The dataset now has all wav files in subfolders of visual, OneSylable & TwoSylable.
‘visual’ was chosen because it was the only 3 sylable word, no phonetics have been used just a split of the remaing into one or two sylable and the testing & unknown percentage has been upped to 30%.
Classifying by the construction of the the words provides far more correlation to the mfcc spectogram so instantly the model accuracy is high.
The 3 sylable ‘visual’ is extremely unique and is akin to ‘heygoogle’ ‘alexa’ keywords that are also chosen for sylable complexity and phonetic uniqueness.
I will let that run and see how the end tests are.
The dataset was moved 2 new folders added (OneSylable, TwoSylable) then all word folders moved to the corresponding folder.
The testing percentage has been upped and this is going to take much longer and generally the Google command set is specific for commands and prob not the best collection for KWS but the default demo only used 10% of what was available which is limited anyway.
I think this is how Snips trained their « Hey Snips » model. They trained a model to recognize « unknown », « Hey », « Sni » and « ps » sounds and used a specific post processing algorithm to check if the correct succession of sound was detected.
I have no knowledge of Snips but just been looking and researching what a MFCC image looks like as an image.
So first the sound and construction of words is the only logical structure for a time based image of words that MFCC creates.
But yeah I think you can classifiy with high accuracy and then post process against those classifications in a sort of reverse google page-rank to provide further weight to recognition.
I think Mycroft Precise is a phonetic splitting engine so you can create your own combinations but that increases load and reduces acuracy.
I have noticed with Precise that at times it will recognise ‘Mycroft’ without a ‘Hey’ as KW even though it shouldn’t.
I think that is for most parts why Porcupine is so fast and light as its a single word trained model and not some postprocessing system of concatenated phonetics.
Doesn’t matter if as literal language ‘heysnips’ is two words as a model word its a single 2 sylable word if trained as porcupine models.
Splitting into single words and then concatenation processing just requires heavier models and postprcessing complexity.
I am going to run this which will be just ‘visual’ vs ‘unknown’ then run with ‘visual’, ‘OneSylable’, ‘TwoSylable’ as wanted to see even though distinct the blur of all in unknown creates a none descript and essentually useless datum for postprocessing which is just a score alg aka page-rank.
Then also if you are going to phonetic split to how many classifications and how much data you need.
The common voice, Librevox, VoxCeleb and google command set all have the wavs in there datasets but extracting into words that are more applicable to give even coverage in classification quota whilst maintaining fast and small models is all a leap in the dark to me.
Also in this example the MFCC format has me totally bemused as bin_count for mfcc is 40?! Whats that then!?
Also the trick to reduce background noise of raising the log-mel-amplitudes to a suitable power (around 2 or 3) before taking the DCT.
Not really sure where to do that in this code but many advocate its use as basically its a bit like an audio expander where the predominant features are accentuated and what are likely artifacts tend to drop out of the MFCC image.
Rhasspy could definately have its own KWS but to stop its models being a black box we need to share and have some form of queryable dataset that is just taken from the huge collections that are freely availablle but based on word construction and sound rather than literal meaning.
Also you can overtrain models as not sure what really happens but accuracy seems to have this epoch target and then going past that things seem to degrade.
I hit 100%/100% training and valdation accuracy after a couple of 1000 steps and now seem to be making things worse but will just let it run purely so its like for like and maybe readup on that another time.
Keras seems to have this function to cut short training on best hit accuracy step, with the google example you use Tensorboard and monitor and set that yourself.
Seems once you hit a level training from that point has no gain and can even add error to the model.
Prob about 8000 pointless steps done on this very simple model.
I think you can load up any checkpoint and start again or process that step --start_checkpoint
Its a bit of a pain in the proverbial as it grabs labels from the bottom folder name and copying the files is a problem as even though looks like a uid or hash or somethig there are many duplicates
Prob tomoz but think its demonstrated how accurate a CNN can be if you categorize by mfcc sound image rather than literal words.
The model is here and some capture clips after the model was created.
Using visual as it was there but the clips show how the capture window must be the same as the model window and that KWS is extremely easy and accurate but the dataset wavs must be preprocessed by the project audio_processor otherwise you are just adding inaccuracy.
You have to have accurate capture windows in your dataset otherwise the accuracy for word simularity will suffer or like the majors you select and fix with unique non similar KW choice.
There are always going to be words that are extremely similar visable/visual but also regions are not just country and generally an assumption of ‘Capital’ pronounced recievership of a nation.
Models are really easy to create the datasets are really accessable and we have a Voice.AI project that doesn’t process its own datasets.
The models and labels are in speech_commands_train.zip.
Model can be run, just edit the folder/file names.
Its not about the models for a singular KWS as that is no advantage for opensource or a primary function of sharing models.
Sharing a dataset for a project is hugely important as if that is done the models wil come.
Strangely that is not done or even talked about.
Its not really opensource when your datasets are closed as in terms of models that is the code.
That one for me being English is important as it is split regionally and by gender.
Being a Northern Oink! http://www.openslr.org/resources/83/northern_english_male.zip is likely to produce much better results but the words are in sentances but there are many.
But its not just being English as regional dialect can have huge effect on accuracy in all languages.
Is there any of you python guru’s who can run ASR and mark audio with cut points on recogintion and split wav sentances into words.
It doesn’t matter so much about words that can not be split as generally the datasets are extensive and presuming numerous word sets could be gathered.
It would be great to have a database that you just run a query and get a dataset or datasets based on region, word, sylable, phonetics, pronounciation, language…
Getting the space and setting it up could be a huge task and would stilll benefit from a word extraction tool as many datasets are sentences.
If you are only armed with Audacity organising a dataset for a model is hugely intensive, but some tools to normalise, set wav window parameters, rate and encoding are probably not much to code and does anyone know if anything already exists?
PS another model there which was just the interest of how a keyword relates to what its not so had the additional labels of onesylable & twosylable with corresponding word collections.
Testing with my audio_capture from above the simple cnn as long as normalised manages to differentiate similar words such as visible and mythical extremely well.
Also when normalised can tell the are 2 sylable words and not sure if they will be used but it does seem to make the keyword detection more accurate.
Yeah its ok for taking out silence and stuff and a great toolkit.
Its the ASR to create split points in audio so that something like sox could.
Most datasets are spoken sentences that we have the text but not split cue points.
If you take the google command set there are 3000 for each word and don’t fancy doing that manually via audacity.
The datasets also allow to to queue up sentances that you know conatin words but even with sox without those split cue timings its a no go.
Unless you got ideas how?
I’ve stumbled upon an article detailing how Snips handled the “personal” wake word detection with only a few samples:
This was a pretty interesting read…
@synesthesiam Maybe something similar could be implemented as a Rhasspy service? It should allow both custom wake word detection and speaker identification…
To be honest to to the availbility of technology and what @Bozor said the private services of creating models or hiring TPU slots is getting extremely cheap.
I think you can create a general large model and also custom training to that large general model that will be processed on a cloud server in minutes rather than hours on a I7 and forget about it levels on a Pi.
You might even be able to squeeze quite a few models in a single hour and if so the service becomes extremely cheap.
Offer the service on minimum donation as the training update needs to be done only once and maybe occasional updates and even opensource has to cover its running costs.
If it was $5 a pop it would prob also leave some additional funding even though small for storing datasets.
Models are blackboxes and not opensource as without the coding dataset they are closed so its essential to have the datasets.
But yeah you could prob also train just a simple specific KWS but also with the advent of cloud TPU you can train general large datasets and supplement with custom training.
They actually need to have set keywords and the use of phonetic based KWS that introduces high complexity, load and model is such a strange avenue to take.
Do you call a dog a cat because you prefer that word?
That article is great and the only thing I noticed and maybe you can do both but think this will create less load.
You don’t need to do audio preemphasis as you can do that via the MFCC creation by raising the log-mel-amplitudes to a suitable power (around 2 or 3) before taking the DCT.
High pass filetering is not all that load intensive but the above is also another solution to removing noise.
In fact you don’t have to do any of that but just import librosa and set the parameters but the action is the same.
That article is really good though and really do think there should be a truly open KWS that has access to datasets as sharing models is akin to closed source.
The false alarm rate of the Snips method is really high though False Alarm rate per Hour is 2.06
When say you compare to Porcupine that has 0.09 FApH
Things have moved very quickly in the AI world and that article when published was pretty cutting edge but aslo some of its content is now quite dated.
Its false alarm rate is extremely dated by many standards now.
But generally KWS is quite simple much of what is in the article is already in libs or frameworks or both.
ASR is complex KWS is fairly easy to accomplish but also the ability to use server farms in cheap slots has change on how we may use AI.
Custom training of use may well become a norm as over all other methods it can drastically increase accuracy.
But going back to datasets as its all about the dataset as any model created with a dataset that was captured with the audio capture system of use will always be more accurate.
it does not work well for languages other than English
a user cannot train a custom wakeword for Raspberry Pis (only Linux, MacOS and Windows)
it is not open source and I do not like the way Picovoice is heading toward commercial licenses (Snips much?)
The problem with training a NN is that for most people (I included) it might be way too complicated.
Snowboy seems to work pretty good with personal models based on a few samples (which might be based on the same DTW stuff as Snips) so I’d like to explore and see if this approach can work without taking out the big guns and train a NN using à multiple GBs dataset.
I’m very curious of the performance of the DTW technique though (accuracy and CPU wise).
I first though that ASR and NLU would be the hardest part but it turns out wake words seems be the most lacking one
Did you manage to get your « visual » model to run on a Pi on an audio stream without eating all the CPU?
To be honest I am not advocating all to train NN even if it is much easier than I expected.
You have seen my reluctance to code nowadays
I haven’t actually tried the model on the Pi but reason I picked it is because of the extremely light CNN tensorflow KWS that have available examples proven and available.
Arm and a few others did some repos of fitting KWS into 22k was it? Anyway it runs on low end microcontrollers.
There is also mobilenet and various others but without trying I know pi3/4 it will tickle the cpu and on a Pi0 run not much different to Porcupine its all down to what you quantise to and export the model to.
This guy has some great Pi specific version with fixes and low load mobilenet examples and benchmarks and load can be extremely low.
I am exactly the same about Porcupine but the example you posted is > 2000% more inaccurate, that is not just bad that is utterly terrible.
I use Porcupine as a datum of low load high accuracy KWS but don’t advocate its use but actually believe similar results are possible.
KWS or NN isn’t hard and no-one is suggesting people train there own NN as that would make the assumption they have a reasonable > Cuda 3.5 compatible card and the patience.
Its very possible as part of an opensource offering a service that will do that and return in minutes without any knowledge of NN or training.
A general purpose KWS can run as is and be collecting KWS of an initial period and then the user can have the choice to upgrade with a custom train and needs no knowledge or equipment.
It wouldn’t be so bad if the snips method was 2-3x less accurate than some of the others but x22 worse is just extremely bad and that article was quite promising until my eyes bulged at that failure figure.
If you want accurate multipurpose KWS it takes GB of dataset training but the models it produces that people use are relatively tiny the ‘visual’ pb model is 1.5mb.
PS found another promising Pi KWS tensorflow repo.
Really good as if you check the above a series of tutorials and videos accompany it.
I have to say once more Linto is looking really good as everything I have been thinking of I keep finding Linto have already done it 6 months to a couple of years ago.
Started once more to find optimised mfcc libs for the Pi and this has cropped up quite a few times that no longer surprised to find exactly what I was looking for with linto.
I have no idea why those guys don’t have a community portal as it seems a crazy ommision?
They have also gone for a RNN model which I pressume is for reasons listed here.
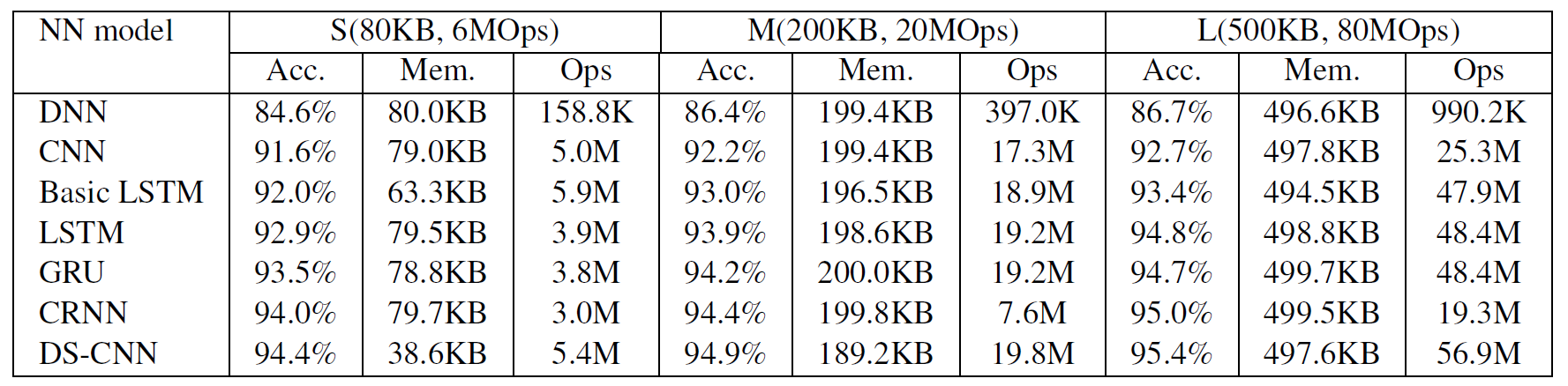
The DS-CNN model does provide the most accuracy but interms of Ops its actually the heaviest.
The CRNN is extremely lite and amlost as good so presuming why as DS-CNN would only seem prefereable in extremely low memory footprints hence why it was used for embedded.
Its probably quite easy to snatch the CRNN model creation from here and apply to the above tensorflow examples.
Install on 18.04 in fact the binary they also offer makes it real easy but the inteface and setting for a Hotword Model Generator are near perefect with maybe just an evolution of further parameters to come.
Even if its not selected because of different KWS use the manner of the App makes a great template for any project to follow,
You can also just point and click to folders if they are a hotword or (not hotword) which makes the dataset side a little easier.
Its also has a test page and you can grab your mic and direct test the model you just made.
The speed of model creation is so fast compared to the tensorflow example I was running I am wondering how its done?
Even if not adopted that is very close to how a model builder app should be.
Maybe could do with some extra MFCC & parameter options but as is, is pretty much complete.