This week OpenAI released their Whisper speech-to-text hosted API. I’ve previously experimented with hosting Whisper locally but it was too slow on my CPU. (See previous discussion)
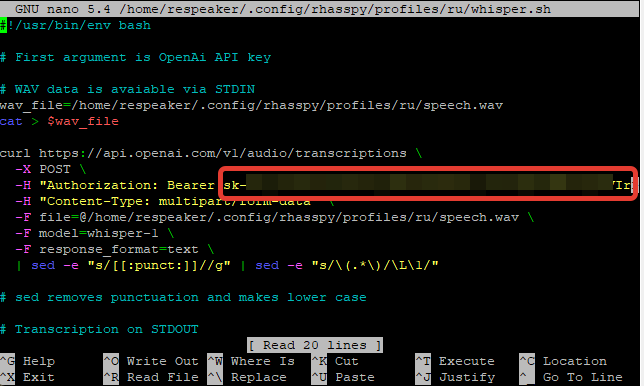
To test out the API I wrote a script to send the speech to OpenAI:
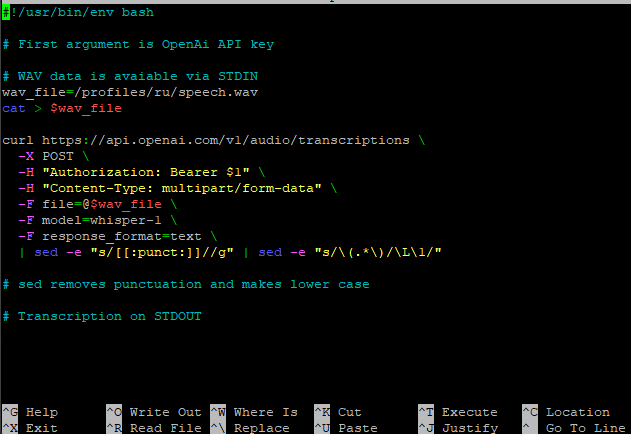
#!/usr/bin/env bash
# First argument is OpenAi API key
# WAV data is avaiable via STDIN
wav_file=/profiles/en/speech.wav
cat > $wav_file
curl https://api.openai.com/v1/audio/transcriptions \
-X POST \
-H "Authorization: Bearer $1" \
-H "Content-Type: multipart/form-data" \
-F file=@$wav_file \
-F model=whisper-1 \
-F response_format=text \
| sed -e "s/[[:punct:]]//g" | sed -e "s/\(.*\)/\L\1/"
# sed removes punctuation and makes lower case
# Transcription on STDOUT
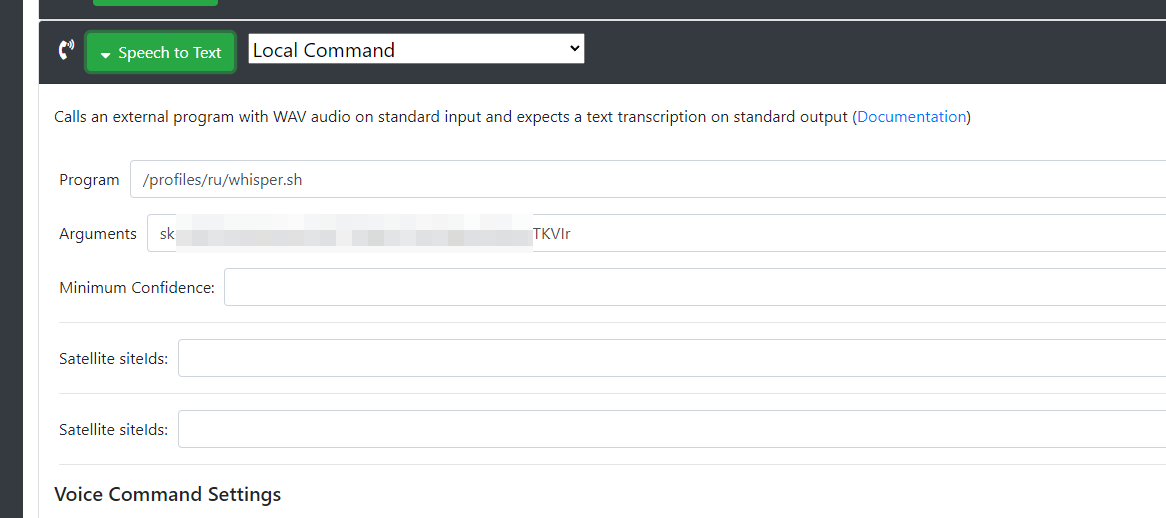
Create a file called whisper.sh in en/ profile. When you create the file don’t forget to chmod +x whisper.sh to make the file executable.
Then in Rhasspy settings, under Speech to Text choose Local Command. In Program paste /profiles/en/whisper.sh and in Arguments paste in your OpenAI API key.
Save and restart Rhasspy.
So far the speech recognition has been good, and latency is acceptable. Hopefully the speech recognition is much better than DeepSpeech / Vosk / Kaldi especially in my noisy kitchen.
I would prefer that my entire setup ran locally, but using the API is a quick way to test if I want to invest more time in making a local version of Whisper faster.
Given the Whisper is something you can run locally (OpenAI has published it back in Oct-Dec last year) it would be much more interesting to see someone will invest his time to extend the Rhasspy docker image to have it as one of the SST engines right out of the box.
It’s also worth to mention, there’s a project by a talented guy Georgi Gerganov called “Whisper.cpp” (GitHub - ggerganov/whisper.cpp: Port of OpenAI's Whisper model in C/C++). To my limited understanding, it’s using the same trained model (basically pretty same files with weights) from OpenAI’ Whisper, but the actual implementation is on C++ instead of Python, which should be performing better on a underpowered PCs or SBCs
tl;dr I will continue using Whisper because it’s much better in echoy/noisy environments.
Overall, I am very happy with the performance. Equally as good as Google Assistant / Google Nest devices, and far better than the built in ASR (Kaldi, DeepSpeech, Vosk.) My kitchen has a lot of echo, and when it’s busy (microwave, extractor fan) the speech-to-text would fail unless I was < 0.5 m from the mic. Now I can be 2-3 m away and it works fine.
The API performance is fine, too. Not noticeably slower than running the large ASR models locally.
As alx84 said, there are local Whisper models that run on CPU. I tested Whisper.cpp, but the large model was still too slow for realtime. There is also faster-whisper, but I have not tested that, although I believe Rhasspy 3 will support it.
I found that the smaller Whisper models incorrectly transcribed short utterances (“activate relax”), maybe because there was not enough context, or the training data was from podcasts and videos, not voice assistants? However with the API (running the largest model?) I have not had any issues.
The primary difference between the two is that the 510 has Bluetooth and the 410 does not. I do not use the Bluetooth, but I guess you could have the speaker in a room and e.g. the Pi somewhere else within Bluetooth range. That way the speaker could be on a coffee table and still look neat. Not sure Bluetooth is stable enough long term, and linux sound config is frustrating enough without adding Bluetooth into the mix.
The nice thing about a conference speaker is even with music playing it still detected voice fine. When playing back the recorded voice wav file I can barely hear the music even though it was 50% volume. The hardware does a good job of removing audio played over the speaker, as a good conference speaker should.
Downside is the speaker is not great for music – it’s designed for voice frequencies.
I’m not sure how familiar you are with Rhasspy, forgive me if I am exlaining things you already know.
Home Assistant has an addon for Rhasspy. See Rhasspy - Home Assistant This will allow Home Assistant to “handle intents” for controlling your home.
If you want a custom intent handler, you can use Node-RED. Have a look at Rhasspy “Intent Handling”, you can use Home Assistant, http (a web hook), or local command (a shell script, pyton program, …)
For Rhasspy to activate when you say the “wake word” like “chatGPT” you’ll need to program your own wake word. Rhasspy has built in wake words like “hey mycroft”, “porcupine”, etc. To use a csutom wake word you’ll need to train one. You can do this online using picovoice.
In Rhasspy settings - wake word: I’ve had the most success with Mycroft Precise and hey-mycroft-2.
I’d suggest following the Rhasspy getting started tutorials and get a solid working foundation using mostly the defaults, before adding complexity with custom wake words, whisper, chatgpt.
Thanks I’ve used whisper.cpp during work on this: GitHub - hbarnard/mema it’s an experimental setup/project for older people to record memories and photos without a lot of keyboard activity. There’s a partial write up here: Working with the MeMa 3.0 project : Horizon
Anyway, for ‘short stories’ I found I could do real-time transcription on the laptop install but not on Pi4 with Ubuntu. Since this is pretty specialised, I now have a cron on the Pi4 that scoops up current audio recordings and transcribes them as a background task. I have one Orange Pi5 that I haven’t put into service yet, I’ll report on how that goes a little later in the year.
I’ using whisper-rhasspy-http on a more powerful machine in my network to do the speech-to-text locally which technically works pretty good.
I also made a home assistant automation that should take the wakeword_id into account.
The idea is to have one wake word for home automation like “turn the bedroom lights on” and another wake word that passes the transcribed text to the openai api and the result to tts per hermes.
The only problem I have is, that using kaldi with pre trained sentences works much better for intent handling with very few false positives but of course is completely useless for open transcription which is needed for the chatgpt-thing and you can’t have both Using whisper alone for intent recognition on the other hand doesn’t work any good at all because a lot of words are missunderstood.
Oh and having multiple custom wake words is a bit challenging using rhasspy raven as training by 3 samples doesn’t seem to be enough. It either needs a few attempts to wake it up or it wakes up constantly if i’m on the phone
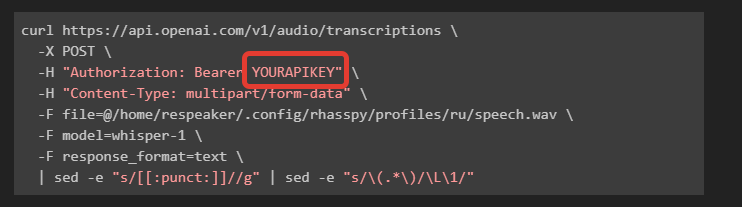
The Program path in Rhasspy looks like it might be incorrect: You have /profiles/ru/whisper.sh, I think it needs to be /home/respeaker/.config/rhasspy/profiles/ru/whisper.sh (the full path to where you have the whisper script)
The shell creates a file called speech.wav. In your shell script try changing wav_file=/profiles/ru/speech.wav to 'wav_file=/home/respeaker/.config/rhasspy/profiles/ru/speech.wav`.
After making these changes, restarting Rhasspy and trying an utterance. If it does not work, see if speech.wav file is created in /home/respeaker/.config/rhasspy/profiles/ru/.
You can also try running the curl command manually from the command line
Oh and having multiple custom wake words is a bit challenging using rhasspy raven as training by 3 samples doesn’t seem to be enough. It either needs a few attempts to wake it up or it wakes up constantly if i’m on the phone
I have been using openWakeWord so that I can have multiple wake-words (and theoretically train custom wake-words.)
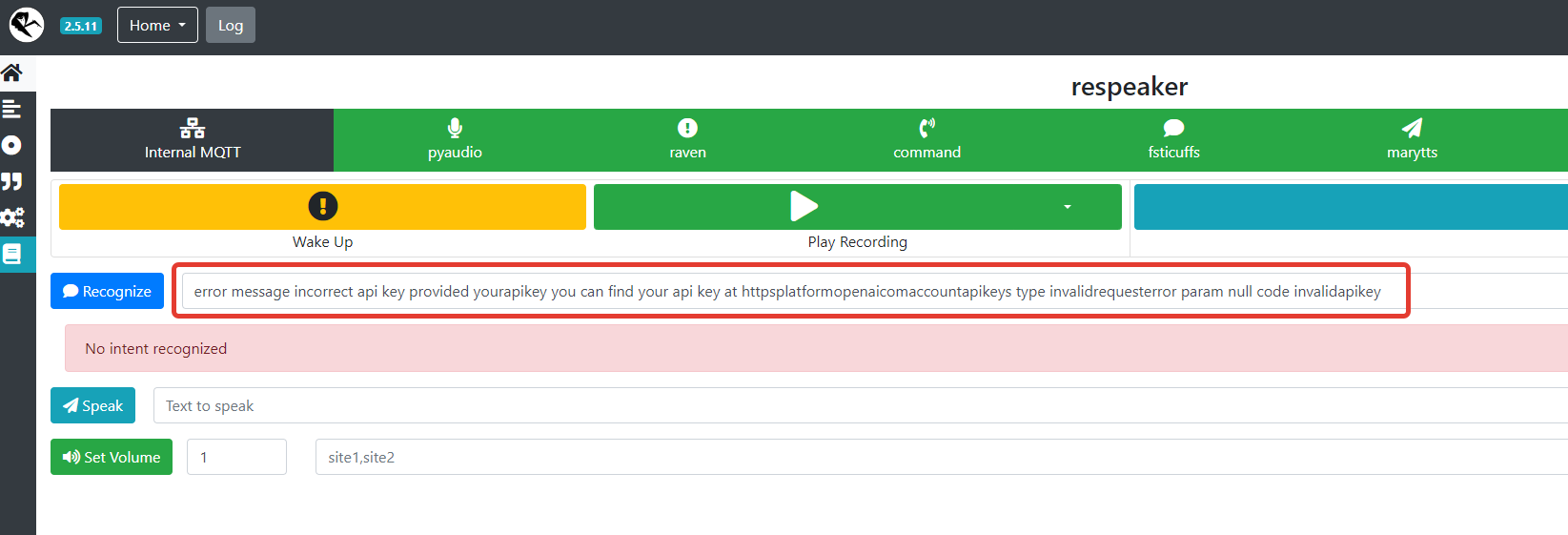
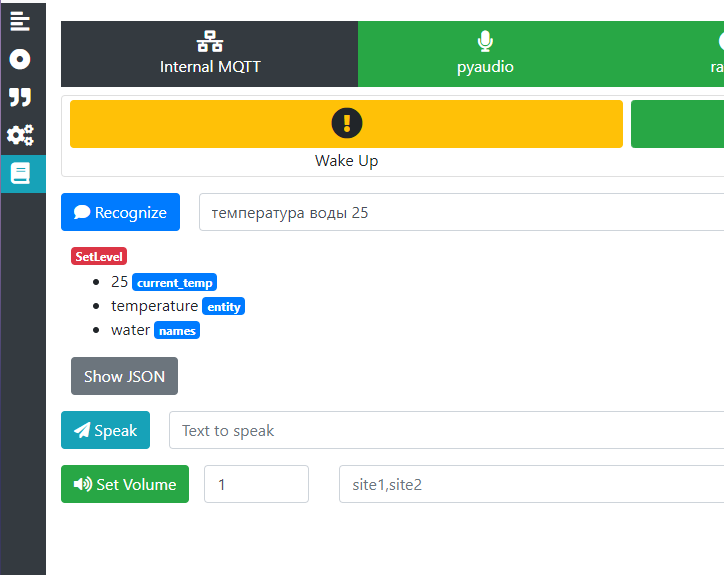
and when I tried to recognize speech, I got an error, see the screenshot below
error message incorrect api key provided yourapikey you can find your api key at httpsplatformopenaicomaccountapikeys type invalidrequesterror param null code invalidapikey
It would be great to use some kind of filter to suppress extraneous sounds, such as NoiseTorch ng, which can remove all extraneous sounds and highlight speech. This works if you use microphone recording on debian, but it doesn’t work with rhasspy.