In the next weeks I still have to get my string matching library RapidFuzz to v1.0.0 (getting closer  ) and add SSML support to Rhasspy. Possibly afterwards, but I would not count on it.
) and add SSML support to Rhasspy. Possibly afterwards, but I would not count on it.
(Sorry for the delay in a response. I’m spending a bit less time on the computer during the holidays  )
)
I think this would be a good start; there is a lot of overlap with Rhasspy’s existing format. I would probably keep this “cross-assistant” format separate and just convert it to Rhasspy’s internal format during training.
Can you provide some examples of synonyms? Are these any different than Rasa’s?
Currently the synonyms follow rasa’s format:
## lookup:city
...
## intent:travel_duration
...
##synonym:red
- light red
- dark red
##synonym:blue
- light blue
- dark blue
In my opinion moving the definitions into an extra file (like with the lookup.txt) would improve readability if there are many synonyms.
In this file I would create a simple json structure:
{
"red": ["light red", "dark red"],
"blue": ["light blue", "dark blue"]
}
This is a good approach I think. I would handle this the same way for rasa. This should make switching nlu or stt services quite easy.
1 Like
We could also use another syntax which is quite close to rhasspy’s and define the synonyms directly in the lookup.txt files:
(red|light red|dark red):red
green
yellow
(blue|light blue|dark blue):blue
And I would update the intent’s slot definition a little bit:
## intent:travel_duration
- How long does it take to drive from [Augsburg](city.txt?city_name_1) to [Berlin](city.txt?city_name_2) by (train|car)?
This should make the links which are displayed in the git repository usable.
1 Like
I was quite busy the last weeks, but finally found some time to update Jaco’s dialog syntax.
The syntax is almost similar to the one in my above post. Intents are defined in a nlu.md file like this:
## lookup:city
city.txt
## intent:book_flight
- Book (me|us) a flight from [Augsburg](city.txt?start) to [New York](city.txt?stop)
Entities are defined in an extra file (here city.txt):
Augsburg
(New York|N Y)->New York
Berlin
A longer example can currently (until I merged it) be found here: https://gitlab.com/Jaco-Assistant/Skill-Riddles/-/blob/some_upds/dialog/nlu/de/nlu.md
To train the NLU and STT services, Jaco collects all the dialog files from the installed skills and injects the different entity examples into the utterances. The output consists of two files like this:
# sentences.txt (for STT)
book me a flight from augsburg to new york
book me a flight from augsburg to berlin
book me a flight from berlin to new york
book us a flight from berlin to new york
...
# nlu.json (for NLU)
{
"lookups": {
"skill_flights-city": [
"augsburg",
"(new york|n y)->new york",
...
]
},
"intents": {
"skill_flights-book_flight": [
"book me a flight from [augsburg](skill_flights-city?start) to [new York](skill_flights-city?stop)",
"book me a flight from [augsburg](skill_flights-city?start) to [berlin](skill_flights-city?stop)",
"book me a flight from [berlin](skill_flights-city?start) to [new york](skill_flights-city?stop)",
"book us a flight from [berlin](skill_flights-city?start) to [new york](skill_flights-city?stop)",
...
]
}
}
The sentences.txt file can directly be used to train the language models for DeepSpeech. The nlu.json is afterwards converted to rasa’s train data style.
A sample nlu output for the query book me a flight from augsburg to new york would then look like this:
{
'intent': {
'name': 'skill_flights-book_flight',
'confidence': 1.0
},
'text': 'book me a flight from augsburg to new york',
'entities': [
{
'entity': 'skill_flights-city',
'value': 'augsburg',
'role': 'start'
},
{
'entity': 'skill_flights-city',
'value': 'new york',
'role': 'stop'
}
]
}
What do you think?
And @maxbachmann, do you think you can build a conversion script for your RapidFuzz library?
I would like to benchmark it against rasa then, to check if there is a trade-off between the training duration and recognition performance, and how big it is in that case.
1 Like
I’ll take a look tomorrow, @DANBER. Thanks for the update!
I’ve been busy as well trying to improve the performance of Larynx (TTS) and train more Kaldi models. I’d like to talk to you at some point about expanding the language support in DeepSpeech-Polyglot. I’m curating datasets, and have GPUs available for training.
I would recommend we wait a few weeks with that, I’ve been working on improving the performance here, but it’s not yet finished.
Generally it’s very easy to add support for new languages, you just have to add a new alphabet and extend the preprocessing rules here: https://gitlab.com/Jaco-Assistant/deepspeech-polyglot/-/blob/master/data/langdicts.json
With the upcoming changes I will update the datasets .csv format a little bit, but there is already an importer for the old DeepSpeech format. The content in langdicts.json stays the same.
If your datasets are public, it would be great if you could add them to the corcua library, where I already did collect a lot of German and multilingual datasets:
Seems that your days are quite long, don’t forget to sleep for some hours in between 
1 Like
My days are quite long
Really, though, I just have too many things I’m trying to do at once.
I’ve written a rudimentary converter from your proposed format to Rhasspy’s ini format. It should be pretty easy to turn it into a command-line tool that can convert a set of Jaco skills.
Are the ## lookup: sections needed anymore if the entity links use the file names (city.txt)?
Sounds familiar to me 
Not necessarily, but I did keep them for a better overview in the web readme, you don’t see the entity names there, if you don’t hover over the links.
Now it’s finished:)
The project got a new name: Scribosermo and now can be found here:
The new models can be trained very fast (~3 days on 2x1080Ti to reach SOTA in German) and with comparatively small datasets (~280h for competitive results in Spanish). Using a little bit more time and data, the following Word-Error-Rates on CommonVoice testset were achieved:
| German | English | Spanish | French |
|---|---|---|---|
| 7.2 % | 3.7 % | 10.0 % | 11.7 % |
Training is even simpler than with DeepSpeech before and adding new languages is easy as well. After training, the models can be exported into tflite-format for easier inference. They are able to run faster than real-time on a RaspberryPi-4.
Only downside is that the models can’t be directly integrated into DeepSpeech bindings (technical possible, but I had no need for it) and doesn’t support streaming anymore (at least until someone has the time to implement it). I don’t think the missing streaming feature should be a problem, because our inputs are quite short, they usually are processed in 1-2 seconds on a Raspi.
1 Like
I already did update Jaco and run the benchmarks again, which show that the new models perform really well:
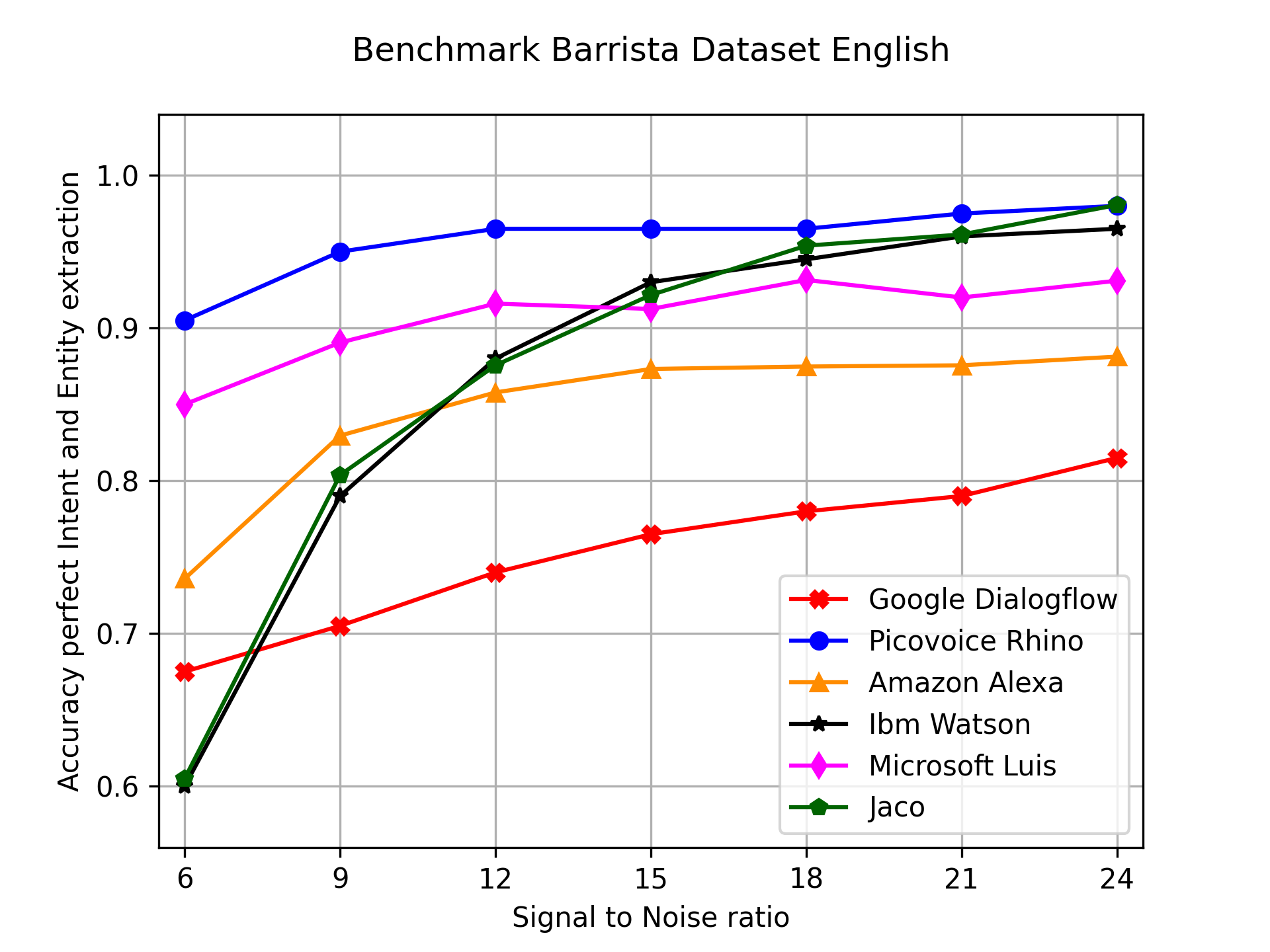
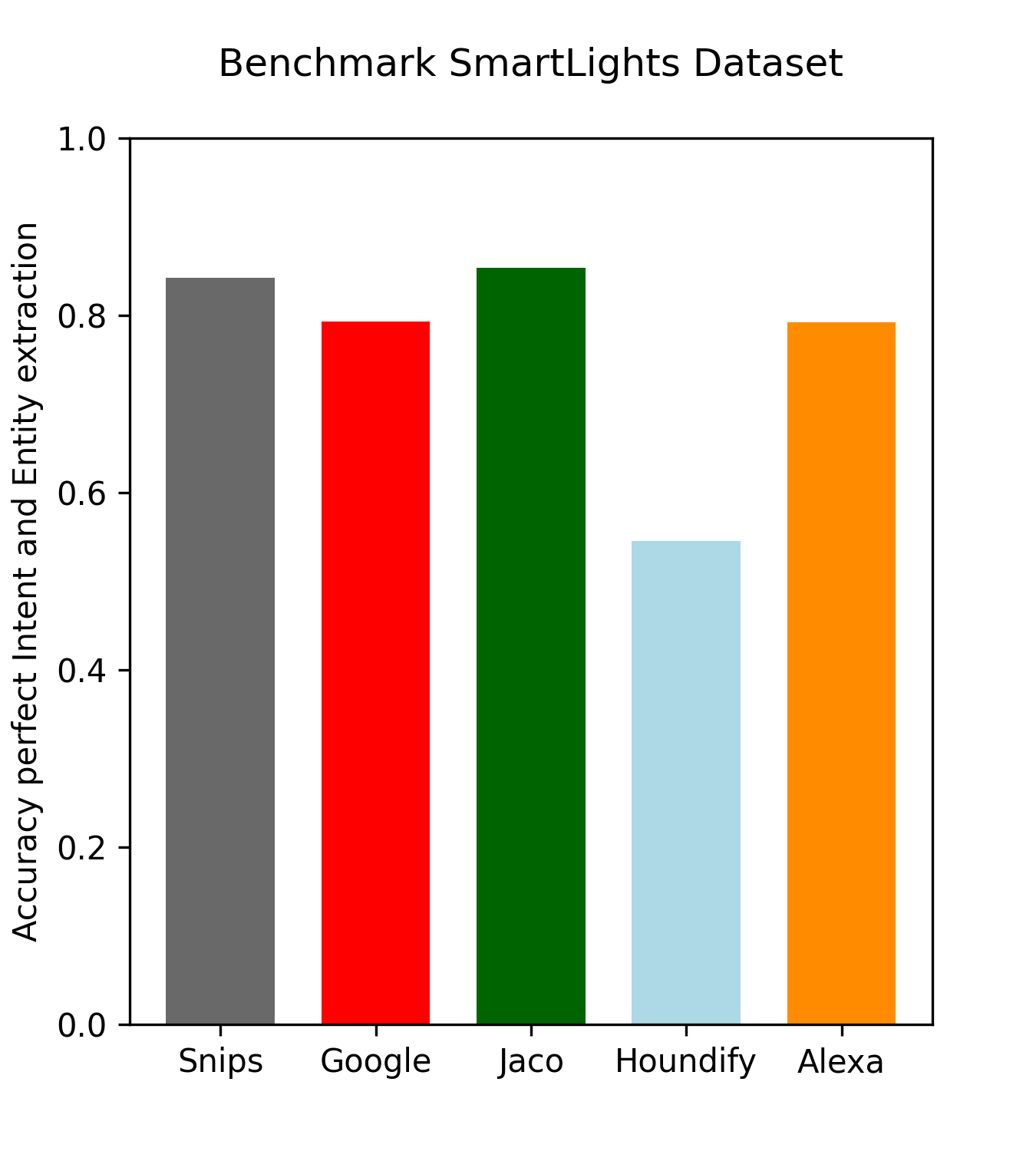
@maxbachmann, if you have some free time left, I have an idea for a project, where your experience with RapidFuzz might be helpful.
Currently the different STT modules of Jaco and Rhasspy are using n-gram language models (in form of arpa or scorer files), which are based on plain sentences, to improve the predictions.
With the recent update of Jaco’s STT network to Scribosermo, the base-line performance of the model is much better than the Kaldi model which was used in Snips. But in above SmartLights benchmark the recognition performance of Jaco is only slightly better than the one of Snips.
I think we should be able to improve the performance further if we replace the n-gram language model with a more task specific language model. In the Snips paper (https://arxiv.org/pdf/1810.12735.pdf) a combination of a n-gram model with a pattern-based model is described, which I think would be a good idea to start with.
In general this would replace the training sentences “turn on the light in the kitchen” and “turn on the light in the living room” with “turn on the light in the [ROOM]” . The resulting sentence can be used to build a n-gram model (which should be much smaller than before) and for the ROOM slot an extra matcher would be required.
The input into such a model would be in our case the direct output of the STT models. In the case of CTC-based STT models (Scribosermo, DeepSpeech, and I think Kaldi too) this would be, before rescoring with a LM, letter based probabilities for a specific time step. The word “hello” might look like this: “hhellll-lllllllooooo” (using the letter with highest probability for each time step). To get the original text, letters with multiple occurrences have to be merged to a single letter, and then the blank-symbol (-) is removed.
What do you think?
I have absolutely no idea about machine learning, so I am probably unable to help you on that. For the character deduplication I would personally try to go with a relatively naive implementation first and see whether it is fast enough. It could probably be improved performance wise using a concept similar to https://lemire.me/blog/2017/04/10/removing-duplicates-from-lists-quickly/ if it is really required.
This wouldn’t require any knowledge of machine learning, but experience in fast C++ implementations for text based problems:)
Merging “hhellll-lllllllooooo” to “hello” and combining it with a n-gram language model is already solved, for example by DeepSpeech’s ds-ctcdecoder. What I didn’t find is a library that can work with slot patterns like ROOM.
There are some papers/libraries which combine regex with edit distance measurements like the Levenshtein distance. See e.g. https://github.com/laurikari/tre
Very impressive! I will see if I can train a new model using Scribosermo
A few questions:
- Do you think accuracy could be improved using phonemes instead of orthographic characters?
- Would streaming require significant changes to the Quartznet architecture?
For Kaldi, Rhasspy also supports directly generating an FST with all of the possible sentences. This is the default, and is actually faster and more accurate than an n-gram language model. The downside, of course, is that it can never recognize sentences outside of the training set.
This sounds very close to Kaldi’s grammars, which you’re probably already familiar with. Instead of rolling our own, I wonder if we could take the output phoneme probability distributions from your DeepSpeech models and run them through a modified Kaldi FST. This would essentially swap out the acoustic model layer of Kaldi with DeepSpeech, but leave the rest intact.
Another idea I’ve had is to use a GPT-2 model in place of a traditional n-gram language model. GPT-2 is far better at tracking long-range dependencies, and may be fast enough to use as a DeepSpeech scorer. Some big challenges are:
- How can the model be tuned quickly for a specific domain?
- Can new models be reasonably trained for other languages?
- Are separate slots possible (e.g., “turn on the light in the [ROOM]”)?
No, that shouldn’t be very complicated, Nvidia already did implement an example script here, but I found that recognition is fast enough that you wouldn’t notice a great speedup with streaming.
It might be, but most of the recent STT papers use graphemes (letters) directly, so I’m not sure about that. Some use a subword approach instead of single characters, which seems to bring a small improvement.
If you want to experiment with that, you would need to retrain the English network, I did use the one published by Nvidia, which made training much easier…
And I think that we will get more performance improvement per invested development time if we optimize the language model rescoring and the nlu extraction.
Oh, didn’t know about that, never trained a model with Kaldi, will take a look into it …
That sounds interesting, but as you already mentioned in your challenges, this has to be fast enough to be trained on a Raspi, that we can build domain/skill specific models directly on the device.
1 Like
This seems to be what Snips used. @fastjack has pointed me to the kaldi-active-grammars project, which uses them to do dynamic decoding.
If we went with this approach, we could pre-generate grammars for numbers, dates, etc. like Snips did and stitch them into the final graph at runtime.
2 Likes