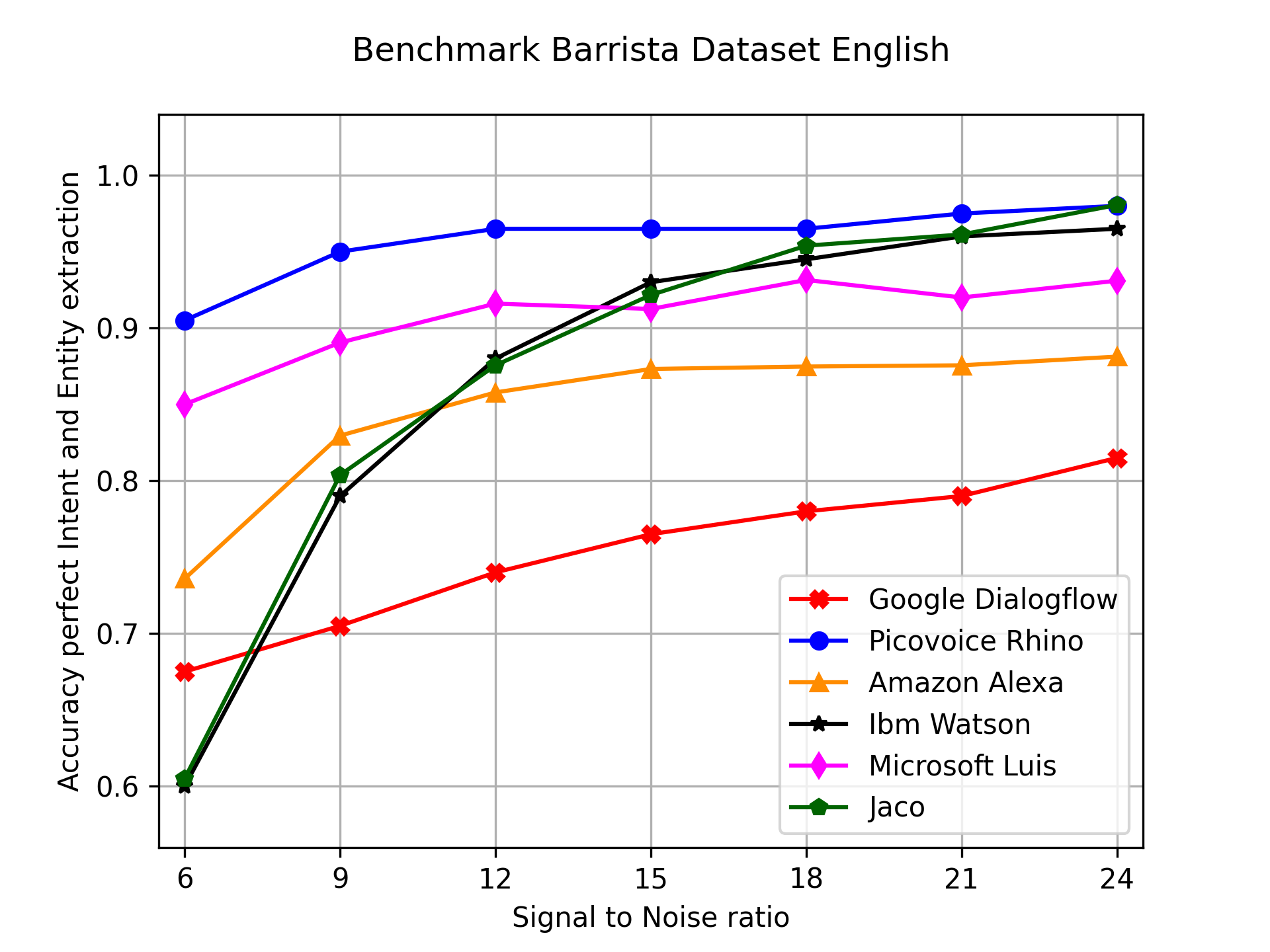
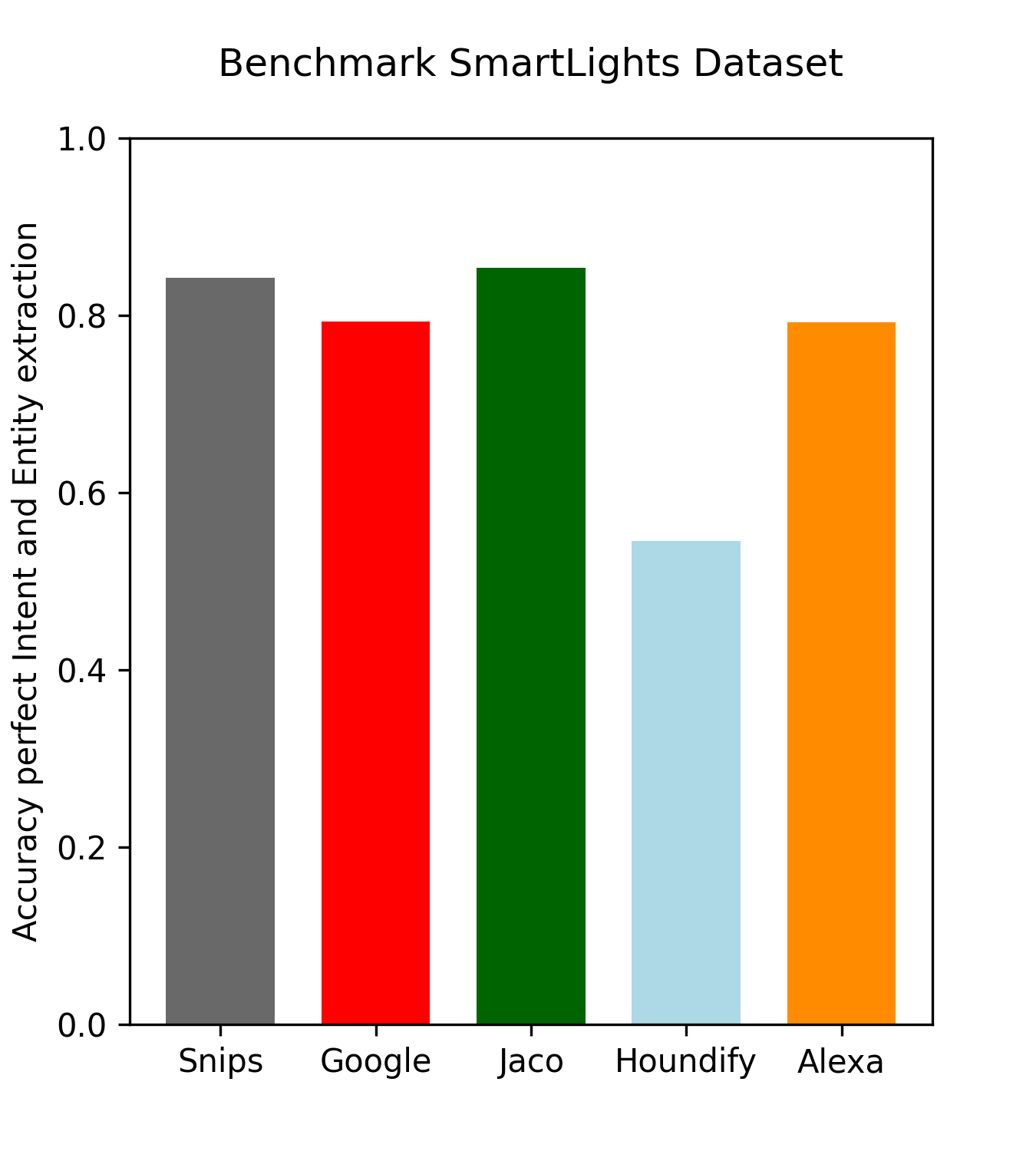
I was quite busy the last weeks, but finally found some time to update Jaco’s dialog syntax.
The syntax is almost similar to the one in my above post. Intents are defined in a nlu.md file like this:
## lookup:city
city.txt
## intent:book_flight
- Book (me|us) a flight from [Augsburg](city.txt?start) to [New York](city.txt?stop)
Entities are defined in an extra file (here city.txt):
Augsburg
(New York|N Y)->New York
Berlin
A longer example can currently (until I merged it) be found here: https://gitlab.com/Jaco-Assistant/Skill-Riddles/-/blob/some_upds/dialog/nlu/de/nlu.md
To train the NLU and STT services, Jaco collects all the dialog files from the installed skills and injects the different entity examples into the utterances. The output consists of two files like this:
# sentences.txt (for STT)
book me a flight from augsburg to new york
book me a flight from augsburg to berlin
book me a flight from berlin to new york
book us a flight from berlin to new york
...
# nlu.json (for NLU)
{
"lookups": {
"skill_flights-city": [
"augsburg",
"(new york|n y)->new york",
...
]
},
"intents": {
"skill_flights-book_flight": [
"book me a flight from [augsburg](skill_flights-city?start) to [new York](skill_flights-city?stop)",
"book me a flight from [augsburg](skill_flights-city?start) to [berlin](skill_flights-city?stop)",
"book me a flight from [berlin](skill_flights-city?start) to [new york](skill_flights-city?stop)",
"book us a flight from [berlin](skill_flights-city?start) to [new york](skill_flights-city?stop)",
...
]
}
}
The sentences.txt file can directly be used to train the language models for DeepSpeech. The nlu.json is afterwards converted to rasa’s train data style.
A sample nlu output for the query book me a flight from augsburg to new york would then look like this:
{
'intent': {
'name': 'skill_flights-book_flight',
'confidence': 1.0
},
'text': 'book me a flight from augsburg to new york',
'entities': [
{
'entity': 'skill_flights-city',
'value': 'augsburg',
'role': 'start'
},
{
'entity': 'skill_flights-city',
'value': 'new york',
'role': 'stop'
}
]
}
What do you think?
And @maxbachmann, do you think you can build a conversion script for your RapidFuzz library?
I would like to benchmark it against rasa then, to check if there is a trade-off between the training duration and recognition performance, and how big it is in that case.