I really don’t like the idea 24/7 always on mic WiFi broadcast and been scratching my head for alternatives.
I guess you could get a POE splitter PoE Splitter with MicroUSB Plug - Isolated 12W - 5V 2.4 Amp | The Pi Hut then at least its wired and maybe use a USB ethernet adapter and have a network dedicated to that audio.
You can aliexpress or ebay POE splitters and find them cheaper same with injectors or POE switches.
You can get hats but seem expensive for what they are.
I really like the Esp32-S3 due to its AFE (Audio Front End) but I have never actually listened to what effect it has on the x2 split BSS streams and haven’t managed to get anyone to post a sample.
I also think the ESP32-S3-Box that takes a $7 microcontroller to approx $50 of bloat overkill and it would be great if a simple ADC/DAC for any ESP32-S3 was made avail via Seeed.
Still though Esp32-S3 with its Alexa certified AFE only has the Esspressif KWS and they are not that great or again it would have to be 24/7 broadcast of the x2 BSS streams.
They do say a Pi4 can run multiple instances of OpenWakeWord and maybe its back to the 2 channel or single channel usb soundcard with the Max9814 mic preamp.
Because you do have a preamp you can run quite long mic cables and just have a mic or x2 mics in tiny little enclosures with as many soundcards you can plug into a hub or instances you can run on a Pi4 that is hidden away somewhere.
@donburch For example, a single core of a Raspberry Pi 3 can run 15-20 openWakeWord models simultaneously in real-time.
It does say the above even if I am struggling to believe it…
PS Respeaker 2mic drivers are failing as the kernel headers for the update have not been published yet, dunno why raspberry does this.
I struggled to get the example script to run but using pyaudio in blocking mode maybe.
Anyway replaced with Sounddevice and actually it works really well so far.
# Copyright 2022 David Scripka. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Imports
import sounddevice as sd
import numpy as np
from openwakeword.model import Model
import argparse
import threading
# Parse input arguments
parser=argparse.ArgumentParser()
parser.add_argument(
"--chunk_size",
help="How much audio (in number of samples) to predict on at once",
type=int,
default=1280,
required=False
)
parser.add_argument(
"--model_path",
help="The path of a specific model to load",
type=str,
default="",
required=False
)
parser.add_argument(
"--inference_framework",
help="The inference framework to use (either 'onnx' or 'tflite'",
type=str,
default='tflite',
required=False
)
args=parser.parse_args()
CHANNELS = 1
RATE = 16000
CHUNK = args.chunk_size
sd.default.samplerate = RATE
sd.default.channels = CHANNELS
sd.default.dtype= ('int16', 'int16')
def sd_callback(rec, frames, time, status):
audio = np.frombuffer(rec, dtype=np.int16)
prediction = owwModel.predict(audio)
# Column titles
n_spaces = 16
output_string_header = """
Model Name | Score | Wakeword Status
--------------------------------------
"""
for mdl in owwModel.prediction_buffer.keys():
# Add scores in formatted table
scores = list(owwModel.prediction_buffer[mdl])
curr_score = format(scores[-1], '.20f').replace("-", "")
output_string_header += f"""{mdl}{" "*(n_spaces - len(mdl))} | {curr_score[0:5]} | {"--"+" "*20 if scores[-1] <= 0.5 else "Wakeword Detected!"}
"""
# Print results table
print("\033[F"*(4*n_models+1))
print(output_string_header, " ", end='\r')
# Load pre-trained openwakeword models
if args.model_path != "":
owwModel = Model(wakeword_models=[args.model_path], inference_framework=args.inference_framework)
else:
owwModel = Model(inference_framework=args.inference_framework)
n_models = len(owwModel.models.keys())
# Start streaming from microphone
with sd.InputStream(channels=CHANNELS,
samplerate=RATE,
blocksize=int(CHUNK),
callback=sd_callback):
threading.Event().wait()
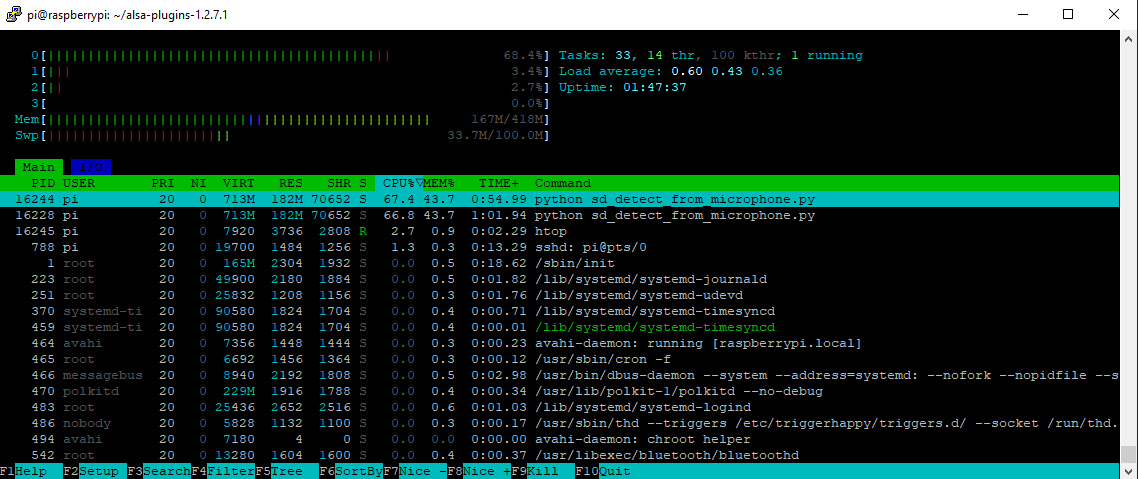
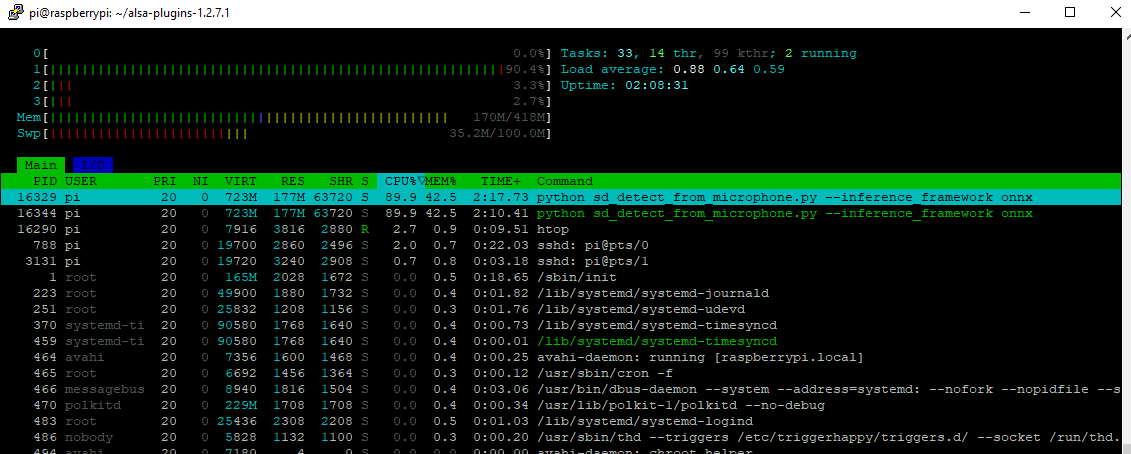
Still though from a single instance
But guess we are not talking instances just multiple KW
Onnx model also works but takes more load so would stay to the tflite model.
@donburch aliexpress do cheap https://www.aliexpress.com/item/1005006017042745.html poe splitters but likely as Pi’s are 5.1v it might undervolt guess just try as you could always snip the cable and bypass the polarity diode and put 5v direct on gpio.