Might be interesting here:
I just ordered one
Might be interesting here:
I just ordered one
Can this be integrated with rhasspy or is it standalone?
If someone is interested, it is $49 and currently out of stock.
I hope so, standalone will probably not be possible
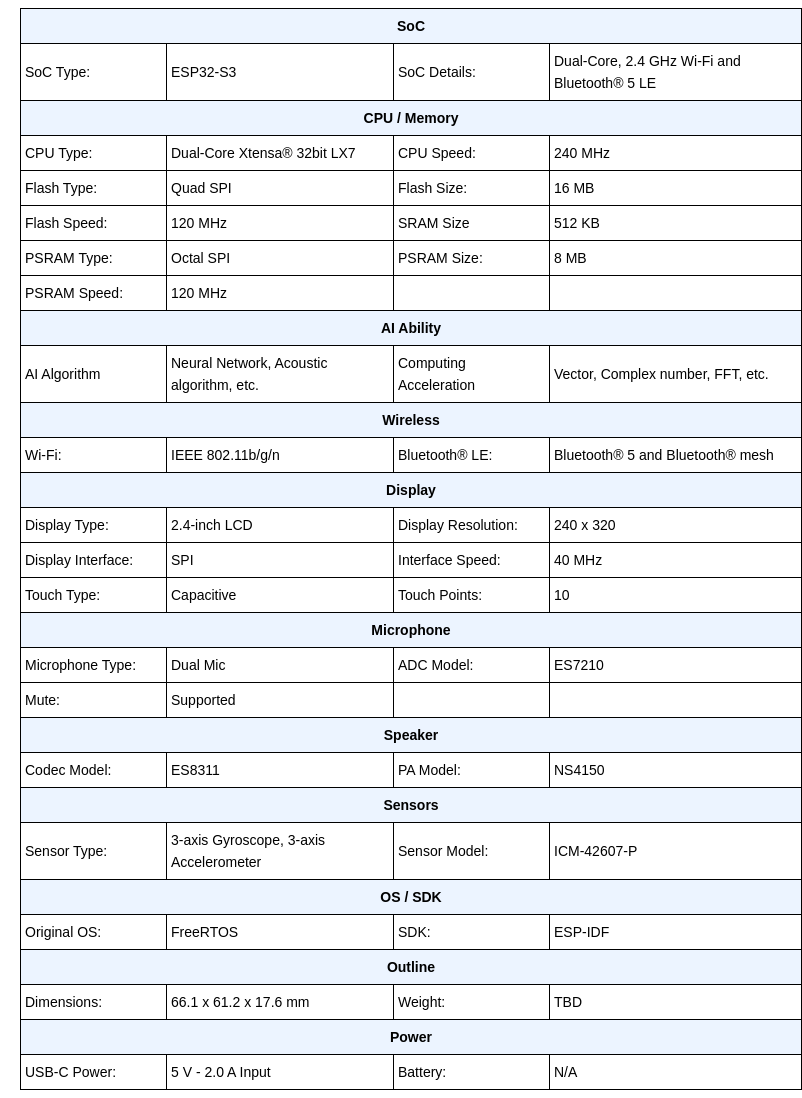
Can’t figure out what kind of speaker this device has. Does anyone know?
ns4150 is a 3watt amp so just one of those oblong 3watt affairs that you can see in the product strip down.

Its just a demo box and likely to be awful for audio but at least is a AIO
so what needs doing to get rhasspy working on this?
it has AEC Beamforming capabilities etc doesnt it?
I was more into this train of thoughts:
Use the builtin wakeword detection
Record chunks of audio
Send the chunks to Rhasspy STT
Get back the text
Act upon the text
so you would approach it as a sort of satellite addon only and not to run rhasspy on the S3 as a satellite.
Rhasspy will not run on it, but my plan is to use it as a satellite.
The device is a bit stronger than the esp32 and I hope to get local wakeword going. If that is done, no constant audio stream is needed. I have local hotword working on an esp32, but I need to crank some more power from the satellite code.
Yes, I don’t see how an ESP32, even a S3 as in here, would have enough horsepower to host the entire Rhasspy.
Running it as a satellite, however, should be doable
i think it still needs the minimal satellite only install option somehow. no mqtt install etc as it would be using an external one etc.
people seemed quite excited about the possibility of using the aec on the S3 though. i recall quite a few discussions about it on here that i read over the past few months.
will rhasspy definately not run on it? would a chopped down version be possible? with just the local wakeword and everything else handled at the mnain rhasspy base station?. i just like the interface of rhasspy to be honest. although i guess a conf file with the mqtt username password, satellite id, sttic ip and ip of the base station woudl be all thats needed if the local wakeword is on the device.
@romkabouter is your plan still to use hermes mqtt?
Nope. This is a esp32 device. No change as far as I can see
Yes, basically I want to get rid of the continues audio stream for a long while. Local hotword detection makes it possible to only stream when needed.
If that works my plan is to try and listen to commands as well, just like the demo on that box is doing now.
But then with custom trained models following this:
But I want to start small and focus on local hotword detection first, also following the above video.
The current firmware for english is pretty stinky but someone has done a fix with…
Still they are using a quad channel adc with a 3rd loop back to sync the i2s stream latency so on a single esp32-s3 their libs will not work.
The firmware they supply is both wakenet (KWS) and multinet (ASR) and guess could be used without Rhasspy if MQTT instead of the ESP-RainMaker or other IoT protocol.
Haven’t tried the above firmware yet. [Alexa seems to work fine]
Any layer compatible model can be converted with the tools in https://github.com/espressif/esp-dl which is s3 optimised. Not sure if we are playing catch-up with tflite-micro with the s3 even if standard esp32 support is there.
Hi @romkabouter,
You have the great project
published.
I have searched here in the forum but no more information about the possibility to use ESP32-S3-BOX as satellite for rhasspy.
You seem to have this box in the meantime. Is there any hope.
Since I can neither Python nor C programming, I can not assess this at all.
Yes there is, however this board is not yet supported in platformIO, but it seems to be in the dev branch.
I haven’t gotten around to try that however.
So until I find a way to try it or when it becomes available in platformIO there is no support.
I thought about writing a specific version with plain c, but that is too much of a hassle for me atm, time wise.
I have the box and it is a neat device, the demo works well but it is just a demo. I am checking the code on how the local hotword detection works, because I want to implement that or some other way.
So for now I have to say I’m sorry but my code does not support that device. It is WIP so to speak and it will only be a matter of time.
The esp32-box-lite is the one to check as that only has a 2 channel adc however they have managed that guess they have some way to count cycle latency and adjust for the AEC.
Wakeword is sort of standard wakeword tech they just have quantised and used a low bit rate to make it as small as possible but for all intensive purposes its not much different than a tensorflow4micro model maybe just a plain cnn or maybe a ds-cnn but with the footprint think its the previous.
The esp32-box feeds the 3rd adc channel as a loopback from the dac to get accurate sync for AEC.
The 4 channel ADC they have from everest semi is great but sadly doesn’t seem to come on cheap china modules and this is why I think the esp32-box-lite is the interesting one as seems to do very much the same with a single stereo adc (but does say dual mic). So either they know the clock count and drift compensated or you can use a single mic and loopback dunno which but you should be able to port to standard esp32-s3 devkits when there is no need for a 4 channel adc which is a problem to obtain and implement.
Esspresif do have some interesting free speech audio algs esp-sr/docs/acoustic_algorithm at 3ce34fe340af15e3bfb354c21c1ec2e6e31a37e8 · espressif/esp-sr · GitHub
But the are blobs where you can use freely but they are keeping the code to themselves
The wake word uses https://github.com/espressif/esp-sr/blob/3ce34fe340af15e3bfb354c21c1ec2e6e31a37e8/docs/wake_word_engine/README.md
You can see from the parameters the models are quite small but not much different to current state-of-art models.
I still think LSTM or GRU have to be still ported to micro but think they are in the process of.
I think the esp32-box on the S3 is a pretty good show sample of how much of an improvement the S3 is over a standard esp32 and if you where to remove the ASR prob is ample room for a network stream.
Wake word is just wake word, but would love to know what they do with the BSS (blind source speration) to extract voice.
They do say what they use for wake word https://arxiv.org/pdf/1609.03499.pdf Dilated convolution layers but a better source for kw is https://arxiv.org/pdf/1811.07684.pdf
But parameters alone they look no different to any models at https://github.com/google-research/google-research/blob/master/kws_streaming/README.md but I think they have used the xtensa LX7 LSTM layers that are behind a licensed paywall and why they are in blobs so hence why I say your limited to say a CNN or DS-CNN.
@romkabouter
It is WIP so to speak and it will only be a matter of time.
Thanks for the information!
I have ordered the ESP32-S3-BOX and EPS32 EYE as a precaution, to familiarize myself with the matter ESP 
In the net there is a lot of information and very often see MQTT, I will start there and look.
@rolyan_trauts
The esp32-box-lite is the one to check as that only has a 2 channel adc however they have managed that guess they have some way to count cycle latency and adjust for the AEC.
I was to fast and ordered already the S3-BOX 
The architectural differences I have understood thanks to your explanations. deeper I can then but no longer follow and am glad that there are people like you.
I am curious how this projects and controller boards will develop, especially the satellite concepts.
I have started a repo https://github.com/StuartIanNaylor/ProjectEars as its been such a long time where its been known opensource voiceai is lacking initial audio processing.
So in the presence of noise all the frameworks we have are very poor.
Its also really annoyed me that KWS/network mics are branded and shoehorned in proprietary systems rather than being just another HMI (human machine interface) like a mouse or keyboard that works with any.
I am not a great programmer but its been pretty obvious Python is not good for audio DSP and that seems to be the limit of what these frameworks supply.
It is very possible to create self learning broadcast on KW interoperable network mics and rather than reinvented the wheel so audio can be branded various audio RTP already exist so that audio out is just a matter of choice with the likes of Airplay, Snapcast or whatever wireless audio system you employ so that its interoperable with existing hardware.
This goldrush branding and absense of expertise in initial audio processing has resulted in very poor opensource voiceai as opposed to commercial offerings and has relegated much purely to hobbyist/enthusiast markets.
I started thinking the esp32-box with built in audio algs at a cost price is the only way to provide competition to the commercial market as with some lateral thought distributed low cost mic arrays in a client/server infrastructure is far more efficient that the peer2peer model of commercial product and likely could compete in terms of functionality and audio processing.
The work to port all that to C for a noob like me is very high but something I was slowly chipping away at then Raspberry released the Zero2 at an extremely good cost price and much of the libs and software is already available.
Recently I have been demonstrating some accurate KW models from the google-research/kws repo google-research/kws_streaming at master · google-research/google-research · GitHub and with a bit of hacking and mangling created a simple delay-sum beamformer and have a few other tricks up my sleave where C++ does allow reasonable load on a PiZ2 where current Python attempts have been pretty poor.
You can use KW softmax in a distributed array to garner the best node for an ASR sentence and broadcast compressed audio to a KWS server without enforcing stupid protocols for branding and ownership sake alone.
From that point there are some extremely competitive ASR frame works to choose from where transcription should be only processed by a NLU skill router so that again skill servers can be interoperable standalone and give choice of implementation.
The leeching and branding of opensource to downstream into ownership has been rife and very little upstreaming to initial source has been done and for me its a vital process of open source and something I aim to return to.
The voiceAI bubble popped a long time ago but the continuation by many to try an emulate Snips shows a level of competence as that time has gone but worse its created a vacuum of interoperable opensource surrounded by a plethora of competing low quality frameworks trying to present Snips like value.
The S3-Box currently is as bad as any is its focus is Espressifs own proprietary frameworks but the audio processing even though blobs is more than any other reasonably known voiceAI framework as I don’t know one that has any solution to the the basic standards of big data commercial low cost voiceAI.
It is possible to use TFlite for micro as the repos here by 42io · GitHub are a great demonstrator.
Audio RTP libs do exist and various C ports for airplay & snapcast do exist as others.
Compression codecs such as opus & amr-wb so uncompressed audio isn’t flooding networks.
Simple low complexity extensible protocols over websocket that can easily distinguish between binary & string data for control.
On device training and OTA model shipping.
But as said the Raspbery Zero2 has created new opening as the cost difference between the Z2 & ESP32-S3 is negligible currently but my aim is to provide an interoperable framework with the 2 and work on the raspberry Zero2 as much of what is needed requires very little work and a large part is purely installing airplay/snapcast on a device leaving only KWS and audio processing and websockets current sentence audio out transmission to be provided.
It will not stay that way as the ESp32-S3 with economies of sale could eventually land at a 3rd of its current price while I expect the Z2 to remain static.
Its also just one of many where low cost microcontrollers running efficient low level code can become standardised voice sensors than belonging to any specific branded proprietary system of ownership branding.