The noise is weird as yeah intend to use the gpio usb as that is a real bonus on a SoC as when you have a case with a SBC your ports are often on the outside!
Its on a never ending ToDo to wire up a USB header with the x2 data lines and 5v&Gnd but as per usual with procrastination its sat like this
Really all that should be needed is a mali.so to link to OPenCL but only managed to get ArmNN runing CPU wise.
Again its another ToDo.
@fastjack It was about £30 when delivery and tax was paid, Mathieu. What did it cost you to get it to France?
I am expecting the Rpi02 to get a bump in price when avail maybe to $20 even $25. Opi02 being a tad faster than Rpi3+ and 1gb, so guess its a choice of either, but with stocks currently its one of few choices.
I do like the idea of personalized detection, as that can certainly reduce the scope of the problem the KWS needs to solve. The big question in my mind is how much data is required, and whether that is a barrier to new users. E.g., collected 5-10 samples is a pretty reasonable step that most users could likely tolerate, but collecting hundreds is probably not.
You definitely have done some great work here, these projects are very nice! And I think I see your point, we do have some software options, but if the hardware/OS doesn’t have good clock syncs and scheduling it can degrade performance quite a bit. So without being able to lock-in on specific hardware and focus development effort there (e.g., like Tech companies can), it is indeed very hard to coordinate.
Training some noise cancellation into the model is definitely a good idea. I did a few limited experiments with the Speex noise cancellation for openWakeWord and it seemed promising, I’d like to return to that soon and see how well it can perform. Deepfilter.net or DTLN could be even better, assuming to your point that the hardware supports it.
Sure, I’ll start on a higher quality model for it after I finish my RyanSpeech model. I always need more GPUs…
The company is kind of in stasis right now, but they do have inventory left – things like the XMOS chips. I’d be willing to fund the creating of some SJ201 boards myself, probably with a slight tweak to not have the board at a right angle to the Pi (this was to fit in the Mark II case).
That would be awesome, thanks
@dscripka I see from your Jupyter notebook that the actual wake word model has this structure:
Also, I randomly came across BCEWithLogitsLoss and noted that it would exactly fit this case since you use BCE loss with a sigmoid. I wonder if the higher numerical stability would help with quantization in the future.
I’ve tried and failed numerous times to quantize the Larynx 2 models, but this one seems simple enough that it might actually work.
Great thanks! Not sure how heavy the training is (in the original VITS paper I see they used 4x V100), but I have a RTX-3090 that I’d be happy to run for a week or two, if that would even make a dent.
Good question, I probably should have put more detail into the example notebook. Ultimately this model came from a bunch of experiments. The core of openWakeWord is the pre-trained speech embedding model from Google, which is pre-trained on a fairly large dataset. From their paper and my own experiments I learned that this embedding model is doing that vast majority of the work for the wakeword detection, and thus the classification head can be pretty small. I tried a bunch of different models (simple DNN, recurrent, convolutional, attention, etc.) and generally found that performance differences were not that significant. I ended up using the DNN most of the time because it is very, very fast. ReLU and layer norm were added as they seemed to boost performance and stabilize training a bit.
That is a great catch with BCEWithLogitsLoss in Torch. I haven’t tried that, but it certainly wouldn’t hurt to use that for at least the binary models (there are some multi-class openWakeWord models that use softmax).
These models can certainly be quantized, using both static and dynamic quantization just from onnxruntime.quantization. The embedding model doesn’t really see an efficiency boost with dynamic, though, and I haven’t yet done the work to find a good calibration data set for static quantization and assess the impact on accuracy. Also, while there is a nice 1.5x - 2x speed-up on x86 for the quantized models, I don’t see much improvement on ARM (RPi). Though I might just be doing something wrong here, I haven’t spent much time testing.
I did a repo 2 years ago that is a CLI recording console where you are prompted on screen to read individual words of KW and !KW as it uses phonetic pangrams that are the shortest sentences containing all the Phoneme of a language.
There are 6 sentences to read out word by word and you can choose the 1st 2 sentences , 4 or all 6 as choice and its up to the user.
Because your deliberately making a personalised VAD/KWS the data requirements are surprisingly little as you are creating an overfitted dataset of user(s). Multi-user hardware and software agnostic models are hard to create, whilst recording a small dataset on the hardware and software you intend to use is surprisingly easy.
Again with lateral thought there are many ways to do this and how far you take this is choice and 2 levels as personal VAD requires much less data than personal KWS, but both are single voice datasets as opposed to huge global voice datasets, as you are deliberate overfitting to users and hardware.
Supplement the KW with synthetic reduces the number of recorded needed and just provide bias to user voice(s), as what you are doing is great, even clone your voice which in AI is trending right now to add more without the effort, with others. Again Tortoise, gets mention where likely you would not use as a smart assistant TTS but great for this, but do a Google for voice cloning as its extremely prevelent https://www.resemble.ai/ or
Then I have been putting back together a repo I thought I had a copy of, when I re-installed Ubuntu as Augmentation can quickly take a few sample and augment into hundreds or thousands.
Don’t use that as of yet as I am doing the same mistake as I have it local on a harddrive with many, many changes and doh, I haven’t pushed the commits again which I should. It sort of needs a last addition as I began to decide Sox reverb and echo is pretty pants for augmentation as it augments into much that likely may never occur and pyroomacoustics is likely much better even if more complex to code.
How much a user adds at the start doesn’t mean that is it, as you are on a system and whilst using you are providing data of the utmost quality. You augment, you supplement and you also capture as due to the nature of a voice assistant its spends the majority of its time 24/7 idle whilst the base could be training the next upgraded model based on any of those methods, but I suggest you don’t ignore the utmost quality data of actual use, in postition, of the user on the hardware as that is accuracy gold.
It just gives Tech companies a massive head start as the models are trained on data that is captured from use of users and hardware of use and likely they augment data for new hardware, everything has a signature and if you train that in you become more accurate.
The less you train in and the wider your catch net the less accuracy or more complexity in models you need, but the bring your own to the party, is the worst scenario and an even harder task and hardware dictate is a huge advantage and what I call Magic Microphones are nothing but delusion, as even Big Data has tended to simpler low cost solutions and models as knowledge has grown.
Speex AEC works OK, always has but like all AEC it fails as there is no reference for 3rd party noise, a silent room with only the Voice Assitant creating audio is not the norm in many situations, so it leaves a huge hole of potential failure of 3rd party noise where big data started with beamforming and noise suppression, but likely SotA lies in targetted extraction (Its far easier and more accurate to extract a known than to cancel the unknown, hence enrollent methods give a clear target).
There are alternatives to AEC as that method completely dislikes application SoC’s without a hardware loopback and is very sensitive to timing, whilst actually better methods exist and there is source examples but BSS is another simple but low level DSP solution we seem to be lacking that helps fill the void of 3rd party noise.
Also really like telephone exchanges of the past where mic and speaker could create a feedback loop, we are really interested in line cancellation than echo, due to the proximity of mic and speaker. A simple physical alternative is to split them and not copy comercial all-in-one product and make things much easier.
Its been near 3 years since my introduction to opensource voice software, that the lack of co-ordination, ignorance of the importance of the initial audio stream processing and lack of DSP low level coding that can take advantage of low lost enbedded hardware purely through optimised language choice is something I find absolutely astounding, but hey you do from time to time get something new and exciting and I really like what you are doing with synthetic datasets as its a clever and likely useful bit of lateral thinking.
Training in a filter is relatively easy as you just simulate use, take some of your dataset mix in noise and run the filter and use the result in your dataset, I presume Big Data take that to an extreme and simulate all there hardware, but the hardware is low end and low cost just highly optimised, engineered and controlled.
Whilst saying that I am equally interested at how you can supplement any dataset be it KWS or ASR to create domain context sentances to increase accuracy. I have been thinking you can have an upstream small language model streaming ASR to act as a 2nd layer KWS and predicate skill router.
Your methods likely could supplement any dataset that you do have a TTS language model for amd dunno if you have ever seen GitHub - qute012/Wav2Keyword: Wav2Keyword is keyword spotting(KWS) based on Wav2Vec 2.0. This model shows state-of-the-art in Speech commands dataset V1 and V2. as been wondering could be extended to KW & predicate router as conversational and command ASR are very distinct domains.
The LADSPA plugin that can work with a variety of Linux sound servers, Alsa, Pulse, pipewire GitHub - Rikorose/DeepFilterNet: Noise supression using deep filtering is tremendous but it uses the Sonos Tract ML framework that is single threaded only or at least for some reason has been implemented that way.
So without threading it just needs a relatively big but single core to run on is its biggest problem but apart from that its an amazingly good filter.
I got one and made the mistake of purchasing early New Year and being China and celebrations it was a bit slow arriving but was a UK total of £30 so Pi3+ pricing still and a tad faster.
Go to the Opi site and use the aliexpress links there as it was £22 but with tax and shipping it just topped £30.
Total item costs
£22.13
Total shipping
£3.96
Tax
£5.22
Total£31.30
This is an impressive project, and the live demo worked well for me.
How can I use these wake words in Rhasspy? I guess I need to download the models, but I am at a loss of how to configure Rhasspy Wake Word.
Can I use Rhasspy Raven and point to these models instead? Or use Python and run as “Local Command”?
It would also be nice to run multiple wake words (eg weather, times and mycroft.) I’m using a Pi4B, so should have enough power according to the repos readme.
The hardware AGC of the Max9814 helps much to stop clipping, but also the AGC on the soundcard can extend that and the advantage of hardware is that the routine creates no extra latency.
There is also the Speex AGC Alsa plugin but Debian for some reason still holds an ancient RC of Speex/DSP whilst asla-plugins rightly looks for the release version so it never gets compiled and installed.
The CM108 is a very generic soundcard that works well as there are some el-cheapo’s that are not so good, but the hardest struggle is actually ensuring what chipset is inside even if marked as CM108 it could differ.
I think that is why the module type is a thing as there is no mistaking that is a CM108.
The input gain fed to KWS and subsequent ASR is likely one of the biggest factors in the variance of results, where often voice mic signals are too weak and even worse, positioned near audio output that causes clipping, changing the waveform shape.
So any preamp will help extend any soundcard as really they are expecting a ‘broadcast’ like tabletop mic input that only cover short close field distances, the Max9814 AGC + soundcard AGC also helps extend the AGC range even if not perfect.
They come in various forms that allow you to add a mic on a 3.5mm jack or solder connections but the ones with onboard soldered are just easy and the electret push fits into a 9.5mm rubber grommet, which makes for a easy case mounting.
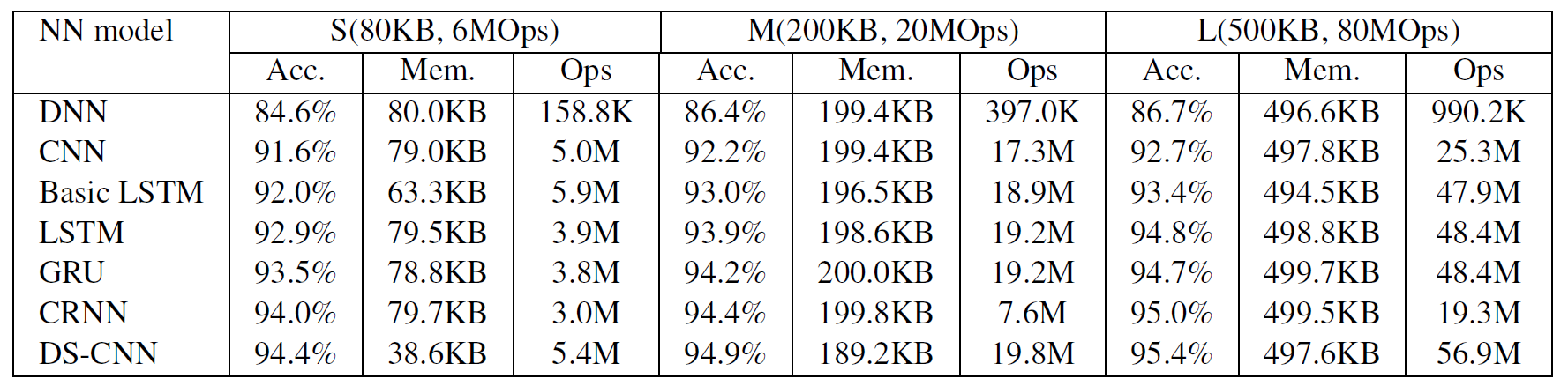
I like the CRNN as KWS model as its a naturally streaming model that is the combination of a GRU (Precise) and a CNN increases accuracy but also reduces the number of parameters.
I tend to like the better latencies of streaming KWS but prob someone should test the load of thoose 2 as likely they represent one of the best low load streaming models vs low load static model as it would be good to get an update on the Arm performance table, but google-research/kws_streaming at master · google-research/google-research · GitHub is a great resource.
It will take a bit of work to integrate, but shouldn’t take too long. I’m hoping to create a lighter C++ version, but we’ll see how far I get with that
Thanks for the offer, but I think I’m good for now I have it running on a 3090 at the moment, and it’s ticking along. I had FP16 training working in my old VITS model, but it stopped working when I switched to PyTorch Lightning for some reason. If I could get that and multi-GPU training going again, I could speed it up a lot.
I’ve seen similar results with other models, which makes me wonder if the ARM NNPack library isn’t compiled correctly or something
How did you end up wiring it? Just signal and ground to the 3.5mm jack, or did you do anything with the other pins?
We’re trying for some more “lateral thinking” here as we discuss hardware for the satellites. I wonder if the personal VAD approach (or even the Raven dynamic time warping method) could be used as just a first pass, and then we could have openWakeWord run on the server for a final confirmation. So it would look like:
Personal VAD (or some simpler wake word system with high false positive rate) activates on satellite
Audio starts streaming to server (plus a small buffer from before the activation)
Server runs streaming audio through openWakeWord until a detection or short timeout occurs
You can use any as merely its just a switch to select from possible multiple streams as in a distributed array so that you are not broadcasting continually and if the same alg then you should be able to pick the ‘best’ stream.
VAD is the lightest, with the least data requirements because its based on features in spoken words than the whole words used with KWS. Either can be created relatively easy by overfitting to a small dataset of user(s) voice (personal), but that could be just a get you going as a huge source of data of use is left to waste.
Can be any 2nd factor check and that it gets 2 hits on 2 different systems should lower the false positives, where it doesn’t matter if the simplcity of the 1st has higher positives than single factor checks, as the combination of 2 checks means the 2nd just filters but doesn’t initiate.
I am actually a fan of the idea for a streaming KW/Predicate ASR that tries to extract start of sentence to allow routing to either a conversational or command ASR as both have very different requirements.
A quick check on start of sentence almost adds a 3rd factor check of ‘is there anything intelligible. nope stop’.
How it works in practise, dunno but definately worth a go.
As @synesthesiam mentioned, this will take some effort to integrate with Rhasspy, but not much. For example, if you are using Rhasspy 2.5 I think you are right that the local command approach would work fine. Something like this should be close (though I haven’t tested it):
import openwakeword
oww = openwakeword.Model() # loads all default models
while True:
data = get_data_from_stdin() # 80 ms of audio data
prediction = oww.predict(data)
for model_name in prediction.keys():
if prediction[model_name] >= 0.5: # or whatever threshold you want
write_message_to_stdout()
And a Pi4B has plenty of power for these models, you should be able to run 20+ models on a single core.
Could you please explain something. Maybee I’m wrong:
I guessed, the UDP Audio (Output) prevent the satellite to send wav chunks all the time.
So the wake word recognition should stay on the satellites and start streaming over mqtt after the ‘startListening’ message is received.
You installed the openWakeWord on a different system. Is this because of the “just for training system character”, or do I have a mistake in my thoughts?
Hi Kay. The audio continually streams from the satellite to openWakeWord over UDP. If the satellite is on a Pi and openWakeWord on another server then there will be a constant stream of network traffic over eg WiFi (about 32 kB/s.) This is not over MQTT, but via UDP.
Once the wake-word is detected, openWakeWord sends an MQTT message to Rhasspy (on topic hermes/hotword), Rhasspy stops sending UDP audio, and (depending on your setup) may send audio over MQTT on the hermes/audioServer/ topic to the speech-to-text system. But as soon as the speech to text is done, Rhasspy stops sending audio on MQTT and starts sending audio on UDP again.
You can run openWakeWord on the same machine as Rhasspy if you prefer. I run openWakeWord on my main home server so that I can centrally manage and configure the wake words instead of on multiple Pi’s… and (hopefully soon) build a feature so that only 1 satellite triggers even though multiple hear the wake word (small apartment.)