I’m using Sox for audio data augmentation like normalization, adding noise, tempo changes, etc.
It is quite easy to use and pretty powerful.
I’m using Sox for audio data augmentation like normalization, adding noise, tempo changes, etc.
It is quite easy to use and pretty powerful.
Yeah its ok for taking out silence and stuff and a great toolkit.
Its the ASR to create split points in audio so that something like sox could.
Most datasets are spoken sentences that we have the text but not split cue points.
If you take the google command set there are 3000 for each word and don’t fancy doing that manually via audacity.
The datasets also allow to to queue up sentances that you know conatin words but even with sox without those split cue timings its a no go.
Unless you got ideas how?
Deepspeech I love you!
deepspeech --json --model deepspeech-0.7.0-models.pbmm --scorer deepspeech-0.7.0-models.scorer --audio audio/2830-3980-0043.wav
Loading model from file deepspeech-0.7.0-models.pbmm
TensorFlow: v1.15.0-24-gceb46aa
DeepSpeech: v0.7.1-0-g2e9c281
Loaded model in 0.00822s.
Loading scorer from files deepspeech-0.7.0-models.scorer
Loaded scorer in 0.000137s.
Running inference.
{
"transcripts": [
{
"confidence": -24.236307801812146,
"words": [
{
"word": "experience",
"start_time ": 0.66,
"duration": 0.36
},
{
"word": "proves",
"start_time ": 1.06,
"duration": 0.32
},
{
"word": "this",
"start_time ": 1.42,
"duration": 0.16
}
]
},
{
"confidence": -34.029636880447235,
"words": [
{
"word": "experience",
"start_time ": 0.66,
"duration": 0.36
},
{
"word": "proves",
"start_time ": 1.06,
"duration": 0.32
},
{
"word": "his",
"start_time ": 1.42,
"duration": 0.16
}
]
},
{
"confidence": -35.76723024350955,
"words": [
{
"word": "experienced",
"start_time ": 0.66,
"duration": 0.4
},
{
"word": "proves",
"start_time ": 1.1,
"duration": 0.3
},
{
"word": "this",
"start_time ": 1.44,
"duration": 0.18
}
]
}
]
}
Inference took 0.879s for 1.975s audio file.Still need delete or omit the words deepspeech gets wrong as been wondering if proffessor floyd had a chip on his shoulder.
“Professor Floyd pointed out that mass lesions are a possible cause for epileptic seizures”
recognised as
"
{
“transcripts”: [
{
“confidence”: -100.5955242491676,
“words”: [
{
“word”: “professor”,
"start_time ": 1.3,
“duration”: 0.38
},
{
“word”: “floyd”,
"start_time ": 1.72,
“duration”: 0.4
},
{
“word”: “pointed”,
"start_time ": 2.14,
“duration”: 0.36
},
{
“word”: “out”,
"start_time ": 2.52,
“duration”: 0.14
},
{
“word”: “that”,
"start_time ": 2.68,
“duration”: 0.16
},
{
“word”: “malaysians”,
"start_time ": 2.92,
“duration”: 0.92
},
{
“word”: “are”,
"start_time ": 3.9,
“duration”: 0.08
},
{
“word”: “a”,
"start_time ": 4.0,
“duration”: 0.1
},
{
“word”: “possible”,
"start_time ": 4.14,
“duration”: 0.38
},
{
“word”: “cause”,
"start_time ": 4.66,
“duration”: 0.36
},
{
“word”: “for”,
"start_time ": 5.06,
“duration”: 0.08
},
{
“word”: “epileptic”,
"start_time ": 5.18,
“duration”: 0.58
},
{
“word”: “seizures”,
"start_time ": 5.92,
“duration”: 0.4
}
]
}
]
}
Its dangerous stuff this recognition lark! 
I’ve stumbled upon an article detailing how Snips handled the “personal” wake word detection with only a few samples:
This was a pretty interesting read…
@synesthesiam Maybe something similar could be implemented as a Rhasspy service? It should allow both custom wake word detection and speaker identification…
I thnk you can do both now @fastjack
To be honest to to the availbility of technology and what @Bozor said the private services of creating models or hiring TPU slots is getting extremely cheap.
I think you can create a general large model and also custom training to that large general model that will be processed on a cloud server in minutes rather than hours on a I7 and forget about it levels on a Pi.
You might even be able to squeeze quite a few models in a single hour and if so the service becomes extremely cheap.
Offer the service on minimum donation as the training update needs to be done only once and maybe occasional updates and even opensource has to cover its running costs.
If it was $5 a pop it would prob also leave some additional funding even though small for storing datasets.
Models are blackboxes and not opensource as without the coding dataset they are closed so its essential to have the datasets.
But yeah you could prob also train just a simple specific KWS but also with the advent of cloud TPU you can train general large datasets and supplement with custom training.
They actually need to have set keywords and the use of phonetic based KWS that introduces high complexity, load and model is such a strange avenue to take.
Do you call a dog a cat because you prefer that word?
That article is great and the only thing I noticed and maybe you can do both but think this will create less load.
You don’t need to do audio preemphasis as you can do that via the MFCC creation by raising the log-mel-amplitudes to a suitable power (around 2 or 3) before taking the DCT.
High pass filetering is not all that load intensive but the above is also another solution to removing noise.
In fact you don’t have to do any of that but just import librosa and set the parameters but the action is the same.
That article is really good though and really do think there should be a truly open KWS that has access to datasets as sharing models is akin to closed source.
The false alarm rate of the Snips method is really high though False Alarm rate per Hour is 2.06
When say you compare to Porcupine that has 0.09 FApH
Things have moved very quickly in the AI world and that article when published was pretty cutting edge but aslo some of its content is now quite dated.
Its false alarm rate is extremely dated by many standards now.
But generally KWS is quite simple much of what is in the article is already in libs or frameworks or both.
ASR is complex KWS is fairly easy to accomplish but also the ability to use server farms in cheap slots has change on how we may use AI.
Custom training of use may well become a norm as over all other methods it can drastically increase accuracy.
But going back to datasets as its all about the dataset as any model created with a dataset that was captured with the audio capture system of use will always be more accurate.
The problems I have with Porcupine are:
The problem with training a NN is that for most people (I included) it might be way too complicated.
Snowboy seems to work pretty good with personal models based on a few samples (which might be based on the same DTW stuff as Snips) so I’d like to explore and see if this approach can work without taking out the big guns and train a NN using à multiple GBs dataset.
I’m very curious of the performance of the DTW technique though (accuracy and CPU wise).
I first though that ASR and NLU would be the hardest part but it turns out wake words seems be the most lacking one 
Did you manage to get your « visual » model to run on a Pi on an audio stream without eating all the CPU?
To be honest I am not advocating all to train NN even if it is much easier than I expected.
You have seen my reluctance to code nowadays
I haven’t actually tried the model on the Pi but reason I picked it is because of the extremely light CNN tensorflow KWS that have available examples proven and available.
Arm and a few others did some repos of fitting KWS into 22k was it? Anyway it runs on low end microcontrollers.
This guy has some great Pi specific version with fixes and low load mobilenet examples and benchmarks and load can be extremely low.
I am exactly the same about Porcupine but the example you posted is > 2000% more inaccurate, that is not just bad that is utterly terrible.
I use Porcupine as a datum of low load high accuracy KWS but don’t advocate its use but actually believe similar results are possible.
KWS or NN isn’t hard and no-one is suggesting people train there own NN as that would make the assumption they have a reasonable > Cuda 3.5 compatible card and the patience.
Its very possible as part of an opensource offering a service that will do that and return in minutes without any knowledge of NN or training.
A general purpose KWS can run as is and be collecting KWS of an initial period and then the user can have the choice to upgrade with a custom train and needs no knowledge or equipment.
It wouldn’t be so bad if the snips method was 2-3x less accurate than some of the others but x22 worse is just extremely bad and that article was quite promising until my eyes bulged at that failure figure.
If you want accurate multipurpose KWS it takes GB of dataset training but the models it produces that people use are relatively tiny the ‘visual’ pb model is 1.5mb.
@ thinkbig1979 posted about Linto and had forgot about Linto as some of the server side operation put me off.
The KWS they have and the Python Lib https://github.com/linto-ai/pyrtstools is pretty excellent and would fill that gap Rhasspy has.
It even has a Hotword trainer App but once again its all about the dataset but Linto have wised up to this with.
They also have a buster version with the seedviocecard driver installed.
https://gamma.linto.ai/downloads/Raspberry/v1.1/linto-maker-buster-v1.1-seeedvoicecard.img
The post got me looking at Linto again now I am not so noob about VoiceAI.
Looks really excellent and they give a choice of pre-created models or a model trainer app and also have datasets.
PS found another promising Pi KWS tensorflow repo.
Really good as if you check the above a series of tutorials and videos accompany it.
I have to say once more Linto is looking really good as everything I have been thinking of I keep finding Linto have already done it 6 months to a couple of years ago.
Started once more to find optimised mfcc libs for the Pi and this has cropped up quite a few times that no longer surprised to find exactly what I was looking for with linto.
I have no idea why those guys don’t have a community portal as it seems a crazy ommision?
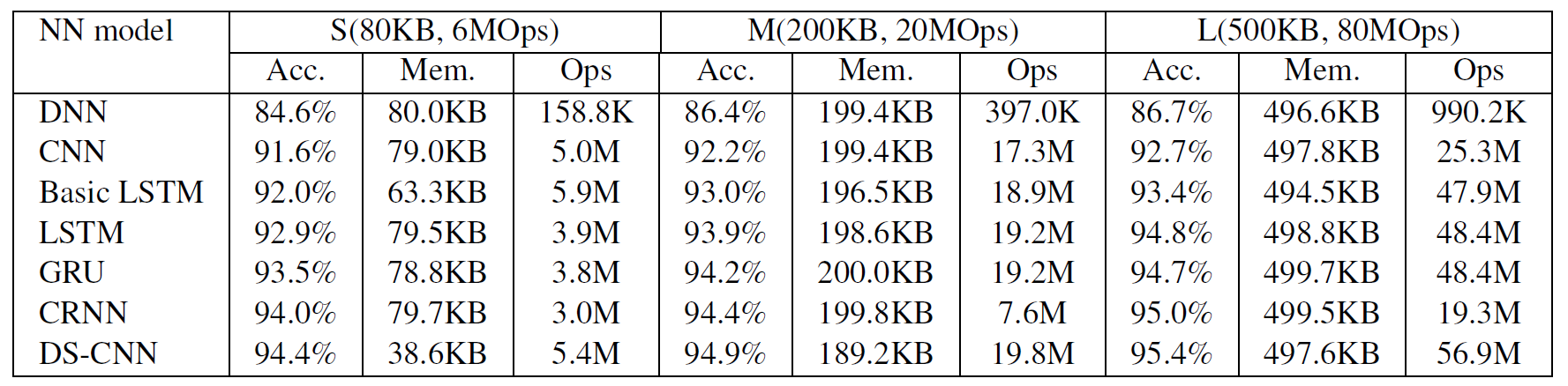
They have also gone for a RNN model which I pressume is for reasons listed here.
The DS-CNN model does provide the most accuracy but interms of Ops its actually the heaviest.
The CRNN is extremely lite and amlost as good so presuming why as DS-CNN would only seem prefereable in extremely low memory footprints hence why it was used for embedded.
Its probably quite easy to snatch the CRNN model creation from here and apply to the above tensorflow examples.
@fastjack Have a look at https://github.com/linto-ai/linto-desktoptools-hmg (Hotword Model generator)
Install on 18.04 in fact the binary they also offer makes it real easy but the inteface and setting for a Hotword Model Generator are near perefect with maybe just an evolution of further parameters to come.
Even if its not selected because of different KWS use the manner of the App makes a great template for any project to follow,
You can also just point and click to folders if they are a hotword or (not hotword) which makes the dataset side a little easier.
Its also has a test page and you can grab your mic and direct test the model you just made.
The speed of model creation is so fast compared to the tensorflow example I was running I am wondering how its done?
The GUI looks pretty good! I’ll try to test it out as soon as I find enough time 
Even if not adopted that is very close to how a model builder app should be.
Maybe could do with some extra MFCC & parameter options but as is, is pretty much complete.
Out of curiosity, I implemented the personal wakeword system described by the Snips team in this post (in Node as I’m not a Python dev):
It is pretty easy to do (VAD -> MFCC -> DTW) and the accuracy is pretty decent. The CPU load is almost non existant (a few percents max on my computer, did not yet tried on a Pi or Pi0).
I can now not only detect a wakeword (interestingly even in noisy situations like a TV in the room) but the person who triggered it (speaker identification) as keyword templates are tuned to a specific voice.
The only downside is that every user needs to register its voice templates before being able to trigger the assistant.
I think it might be a really great addition to the Rhasspy wakeword family if one of the Python/C++ gurus out there is motivated (using C++ for the whole process - from audio frame to DTW cost - might be a good way of decreasing the load even more especially for the MFCC/DTW part).
Cheers .
Sounds really cool. Could you share your node code? is it somewhere on github?
Id be really interested to look at it 
Yep, here it is:
It is still a work in progress 
Sounds interesting. To test your code I need recordings of me speaking the desired wake word? How many recordings are needed?
For VAD your code uses node-vad. If we want to create a C++ Version we would need a replacement for that. Are you using any other important modules?
I usually use 3 recordings for each keyword. The rules for the audio templates are the same as Snips (only trimmed wakeword with no noise, 16KHz 16bits mono little endian)
I’m using node-vad and a home made native node module named node-gist that provides bindings for the C++ Gist audio library for the MFCC features extraction.
All of this should be pretty straight forward to mix in a C++ library / binding for a seasoned C++ dev.
Note : I have my own recording script and did not try with mic but it should work as long as you pipe 16KHz 16bits mono buffers into the detector.
Talking about snips wakeword I use for two years now with three customs wakewords (one per family member here) and it works really great. And indeed in jeedom I can filter per person in a scenario.
Actually I have even better results with snowboy but didn’t really tried with multiple custom wakewords.
I’ve still not put rhasspy into production only due to this wakeword problem. All is running fine, Jeedom plugin works perfect, but not having a viable solution for multiple custom wakeword is a no brainer.
Let’s see if rhasspy can integrate this one ? Also as rhasspy interface ever have access to mic to test intents, would be awesome if we could create custom wakewords directly from the interface. My custom snowboy scripts are in python and have recording and detect noise, and cutting so it may help.
But rhasspy really need a viable solution for multiple custom wakewords ( without having to redo it every 30days …)
The thing that put me off the snips method was.
On voices, the False Alarm rate per Hour is 2.06, which means that with people constantly talking next to it, the wake word Detector will trigger about twice per hour with default settings. Improved performances can be obtained by tuning decision parameters on a case by case setting. The False Rejection rate is 0% without background noise, and 0.3% in noisy conditions.
Its sort of stretching reality to say that is good.
I don’t actually see training as a disadvantage and actually see it as a strong advantage and dismayed that not only here that the VoiceAi can not collaborate with something as simple as a dataset spreadsheet to create a central distributed dataset or even something more snazzy, but dismayed as providing word datasets is real easy and just not done.
VAD/SAD should not be a seperate process to MFCC creations as the very same FFT routines do the same thing whilst VAD works on stride or frame whilst MFCC is over a framing window.
There already exists a Julia Lib that alaready does this and much more.
https://github.com/JuliaDSP/MFCC.jl
But because we are often on a ARM platform a C implementation with Neon specific optimisation for https://projectne10.github.io/Ne10/ would be the ultimate sweet spot, as the gains can be quite large.
Then we just need some simple tools that run on Windows and Linux that work in a similar manner to the excellent https://github.com/linto-ai/linto-desktoptools-hmg/wiki/Training-a-model
That easily allows the addition of validated word dataset folders to create a model.
Allows you to visually set parameters on the VAD->MFCC process you wish to employ.
Why we don’t have a simple central spread sheet or dataset Urls is a complete mystery to me.
Also a central datasource of completed models that allows choice by Language, region, gender and age would allow those who don’t want to train a bespoke model.
The tools to enable this are quite simple and there is huge need and coding is a choice of whatever is easy to distribute, if it runs and is easy accessable the code of a UI doesn’t need much dictate.
I have my doubts about the accuracy of the Snips implementation but understand why Mathieu Poumeyrol might see that as a contender.