Do you happen know of any way to send the text transcribed by Whisper back to Home Assistant?
I would like to be able to say “ChatGPT” followed by a question and have the question routed to HA.
Do you happen know of any way to send the text transcribed by Whisper back to Home Assistant?
I would like to be able to say “ChatGPT” followed by a question and have the question routed to HA.
It seems to be possible to do it by rewriting your shell script.
Would you mind sharing what mic or mic array you’re using that gives you that 2-3m range?
The mic/speakers I am using are the Jabra 410 and Jabra 510. I got them 2nd hand.
The primary difference between the two is that the 510 has Bluetooth and the 410 does not. I do not use the Bluetooth, but I guess you could have the speaker in a room and e.g. the Pi somewhere else within Bluetooth range. That way the speaker could be on a coffee table and still look neat. Not sure Bluetooth is stable enough long term, and linux sound config is frustrating enough without adding Bluetooth into the mix.
The nice thing about a conference speaker is even with music playing it still detected voice fine. When playing back the recorded voice wav file I can barely hear the music even though it was 50% volume. The hardware does a good job of removing audio played over the speaker, as a good conference speaker should.
Downside is the speaker is not great for music – it’s designed for voice frequencies.
I’m not sure how familiar you are with Rhasspy, forgive me if I am exlaining things you already know.
Home Assistant has an addon for Rhasspy. See Rhasspy - Home Assistant This will allow Home Assistant to “handle intents” for controlling your home.
If you want a custom intent handler, you can use Node-RED. Have a look at Rhasspy “Intent Handling”, you can use Home Assistant, http (a web hook), or local command (a shell script, pyton program, …)
For Rhasspy to activate when you say the “wake word” like “chatGPT” you’ll need to program your own wake word. Rhasspy has built in wake words like “hey mycroft”, “porcupine”, etc. To use a csutom wake word you’ll need to train one. You can do this online using picovoice.
In Rhasspy settings - wake word: I’ve had the most success with Mycroft Precise and hey-mycroft-2.
I’d suggest following the Rhasspy getting started tutorials and get a solid working foundation using mostly the defaults, before adding complexity with custom wake words, whisper, chatgpt.
Thanks for the detailed reply. Very helpful!
Thanks I’ve used whisper.cpp during work on this: GitHub - hbarnard/mema it’s an experimental setup/project for older people to record memories and photos without a lot of keyboard activity. There’s a partial write up here: Working with the MeMa 3.0 project : Horizon
Anyway, for ‘short stories’ I found I could do real-time transcription on the laptop install but not on Pi4 with Ubuntu. Since this is pretty specialised, I now have a cron on the Pi4 that scoops up current audio recordings and transcribes them as a background task. I have one Orange Pi5 that I haven’t put into service yet, I’ll report on how that goes a little later in the year.
Sorry friends, forgot to say there’s also a project called April-ASR (GitHub - abb128/april-asr: Speech-to-text library in C). It’s used in “Live Captions” application (GitHub - abb128/LiveCaptions: Linux Desktop application that provides live captioning) from the same developer and it is giving shockingly good results for the real-time speech recognition: the recognition quality is high while keeping an ultra low performance impact. It’s worth to give it a shot as well.
I’ using whisper-rhasspy-http on a more powerful machine in my network to do the speech-to-text locally which technically works pretty good.
I also made a home assistant automation that should take the wakeword_id into account.
The idea is to have one wake word for home automation like “turn the bedroom lights on” and another wake word that passes the transcribed text to the openai api and the result to tts per hermes.
The only problem I have is, that using kaldi with pre trained sentences works much better for intent handling with very few false positives but of course is completely useless for open transcription which is needed for the chatgpt-thing and you can’t have both ![]() Using whisper alone for intent recognition on the other hand doesn’t work any good at all because a lot of words are missunderstood.
Using whisper alone for intent recognition on the other hand doesn’t work any good at all because a lot of words are missunderstood.
Oh and having multiple custom wake words is a bit challenging using rhasspy raven as training by 3 samples doesn’t seem to be enough. It either needs a few attempts to wake it up or it wakes up constantly if i’m on the phone ![]()
It’s not working for me. It detects hot word an then I see a warning in the log:
[WARNING:2023-04-28 21:49:58,929] rhasspyremote_http_hermes: Session not found for <session_id>
I’m using iPad now and it seems like there’s no back tick symbol on the keyboard, so cannot format the code in markdown
I tried your version and it doesn’t work for me for some reason. What am I doing wrong?
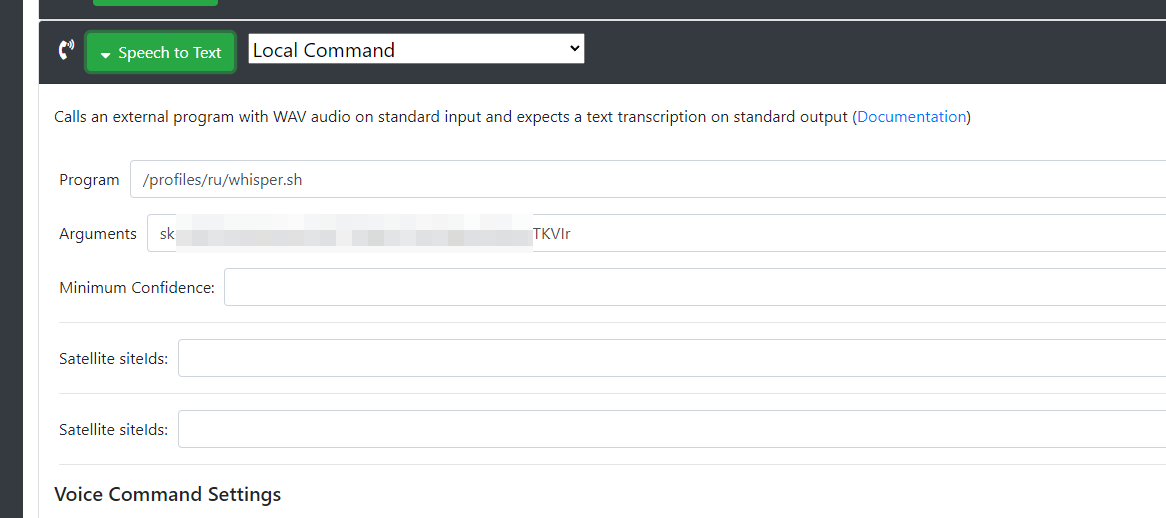
Created a file whisper.sh
nano /home/respeaker/.config/rhasspy/profiles/ru/whisper.sh
Inserted the code
Did
chmod +x /home/respeaker/.config/rhasspy/profiles/ru/whisper.sh
In the settings, I specified the path to the script and inserted the key from the Openal API key
Rebooted Rhasspy and it doesn’t work. I decided to try to run the script whisper.sh from the console
sh /home/respeaker/.config/rhasspy/profiles/ru/whisper.sh
and I get an error curl: (26) Failed to open/read local data from file/application
Some things to try:
The Program path in Rhasspy looks like it might be incorrect: You have /profiles/ru/whisper.sh, I think it needs to be /home/respeaker/.config/rhasspy/profiles/ru/whisper.sh (the full path to where you have the whisper script)
The shell creates a file called speech.wav. In your shell script try changing wav_file=/profiles/ru/speech.wav to 'wav_file=/home/respeaker/.config/rhasspy/profiles/ru/speech.wav`.
After making these changes, restarting Rhasspy and trying an utterance. If it does not work, see if speech.wav file is created in /home/respeaker/.config/rhasspy/profiles/ru/.
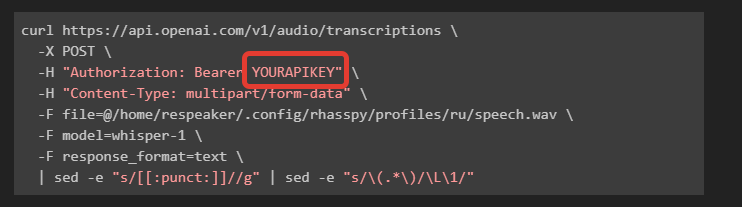
You can also try running the curl command manually from the command line
curl https://api.openai.com/v1/audio/transcriptions \
-X POST \
-H "Authorization: Bearer YOURAPIKEY" \
-H "Content-Type: multipart/form-data" \
-F file=@/home/respeaker/.config/rhasspy/profiles/ru/speech.wav \
-F model=whisper-1 \
-F response_format=text \
| sed -e "s/[[:punct:]]//g" | sed -e "s/\(.*\)/\L\1/"
Hi @NeoTrantor
Oh and having multiple custom wake words is a bit challenging using rhasspy raven as training by 3 samples doesn’t seem to be enough. It either needs a few attempts to wake it up or it wakes up constantly if i’m on the phone
I have been using openWakeWord so that I can have multiple wake-words (and theoretically train custom wake-words.)
I’ve got a Docker image to make it easier to setup and use openWakeWord with Rhasspy: GitHub - dalehumby/openWakeWord-rhasspy: openWakeWord for Rhasspy
Yes, it helped, now it works. Thanks.
Just in case, I’ll post my problem that I encountered because of my mistake, maybe someone will encounter a similar one.
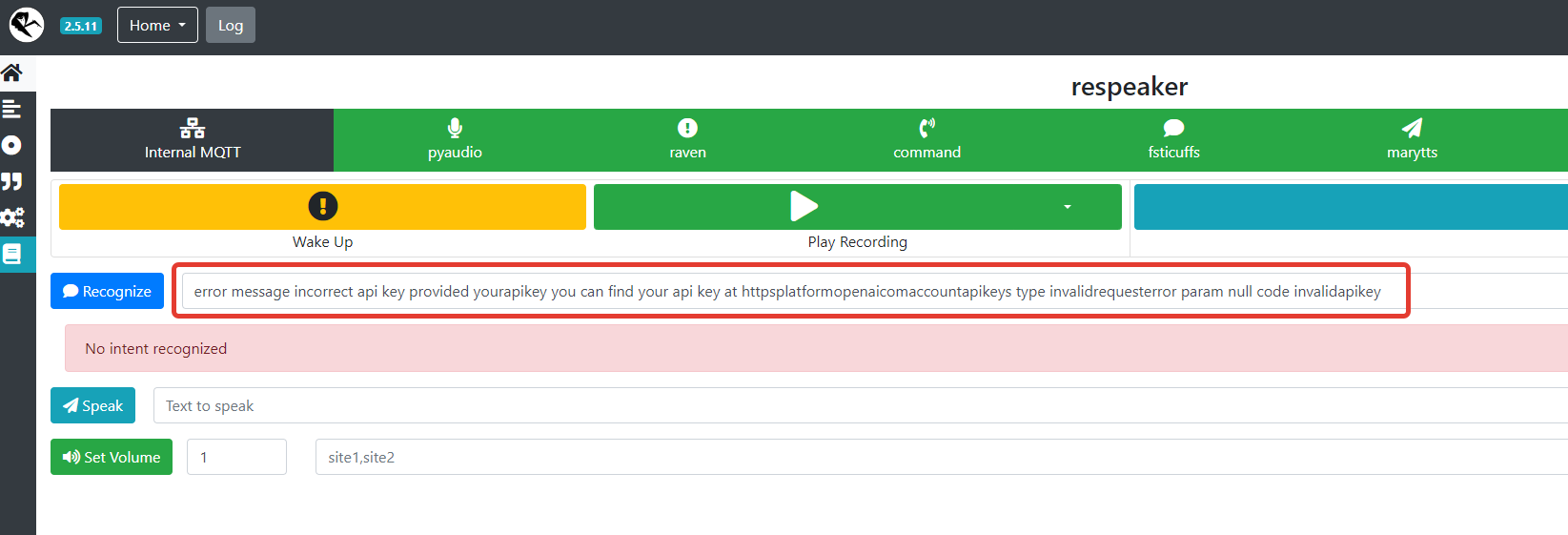
Since I was inattentive, I didn’t specify the api key in this place
and when I tried to recognize speech, I got an error, see the screenshot below
error message incorrect api key provided yourapikey you can find your api key at httpsplatformopenaicomaccountapikeys type invalidrequesterror param null code invalidapikey
I checked the key and the key is exactly correct.
I specified the api key here, rebooted Rhasspy and everything worked
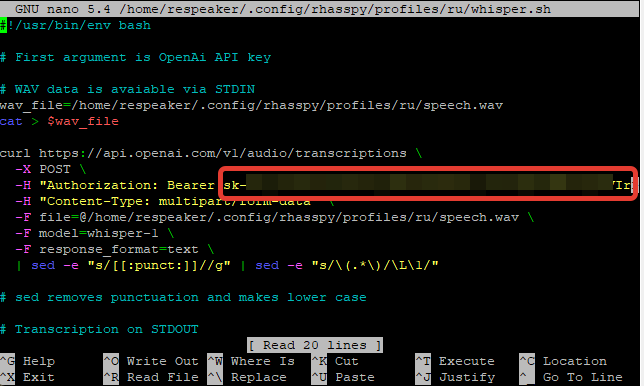
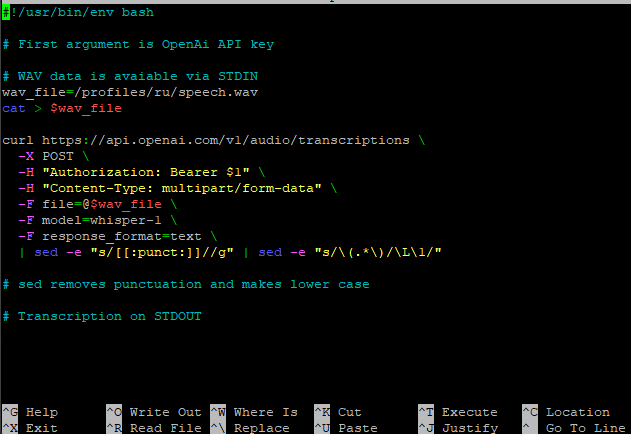
Full code
#!/usr/bin/env bash
# First argument is OpenAi API key
wav_file=/home/respeaker/.config/rhasspy/profiles/ru/speech.wav
cat > $wav_file
curl https://api.openai.com/v1/audio/transcriptions \
-X POST \
-H "Authorization: Bearer YOURAPIKEY" \
-H "Content-Type: multipart/form-data" \
-F file=@/home/respeaker/.config/rhasspy/profiles/ru/speech.wav \
-F model=whisper-1 \
-F response_format=text \
| sed -e "s/[[:punct:]]//g" | sed -e "s/\(.*\)/\L\1/"
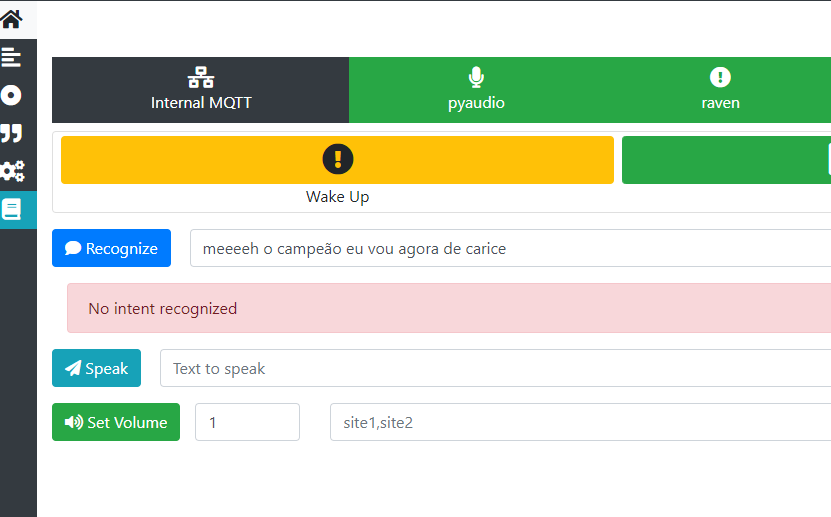
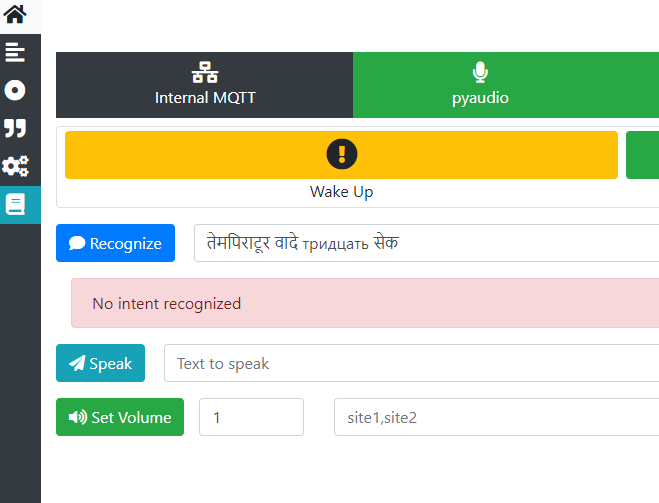
And how are things with speech recognition if music is playing? I am now trying in different situations, music is playing, street noise
Music is playing and I say “the water temperature is 20 degrees”, and the output goes like this
When the music is not playing, there is street noise from cars on the road, it recognizes correctly
It would be great to use some kind of filter to suppress extraneous sounds, such as NoiseTorch ng, which can remove all extraneous sounds and highlight speech. This works if you use microphone recording on debian, but it doesn’t work with rhasspy.
I am glad that you got it working. Thanks for posting your notes to help others in the future.
From your rhasspy/profiles/ru I’m assuming you’re speaking Russian? My experience of Whisper for speech to text has been good, but I am a native English speaker using Whisper in English, which may show better accuracy than Russian.
Whispers API docs includes a language field. Perhaps add to the curl command:
-F language=ru \
to hint that you’re speaking Russian, and try constrain the model. Will be interesting if that improves your experience with music playing.
BTW, since Whisper will transcribe any speech into text (not just what’s in sentences.ini, you might want to explore using GPT3 for “smarter” intent resolution.
That’s right, I am a native speaker of Russian. Thank you, it helped, now it recognizes clearly in Russian. I checked the recognition when music is playing and it works better than Kaldi. It would be great if something similar would be without a cloud solution, so that there would be a local solution.
I’ll leave an example of the code with the addition of the Russian language. You can change the language to your own
#!/usr/bin/env bash
# First argument is OpenAi API key
wav_file=/home/respeaker/.config/rhasspy/profiles/ru/speech.wav
cat > $wav_file
curl https://api.openai.com/v1/audio/transcriptions \
-X POST \
-H "Authorization: Bearer YOURAPIKEY" \
-H "Content-Type: multipart/form-data" \
-F file=@/home/respeaker/.config/rhasspy/profiles/ru/speech.wav \
-F model=whisper-1 \
-F response_format=text \
-F language=ru \
| sed -e "s/[[:punct:]]//g" | sed -e "s/\(.*\)/\L\1/"
Glad it’s working better. Thanks for the updated script.
There are local-only options
Plus Dockerised versions (see my example usage.)
The challenge is that the larger models are slow on CPU, and the small/tiny models are not very good (and still slower than Kaldi.) You could run on a GPU (but then pay for power usage), and AFAIK none support CoralTPU yet.
If you do manage to get a performant, local-only setup, let us know!
I’m very impressed with whisper, currently using faster-whisper on a laptop cpu tiny.en model (damn pi shortage). It can hear my requests 6 meters away, on a basic built in mic quite easily.
I am that impressed, currently experimenting with doing away with waiting for hotword trigger. So can just say “{hotword} play some music” or whatever and it does it. Instead of {hotword} wait for response, give command.
It feels much more natural and intuitive way to interact with the system, the only problem I foresee is with VAD in noisy environments and may require a more flexible intent parser to handle it better. Which is arguably some of the same problems we have with current system.
In short I think whisper is the way ahead of the competition for a STT engine, just need to find the right tech to run it on for your needs.
Its also part of Rhasspy 3.0
I am not so sure about Whisper on lower end hardware especially a Pi as WER increases drastically as model size decreases.
Also this didn’t test command style files such as ‘turn on the light’ or conversational types, that Wer increases drastically with less context for the inbuilt nlp.
I am finding that really I want to use the small model as the best tradeoff but due to load having to use base or tiny.
Mainly I test on whisper.cpp as many others are still using its ggml as a base.
If I run the bench test from whisper.cpp q8_0 quantisation seems to give best results
| CPU | OS | Config | Model | Th | Load | Enc. | Commit |
| --- | -- | ------ | ----- | -- | ---- | ---- | ------ |
| rk3588 | Ubuntu 22.04 | NEON | tiny | 4 | 124 | 1196 | d458fcb |
| rk3588 | Ubuntu 22.04 | NEON | tiny-q8_0 | 4 | 95 | 1031 | d458fcb |
| rk3588 | Ubuntu 22.04 | NEON | base | 4 | 156 | 2900 | d458fcb |
| rk3588 | Ubuntu 22.04 | NEON | base-q8_0 | 4 | 118 | 2511 | d458fcb |
| rk3588 | Ubuntu 22.04 | NEON | small | 4 | 378 | 10874 | d458fcb |
| rk3588 | Ubuntu 22.04 | NEON | small-q8_0 | 4 | 244 | 7944 | d458fcb |
./main -m models/ggml-tiny-q8_0.bin -f ./samples/jfk.wav
whisper_print_timings: load time = 114.51 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 287.05 ms
whisper_print_timings: sample time = 24.77 ms / 25 runs ( 0.99 ms per run)
whisper_print_timings: encode time = 1032.13 ms / 1 runs ( 1032.13 ms per run)
whisper_print_timings: decode time = 121.98 ms / 25 runs ( 4.88 ms per run)
whisper_print_timings: total time = 1640.46 ms
./main -m models/ggml-base-q8_0.bin -f ./samples/jfk.wav
whisper_print_timings: load time = 142.35 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 286.55 ms
whisper_print_timings: sample time = 25.72 ms / 26 runs ( 0.99 ms per run)
whisper_print_timings: encode time = 2493.89 ms / 1 runs ( 2493.89 ms per run)
whisper_print_timings: decode time = 185.91 ms / 26 runs ( 7.15 ms per run)
whisper_print_timings: total time = 3214.44 ms
./main -m models/ggml-small-q8_0.bin -f ./samples/jfk.wav
whisper_print_timings: load time = 265.50 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 287.76 ms
whisper_print_timings: sample time = 26.94 ms / 27 runs ( 1.00 ms per run)
whisper_print_timings: encode time = 7844.49 ms / 1 runs ( 7844.49 ms per run)
whisper_print_timings: decode time = 475.21 ms / 27 runs ( 17.60 ms per run)
whisper_print_timings: total time = 9036.22 ms
Also it works for many languages but not all with the same level of accuracy but it varies hugely to how you run it and the WER levels are not that great compared to what is supposedly a 2nd best of Wav2Vec2, ESPNet2 whilst Kaldi seems to be being left behind.
I have been looking for a Wav2Vec2.cpp but failing as you can greatly increase accuracy by splitting the awesome all-in-one of Whisper into specific domains that for load give better accuracy.
The Raspbery stock situation has been drastic and likely have much effect on Raspberry as it has created a much wider market of alternatives.
I think the Opi5 4GB £63.08 is prob a great bit of kit with all the great models of late.
1.6watt idle at the plug, but far more power in the cpu and has a modern MaliG610 GPU & 6 Tops NPU which really is 3x 2 Tops but hey.
When you have purchased sd, cooling, psu even be it a Pi then there are alternatives and the commercial Micro PC’s especially the I3s are pretty good for money.
I have a Dell 3050 Micro I3-7100T 8GB that is sort of between a Nuc & Mac-Mini in form factor that just needed a 2nd user 240gb £15 NVME that I got off ebay and has a great case, cooling and PSU.
So for £75 it could even be a tad cheaper.
Idle goes up to 8 watts but still good and is a bit faster than the RK3588.