Nice that it works now anyway
I would not put more than 3 templates. Adding more would probably only hurt accuracy and CPU usage.
The templates should be recorded in a clean environment (no background noise, no normalization, no clics, no pops, etc). You can use audacity to record, check and post-process your templates.
You can try to enable the template averaging to see if it improves detection.
To avoid false positives, try to use a 4+ syllables keyword (OK Google, etc). Avoid short keyword (Alexa for instance does not work very well, too short and easily mistaken for other common words).
Hope this helps. Cheers
Thanks, it did help a lot.
But, I have another question, what is this method called which only allows 3 keywords?
I say it because I notice that there are two, for example, to train my Android phone with “Ok Google” I have to say it 3 times, I suppose that is a method, but, to train an STT like DeepSpeech a lot of sentences are used, that is another method. Can you tell me the name? I want to investigate further.
Greetings and thanks again.
It is based on this
This is a type of "keyword spotting’ (sometimes called “hotword”). The original article is here: https://medium.com/snips-ai/machine-learning-on-voice-a-gentle-introduction-with-snips-personal-wake-word-detector-133bd6fb568e
In short, keyword spotting only needs to do a binary classification: either some audio is or isn’t the keyword.
Speech recognition is a much more complex problem, where sounds are mapped to words and sentences. Here, the system must juggle a lot of probabilities to determine where word boundaries are. If you’ve ever recorded yourself speaking at a normal pace and looked at the waveform, you’ll notice it’s pretty hard to tell from that where each word begins and ends
Hypothetically speaking, what happens if I use multiple keywords with the same word but with multiple tones and pronunciations?
It won’t have any inconvenience, right?
For example, a folder with 3 wav with a pronunciation and a tone X. Another folder with a pronunciation and a tone X, and another folder with a pronunciation and a tone X.
arecord -r 16000 -f S16_LE -c 1 -t raw |
bin/rhasspy-wake-raven
–keyword keyword1/ name=my-keyword1 probability-threshold=0.45 minimum-matches=2
–keyword keyword2/ name=my-keyword2 probability-threshold=0.55 average-templates=true
Nope, shouldn’t matter
Also, there really is no limit at 3 WAV files. It’s the minimum recommended, but you can have as many examples as you want. Without template averaging, this will be slower. With it, there should be no performance difference (though it may be less accurate).
Thank you for all of your help.
I have a suggestion for you.
Correct me if I’m wrong, I’m seeing that in Rhasspy 1st you say the wakeword, 2nd starts recording, 3rd uses the STT to recognize what I said in said recorded file.
Don’t you think the process would be faster without being recorded? That is, that he understands all the words you say and that he immediately recognizes the sentence.
Another suggestion, do you plan to add Google STT? It is paid, but, as you know, it understands all languages in seconds.