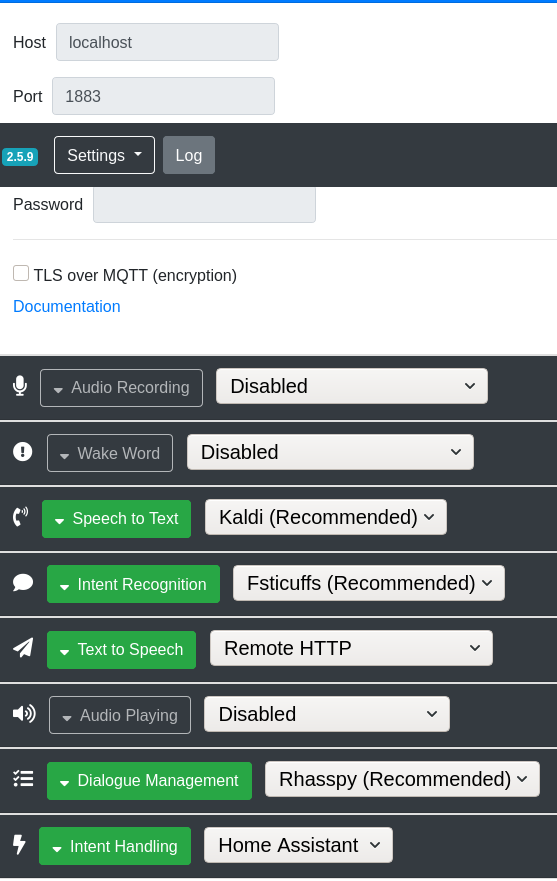
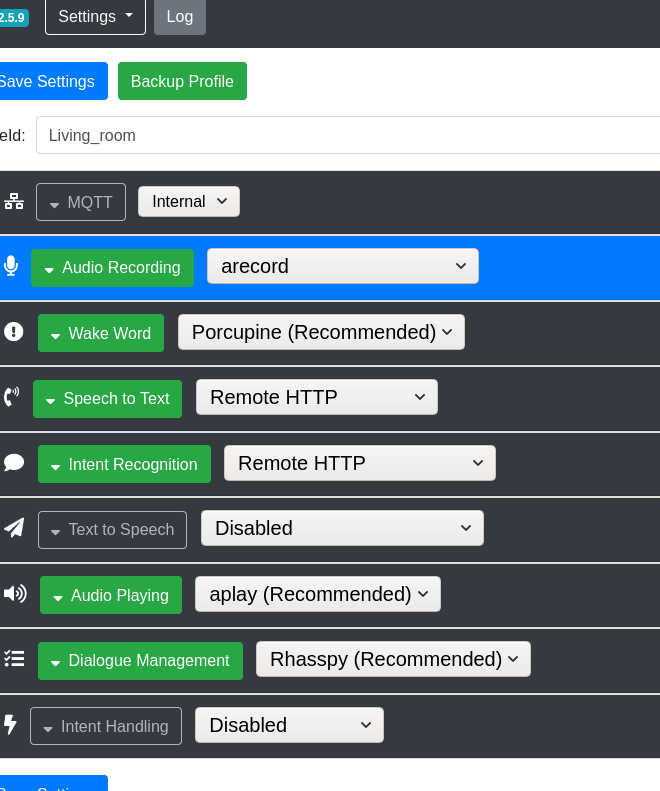
I have a setup with Rhasspy addon on Home Assistant and a Satellite Rhasspy with mic and speaker. Intents are handled by Home Assistant and are working and I can see the response coming back to my Satellite. I want to have TTS running on Satellite but am not hearing audio, even though audio works when I say the wake up word. I see in the log audiotoggleoff, I am assuming this is the culprit.
[DEBUG:2021-03-25 22:02:14,849] rhasspydialogue_hermes: Recognized NluIntent(input='what time is it', intent=Intent(intent_name='GetTime', confidence_score=1.0), site_id='Living_room', id=None, slots=[], session_id='Living_room-blueberry_raspberry-pi-380ac37b-93a8-4e62-bba3-486acc77bed8', custom_data=None, asr_tokens=[[AsrToken(value='what', confidence=1.0, range_start=0, range_end=4, time=None), AsrToken(value='time', confidence=1.0, range_start=5, range_end=9, time=None), AsrToken(value='is', confidence=1.0, range_start=10, range_end=12, time=None), AsrToken(value='it', confidence=1.0, range_start=13, range_end=15, time=None)]], asr_confidence=None, raw_input='what time is it', wakeword_id='blueberry_raspberry-pi', lang=None)
[DEBUG:2021-03-25 22:02:14,866] rhasspyserver_hermes: -> AudioToggleOff(site_id='Living_room')
[DEBUG:2021-03-25 22:02:14,868] rhasspyserver_hermes: Publishing 25 bytes(s) to hermes/audioServer/toggleOff
[DEBUG:2021-03-25 22:02:14,871] rhasspyserver_hermes: -> TtsSay(text='Time Intent worked from Home Assistant', site_id='Living_room', lang=None, id='5e7a4104-8335-4192-8a70-6fea3710af88', session_id='', volume=1.0)
[DEBUG:2021-03-25 22:02:14,875] rhasspyspeakers_cli_hermes: <- AudioToggleOff(site_id='Living_room')
[DEBUG:2021-03-25 22:02:14,877] rhasspyserver_hermes: Publishing 167 bytes(s) to hermes/tts/say
[DEBUG:2021-03-25 22:02:14,877] rhasspyspeakers_cli_hermes: Disabled audio
[ERROR:2021-03-25 22:02:37,524] rhasspydialogue_hermes: Session timed out for site Living_room: Living_room-blueberry_raspberry-pi-380ac37b-93a8-4e62-bba3-486acc77bed8
[DEBUG:2021-03-25 22:02:37,527] rhasspydialogue_hermes: -> AsrStopListening(site_id='Living_room', session_id='Living_room-blueberry_raspberry-pi-380ac37b-93a8-4e62-bba3-486acc77bed8')
[DEBUG:2021-03-25 22:02:37,528] rhasspydialogue_hermes: Publishing 113 bytes(s) to hermes/asr/stopListening
[DEBUG:2021-03-25 22:02:37,536] rhasspydialogue_hermes: -> DialogueSessionEnded(termination=DialogueSessionTermination(reason=<DialogueSessionTerminationReason.TIMEOUT: 'timeout'>), session_id='Living_room-blueberry_raspberry-pi-380ac37b-93a8-4e62-bba3-486acc77bed8', site_id='Living_room', custom_data='blueberry_raspberry-pi')
[DEBUG:2021-03-25 22:02:37,536] rhasspydialogue_hermes: Publishing 191 bytes(s) to hermes/dialogueManager/sessionEnded
[DEBUG:2021-03-25 22:02:37,542] rhasspydialogue_hermes: -> HotwordToggleOn(site_id='Living_room', reason=<HotwordToggleReason.DIALOGUE_SESSION: 'dialogueSession'>)
[DEBUG:2021-03-25 22:02:37,543] rhasspydialogue_hermes: Publishing 54 bytes(s) to hermes/hotword/toggleOn
[DEBUG:2021-03-25 22:02:37,562] rhasspyremote_http_hermes: <- AsrStopListening(site_id='Living_room', session_id='Living_room-blueberry_raspberry-pi-380ac37b-93a8-4e62-bba3-486acc77bed8')
[DEBUG:2021-03-25 22:02:37,563] rhasspyremote_http_hermes: <- AsrStopListening(site_id='Living_room', session_id='Living_room-blueberry_raspberry-pi-380ac37b-93a8-4e62-bba3-486acc77bed8')
[WARNING:2021-03-25 22:02:37,564] rhasspyremote_http_hermes: Session not found for Living_room-blueberry_raspberry-pi-380ac37b-93a8-4e62-bba3-486acc77bed8
[DEBUG:2021-03-25 22:02:37,568] rhasspywake_porcupine_hermes: <- HotwordToggleOn(site_id='Living_room', reason=<HotwordToggleReason.DIALOGUE_SESSION: 'dialogueSession'>)
[DEBUG:2021-03-25 22:02:37,569] rhasspywake_porcupine_hermes: Enabled
[DEBUG:2021-03-25 22:02:37,579] rhasspywake_porcupine_hermes: Receiving audio
[DEBUG:2021-03-25 22:02:44,911] rhasspyserver_hermes: -> AudioToggleOn(site_id='Living_room')
[DEBUG:2021-03-25 22:02:44,912] rhasspyserver_hermes: Publishing 25 bytes(s) to hermes/audioServer/toggleOn
[ERROR:2021-03-25 22:02:44,916] rhasspyserver_hermes:
Traceback (most recent call last):
File "/usr/lib/rhasspy/usr/local/lib/python3.7/site-packages/quart/app.py", line 1821, in full_dispatch_request
result = await self.dispatch_request(request_context)
File "/usr/lib/rhasspy/usr/local/lib/python3.7/site-packages/quart/app.py", line 1869, in dispatch_request
return await handler(**request_.view_args)
File "/usr/lib/rhasspy/rhasspy-server-hermes/rhasspyserver_hermes/__main__.py", line 1700, in api_text_to_speech
results = await asyncio.gather(*aws)
File "/usr/lib/rhasspy/rhasspy-server-hermes/rhasspyserver_hermes/__main__.py", line 1686, in speak
volume=volume,
File "/usr/lib/rhasspy/rhasspy-server-hermes/rhasspyserver_hermes/__init__.py", line 599, in speak_sentence
handle_finished(), messages, message_types
File "/usr/lib/rhasspy/rhasspy-server-hermes/rhasspyserver_hermes/__init__.py", line 971, in publish_wait
result_awaitable, timeout=timeout_seconds
File "/usr/lib/rhasspy/usr/local/lib/python3.7/asyncio/tasks.py", line 449, in wait_for
raise futures.TimeoutError()
concurrent.futures._base.TimeoutError
[DEBUG:2021-03-25 22:02:44,921] rhasspyspeakers_cli_hermes: <- AudioToggleOn(site_id='Living_room')
[DEBUG:2021-03-25 22:02:44,923] rhasspyspeakers_cli_hermes: Enabled audio
Living_room is the satellite rpi