I thnk you can do both now @fastjack
To be honest to to the availbility of technology and what @Bozor said the private services of creating models or hiring TPU slots is getting extremely cheap.
I think you can create a general large model and also custom training to that large general model that will be processed on a cloud server in minutes rather than hours on a I7 and forget about it levels on a Pi.
You might even be able to squeeze quite a few models in a single hour and if so the service becomes extremely cheap.
Offer the service on minimum donation as the training update needs to be done only once and maybe occasional updates and even opensource has to cover its running costs.
If it was $5 a pop it would prob also leave some additional funding even though small for storing datasets.
Models are blackboxes and not opensource as without the coding dataset they are closed so its essential to have the datasets.
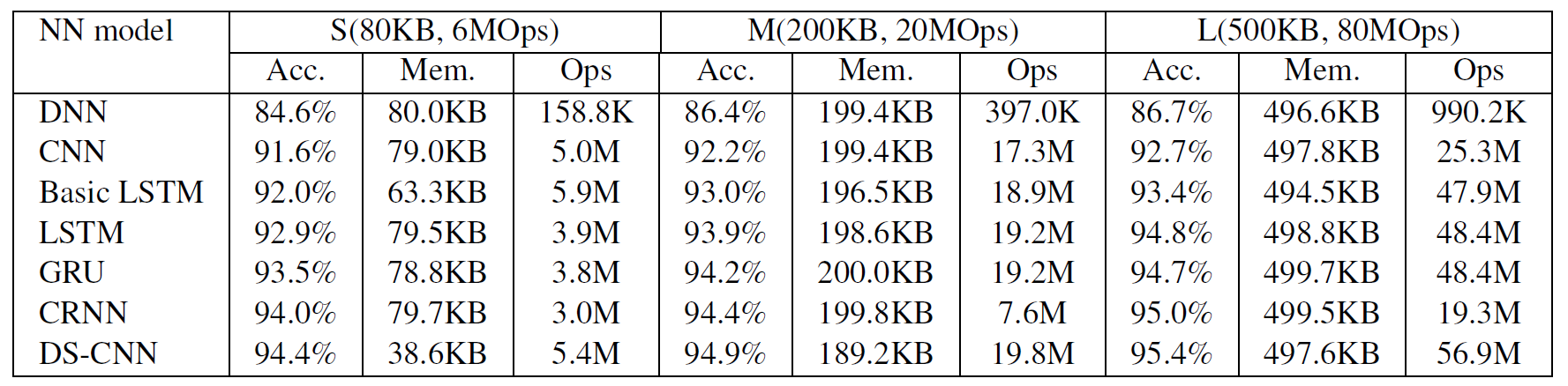
But yeah you could prob also train just a simple specific KWS but also with the advent of cloud TPU you can train general large datasets and supplement with custom training.
They actually need to have set keywords and the use of phonetic based KWS that introduces high complexity, load and model is such a strange avenue to take.
Do you call a dog a cat because you prefer that word?
That article is great and the only thing I noticed and maybe you can do both but think this will create less load.
You don’t need to do audio preemphasis as you can do that via the MFCC creation by raising the log-mel-amplitudes to a suitable power (around 2 or 3) before taking the DCT.
High pass filetering is not all that load intensive but the above is also another solution to removing noise.
In fact you don’t have to do any of that but just import librosa and set the parameters but the action is the same.
That article is really good though and really do think there should be a truly open KWS that has access to datasets as sharing models is akin to closed source.
The false alarm rate of the Snips method is really high though False Alarm rate per Hour is 2.06
When say you compare to Porcupine that has 0.09 FApH
Things have moved very quickly in the AI world and that article when published was pretty cutting edge but aslo some of its content is now quite dated.
Its false alarm rate is extremely dated by many standards now.
But generally KWS is quite simple much of what is in the article is already in libs or frameworks or both.
ASR is complex KWS is fairly easy to accomplish but also the ability to use server farms in cheap slots has change on how we may use AI.
Custom training of use may well become a norm as over all other methods it can drastically increase accuracy.
But going back to datasets as its all about the dataset as any model created with a dataset that was captured with the audio capture system of use will always be more accurate.