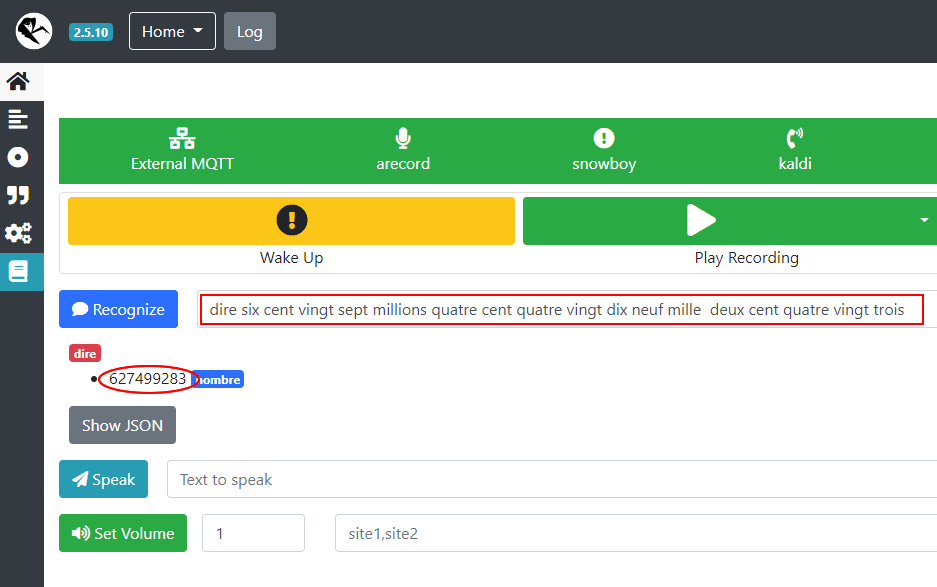
Hello everyone … I hailed myself to the phenomenon of voice recognition of large digits and response times that increase the larger the number is see here and I found a solution that I propose to you: it is based on two functionalities
1 - a custom converter which translates these into “number” text
explanation: we enter two hundred and twenty and we get a string “220”
the custom converter: (file in /profiles/fr/converters/text2num)
#!/usr/bin/env python3
import sys
import json
from text_to_num import text2num
INlst = sys.stdin.readlines()
val=’’.join(INlst)
z=len(INlst)
if z == 0:
print(" “)
quit()
val=val.replace(’”"’,’ ‘)
val=val.replace(‘quatre vingt’,‘quatre-vingt ‘)
val=val.replace(‘dix sept’,’ dix-sept’)
val=val.replace(‘dix huit’,’ dix-huit’)
val=val.replace(‘dix neuf’,’ dix-neuf’)
val=val.replace(’"’,’’)
valnum = text2num(val,‘fr’)
print(str(valnum))
2 - a rules for number in text (in /profiles/fr/intents/Chiffres.ini)
[strchiffres]
deux_9 = ( deux | trois | quatre | cinq | six | sept | huit | neuf )
un_une = ( (un | et un) | (une | et une) )
un_9 = ( <un_une> | <deux_9> )
un_23 = [( <un_9> | <dix_19>)] [ vingt [ (<un_une>| deux| trois)] ]
un_59 = [<diz_1mot>] [( <un_9> | <dix_19> ) ]
dix_19 = ( dix | onze | douze | treize | quatorze | quinze | seize | dix sept | dix huit | dix neuf )
diz_1mot = ( vingt | trente | quarante | cinquante | soixante )
diz_2mot = ( soixante dix | quatre vingt )
un_100 = [ (<diz_2mot>| <diz_1mot>) ] [(<un_9> | <dix_19>) ]
cent = cent
mille = mille
million = million
nombre = [ [ <un_9> ] <cent> ] [ [ <un_100> ] <million> ] [ [ <deux_9> ] <cent> ] [ [ <un_100> ] <mille> ] [ [ <deux_9> ] <cent> ] [ <un_100> ]
You just have to create an intention like for example:
[setValeur]
valeur <strchiffres.nombre> {text2num!text2num}
That’s it … if it can help a few
cordially
Arpagor
Been there done that.
1 can be done with a number of tools (duckling, rustling, rasa, text2num) and work quite well (I’m using my own Node native binding for Rustling to do this).
2 is more complicated. It has the potential to unbalance the language model and stear transcriptions toward strange results. Use with caution. To avoid this you can use the « text_fst » language model type. It should help a bit.
Cheers
Thank you for your comments, but I will clarify:
1 - I am already using the Language Model Type “Text FST” option in Kaldi
2 - Similarly my converter uses Text2Num as you suggest
3 - Can you explain to me the remarks “it’s more complicated” and “it risks unbalancing the language model”
because everything happens at the NLU stage and if we compare the INTENT Json for
[setVolume]
set Volume (0…100) {volume}
and
[setValue]
set Value <strdigits.number> {value! text2num}
in the end after conversion the result of INTENT Json are stictly identical
Being French we have a syntax which is specific for the numbers which agree to the masculine / feminine example:
vingt et “une” pommes
vingt et “un” mille pommes
not to mention the response times when you want values> 100,000!
for a range (1…1000) -> more than 15 sec of trainning and langague_model.txt goes from 39 KB to 2567 KB
cordially
Arpagor
It should work nicely using the text_fst language model type.
Just wanted to point that out because using the arpa type (which was the only option at the time I did this) will tip the language model toward more frequent words series.
In arpa mode, as the rule repeats a lot of « et un | et une », the probability of having « un » or « une » after « et » is increased to a point where it is so high the decoder kind of always ears it whatever the real word is. Same goes for other frequent words repetition in the dataset.
Using arpa allows for more flexibility but comes at the price of possibly unbalanced language model.
Using text_fst avoid this but at the cost of more rigid transcriptions. It does not allow any transcription that was not defined in the language model.
yes I completely agree and that’s why I had validated the Text FST option of kaldi
but for large numbers> 99999 the option (1…10000) is in my opinion too expensive in resources hence my study to finalize a converter which is much less greedy!
if I go to (0…10000) the language_modele.txt file goes from 1660 to 96.474 lines (2.567 KB)
and if I test (0…100000) we go to 1.085.674 lines (31.239Ko), 6 min 45 sec for training and 10 sec to respond to the intention “value 100000”
with the converter it’s almost instantaneous.
1 Like
The grammar you provided seems to only handle numbers from 0 to 100. Have you pushed it to higher maximum values?
What was the impact on training and decoding time (as comparing it to the 0…100000 format would then be incorrect)?
EDIT: Looking at the rule again, I think it just miss the <cent>, <mille> and <million> rules. It should not impact the perfs that much.

My rule covers up to 999 million 999 thousand 999 -> almost instantaneous response
nombre = [ [ <un_9> ] <cent> ] [ [ <un_100> ] <million> ] [ [ <deux_9> ] <cent> ] [ [ <un_100> ] <mille> ] [ [ <deux_9> ] <cent>] [ <un_100> ]
Sorry the words <million> , <mille> and <cent> had disappeared due to being between <> (I added a “\” to make them appear!)
I could add billions etc … 
small improvement of the numbers rule:
[strchiffres]
un_une = ( (un | et un) | (une | et une) )
un_9 = ( <un_une> | <deux_9> )
deux_9 = ( deux | trois | quatre | cinq | six | sept | huit | neuf )
un_23 = [( <un_9> | <dix_19>)] [ vingt [ (<un_une>| deux| trois)] ]
un_59 = [<diz_1mot>] [( <un_9> | <dix_19> ) ]
dix_19 = ( dix | onze | douze | treize | quatorze | quinze | seize | dix sept | dix huit | dix neuf )
diz_1mot = ( vingt | trente | quarante | cinquante | soixante )
diz_2mot = ( soixante dix | quatre vingt )
un_100 = [ (<diz_2mot>| <diz_1mot>) ] [(<un_9> | <dix_19>) ]
nombre = [ [ <un_9> ] ( cent | cents ) ] [ [ <un_100> ] (million | millions) ] [ [ <deux_9> ] ( cent | cents ) ] [ [ <un_100> ] (mille) ] [ [ <deux_9> ] ( cent | cents ) ] [ <un_100> ]
Cordially
Arpagor
2 Likes
Following the modification in Rhasspy_2.5.10 here is the updated version of the converter
#!/usr/bin/env python3
import sys
import json
from text_to_num import text2num
INlst = sys.stdin.readlines()
val=’’.join(INlst)
z=len(INlst)
if z == 0:
print(" “)
quit()
val=val.replace(’”"’,’ ‘)
val=val.replace(‘quatre vingt’,‘quatre-vingt ‘)
val=val.replace(‘dix sept’,’ dix-sept’)
val=val.replace(‘dix huit’,’ dix-huit’)
val=val.replace(‘dix neuf’,’ dix-neuf’)
val=val.replace(’"’,’’)
val=val.replace(’,’,’’)
val=val.replace(’[’,’’)
val=val.replace(’]’,’’)
valnum = text2num(val,‘fr’)
print(str(valnum))
cordially
Arpagor
sorry the management of the comma has changed !!
here is the modified and correct converter
#! / usr / bin / env python3
import sys
import json
from text_to_num import text2num
INlst = sys.stdin.readlines ()
val = ‘’. join (INlst)
z = len (INlst)
if z == 0:
print (" “)
Quit()
val=val.replace(’[’,’’)
val=val.replace(’]’,’’)
val=val.replace(’"’,’’)
val=val.replace(’,’,’’)
val=val.replace(‘quatre vingt’,‘quatre-vingt’)
val=val.replace(‘dix sept’,‘dix-sept’)
val=val.replace(‘dix huit’,‘dix-huit’)
val=val.replace(‘dix neuf’,‘dix-neuf’)
valnum = text2num (val, ‘fr’)
print (str (valnum))
Arpagor
Hi @arpagor62970
Thanks for you converter! The sentence [strchiffres] worked fine.
However, where should we create the python script, and how to load it to Rhasspy?
As stated in the documentation:
you must place the python script in the converters directory
IMPORTANT without extension (without .py)

Arpagor
1 Like
Hi @arpagor62970 , thanks for your help
It is getting to the right direction. I am using Rhasspy with docker, it seems that the file is recognized by Rhasspy. However, some permissions are still missing. I tried chmod +x, chmod 777, but seems not to be enough unfortunately
With me everything is in pi user !!!
I will test under docker and I will keep you informed
Arpagor
Actually, the problems was the python script, it was not correctly formatted and I didn’t have the text2num python package. I couldn’t install it to rhasspy so I edited your script a bit! Thanks again!
By the way, instead of reading all lines, I did the following (you don’t need to replace any characters afterwards). Maybe it could help on your script to read data as well
read = json.load(sys.stdin)
value = ''
if type(read) is list:
value = ' '.join(read)
else:
value = read
In fact I had not used the read function because in version <2.5 sending data to STDIN was buggy and did not respect the format see here and since 2.5.10 synesthesiam corrected the bug and so I just added the 3 lines to remove the brackets and commas to become compatible with 2.5.10 again … but now I can put the json back .load + join …
Thank you for your remark
Arpagor
following the remarks of bezbez1 here is the last update of the converter compatible version 2.5.10:
#!/usr/bin/env python3
import sys
import json
from text_to_num import text2num
INlst = json.load(sys.stdin)
value = ‘’
if type(INlst) is list:
val = ’ '.join(INlst)
else:
val = read
z=len(INlst)
if z == 0:
print(" ")
quit()
val=val.replace(‘quatre vingt’,‘quatre-vingt’)
val=val.replace(‘dix sept’,‘dix-sept’)
val=val.replace(‘dix huit’,‘dix-huit’)
val=val.replace(‘dix neuf’,‘dix-neuf’)
valnum = text2num(val,‘fr’)
print(str(valnum))
Arpagor
1 Like