What I really want to do is just get Rhasspy running in a VM and using a mobile/Android app for remote microphone testing via mqtt - for the purpose of experimenting and voice-app development.
So far been struggling with getting the build to complete - making progress if gradually.
Atm, working on getting the microphone working (pass through) in the VM.
A long time ago I got this to work via the standard Docker install so I know it works - just more difficult doing a complete build and run in a python .venv
Yes, I know it’s only been a few days and 11 voters … but a couple of trends are showing already:
only 1 out of 10 voters are NOT using Satellite + Base configuration
A majority are using Rhasspy with home Assistant (so a HA integration is important) but a significant number are using other automation systems or made their own (so current strategy of making Rhasspy a toolkit is important)
most voters described themselves as a user or intermediate - though this probably more that experienced users don’t visit this forum so often as new users
For those using other home automation projects, it would be interesting to know which ones, so please leave a reply here telling us.
There’s an official documentation now available here: FHEM reference, and some (german) instructions for new users in the FHEM wiki, especially RHASSPY/Schnellstart – FHEMWiki might be interesting.
Additional note: The coding itself is highly independent on the language used (or even allows several to be used in parallel), and all “identifier pieces” (like device names or room info) are provided as additional infos (called attributes) attached to the devices (FHEM entities).
Same here. Rejoes implementation for Rhasspy inside FHEM is really great. I had a few struggles with the satellite config at first and also one small issue with using FHEM on Windows, but it runs fine and very reliable for more than a year now. What astonishes me is that i have only very few false positives from the porcupine wakeword, really 0 ! false positives from TV or Radio/spotify using a Jabra 510 as micro and speaker. However i also do Homeoffice and many hours of conferencing, and that leads to maybe 1-3 false positives a day. Rejoes implementation allows to send Rhasspy to sleep if that gets annoying.
From the FHEM community i have implemented a weather skill, a joke skill and am working on Jenss Wikipedia skill.
Larynx is nice, but it has a few more difficulties with german pronounciation than nanotts.“sch“,“au“,“st“ and “eu“ sometimes get wrong, and it has a strange tendency to add a terminal “s“, e.g. „Digit of Pi“ ends like „Pis“. But all that can be worked around…
The plan was to use rhasspy to ask for time, weather, temperatures, play music, start some automations, maybe set timers or switch lights. And for grocy to use/buy products or add them to shopping list.
The reality is its nearly not used because i dont know how to configure my rpi satellite with respeaker, alsa + squeezelite in a docker for both to use the same audio device so i can play music and hear voice using the same boxes. As soon as the player had been started i cannot hear anything rhasspy says so its fairly useless beside switching on the player.
The other thing is missing AEC or something else so i could speak while playing decent music.
For a speaker I think pausing squeezelite, letting rhasspy say its thing, then resuming the music would be sensible - but I doubt the OS allows two programs to share the same physical device. Huge effort went into being able to share disk drives, cpus and video (using windows) - and that’s without Docker trying to keep containers separate. I assume you have considered using a basic speaker for Rhasspy and a separate stereo audio out device for music on the same machine ?
And yes, the lack of AEC and other signal processing for the reSpeaker devices is really disappointing, and highlights that seeed and Espressif are in the business of making hardware, not complete solutions.
There must be a way to mix different sources with alsa, but i dont know how.
I dont know much about audio things.
Rhasspy can only play if squeezelite is switched off.
In HA you cannot use rhasspy as a TTS, you have to send mqtt topics.
There was some discussion how to play speech with the media player, but the speech is in rhasspy, not HA, …, …, …
Regarding separate speaker, i have nothing at hand to try and i try to reduce/multiuse little things needing power like ESPs, Pis, extra boxes.
Often the respeaker /etc/asound.conf is already installed to be shared but only exists on the host and needs to be shared in the docker run.
I am a SnapCast fan as IMO its audiophile quality in its network latency compensation whilst LMS maybe not so.
I have been drawn to LMS / Squeezelite though for its ability to run on ESP32 but have never run it so can not say.
You will have to tell me what types of input it can have but this is where Snapcast also shines as just about any sink/source you can think of is supported.
Where the Meta Sources last in list will read and mix audio from other stream sources.
If you can don’t run a desktop that will bring in pulseaudio/pipewire as ALSA itself is confusing but I have found portaudio starts missing alsa pcm’s when pulseaudio is installed and it starts getting even more confusing.
You just have to remember even though the docker run shares all sound devices via
--device /dev/snd:/dev/snd \ on that line there still maybe no /etc/asound.conf or even asound installed in the container. Gstreamer and vanilla ALSA is prob a better way to go as I haven’t really worked out pulseaudio in a container.
But without doubt you can share devices on Linux and through docker but that containers are totally isolated instances is often a common gotcha and you have to declare those shares and make sure your container has the same conf files and installs.
A docker run with /etc/asound.conf shared would look like this, where the lefthand side is the file/folder to share and the righthand side how it will be mounted in a container.
I think basically once a driver is on a host its basically shared as a pcm, my memory is awful and would have to give things a revisit. But you need a unique ipc_key for each instance and like us all ALSA at 1st will likely baffle and just copy and paste some examples as you do Google search as the documentation is really stinky.
I just noticed on that info
ipc_key 1024 # must be unique!
# ipc_key_add_uid false # let multiple users share
# ipc_perm 0666 # IPC permissions for multi-user sharing (octal, default 0600)
Does ipc_key_add_uid true mean it auto creates a uid so i don’t have to bother thinking about clashing IPC keys? Who knows but welcome to the wonderful documentation of ALSA that is the base of all Linux audio.
Here is a respeaker 2 mic example
# The IPC key of dmix or dsnoop plugin must be unique
# If 555555 or 666666 is used by other processes, use another one
# use samplerate to resample as speexdsp resample is bad
defaults.pcm.rate_converter "samplerate"
pcm.!default {
type asym
playback.pcm "playback"
capture.pcm "capture"
}
pcm.playback {
type plug
slave.pcm "dmixed"
}
pcm.capture {
type plug
slave.pcm "array"
}
pcm.dmixed {
type dmix
slave.pcm "hw:seeed2micvoicec"
ipc_key 555555
}
pcm.array {
type dsnoop
slave {
pcm "hw:seeed2micvoicec"
channels 2
}
ipc_key 666666
}
But each instance all the IPC keys must be unique so you need to create a copy elsewhere and change the IPC keys and share that instead as sharing /etc/asound.conf was just an example, the copy could be just
# The IPC key of dmix or dsnoop plugin must be unique
# If 555555 or 666666 is used by other processes, use another one
# use samplerate to resample as speexdsp resample is bad
defaults.pcm.rate_converter "samplerate"
pcm.!default {
type asym
playback.pcm "playback"
capture.pcm "capture"
}
pcm.playback {
type plug
slave.pcm "dmixed"
}
pcm.capture {
type plug
slave.pcm "array"
}
pcm.dmixed {
type dmix
slave.pcm "hw:seeed2micvoicec"
ipc_key 555556
}
pcm.array {
type dsnoop
slave {
pcm "hw:seeed2micvoicec"
channels 2
}
ipc_key 666667
}
Then the ipc keys are unique with a docker run with -v " /etc/asound2.conf:/etc/asound.conf" \ or whereever you want to store the file on the host.
PS I haven’t a clue to what # use samplerate to resample as speexdsp resample is bad is supposed to mean but there is another problem with respeaker as for what ever reason the respeaker doesn’t like it but generally speexdsp resample is an amazingly low load resampler that is perfect for this type of conversion. I don’t even know why it states that but speexdsp resample is not bad and I do know that, its one of those audiophile arguments that us mere mortals can hear absolutely no difference.
Espressif do have a complete solution and pretty sure I have posted this several times before.
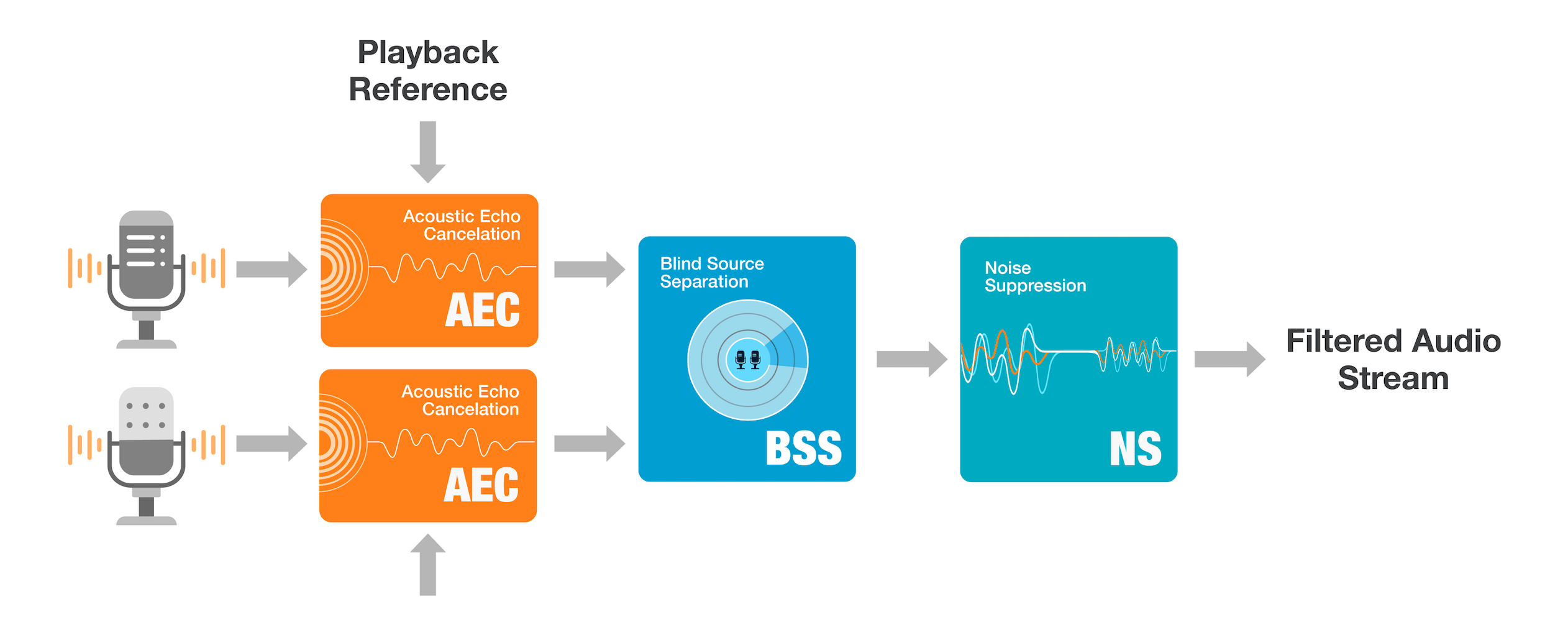
The only prob is that its esspressif and not opensource which might be no problem they have gone a similar way to Google and use blind source seperation as opposed to beamforming.
Also with AEC its not part of what is purely an audio codec (soundcard) on a hat but we have always had opensource AEC.
1… Speex AEC
2… WebRTC AEC
The later is actually cancels but totally fails over a certain echo to signal ratio whilst Speex AEC will continue to attenuate.
AEC has been missing from Rhasspy, but also there seems to be this myth of magic microphones that can sit infront or ontop of speakers with out any thought to isolation as even state of art AEC will likely fail at those huge echo to signal ratio differences.
GitHub - voice-engine/ec: Echo Canceller, part of Voice Engine project is actually ok to attenuate a reference signal for Echo Cancelation but its an absolute myth you can just take a hat stick in on a Pi in thin plastic box with a speaker and expect some sort of magic software to work at those levels.
The only filter I have ever seen work close to the levels needed is GitHub - Rikorose/DeepFilterNet: Noise supression using deep filtering as it is really RtxVoice level whilst Speex harks back to algs rather than more modern models even RnnNoise that has a small model sucks big style compared to DeepFilterNet and the author has hinted at a possible AEC version.
The AEC we have comes with some caveats that when the FFT is binning and analysing the signal there needs absolute clock sync provided by the input and output audio sharing the same clock signal or the clock drift between seperate clocks means often the alg is constantly trying to sync the signal and fails so no AEC.
But its always been available and I have screamed and hair pulled to mangle portaudio and a delaysum beamformer on my 1st ever attempt at C/C++ as Python just sucks big style for any dsp the load would be huge otherwise.
Respeaker also did have some access to some free Alango algs but I think they might of parted ways as sanebow spent some time building the C libs to report back it wasn’t very good anyway, but pretty sure that was part of the original Snips.
The problem is that its Rhasspy missing these methods and still is as you need to sync KWS so your beamformer locks onto the direction of the user for that command sentence.
The Esspressif doesn’t use a beamformer they have gone for Blind Source seperation that likely will try to seperate mixed signals by TDOA and often works that nMics can seperate into nStreams.
I have never managed to compile a working BSS but expect it also provides like a beamformer especially if mics are positioned correctly it provides also a level of deverberation and rear rejection.
The problem with BSS is you never have any idea the order the streams come out and because its closed source I don’t think they have managed Googles eloquent system of voicefilter-lite but if I had to guess they have VAD working the seperated streams to choose what is pushed to KWS rather than targetted voice extraction.
Also at guesses I think they have just ported SpeexAEC to ESP32 and why you need a 3rd channel ADC so that DAC output is synced and hardcoded into the capture stream in a standard hardware loopback method. There AEC hardware design needs a 3+ ADC so the 3rd is a hardware loopback.
The intergration of hardware and audio processing to link to Rhasspy modules is missing and likely will never be provided by hardware unless a hardware KWS device becomes a thing and that can replace the rhasspy KWS where it is missing.
Another notable mention where the great repo’s by sanebow
This has a model AEC that is non linear and doesn’t suffer from clock sync and could go higher up the chain.
Compared to DeepFilterNet they do provide quite strong artefacts but if you used KWS & ASR datasets that where mixed with noise and then pre-filtered by the filter of use those artefacts would become part of recognition of the trained model of those datasets.
There is an additional integration for home assistant called music assistant. It will clone existing media_player instances which you then can use to send audio announcements, similar to google home.
I can either use tts.google_say or tts.google_cloud to send text to the music assistant media_player. It will mute the existing audio stream, play a very short bell ringing, play the tts and then unmute the stream again. It works really good, highly recommend.
As to the original topic and the poll: I’m not using rhasspy at the moment, because I got frustrated by the wakeword detection, or lack thereof. But with home assistant declaring 2023 the year of the voice and hiring @synesthesiam (congrats btw) I want to give it another shot.
As for the hardware, I’m using “hacked” xiaomi smart speakers based on this repo. I currently have 2 lx06 that are used for playing music and now the aforementioned announcements (timer finished, good morning briefing). I’ll update the porcupine version to 2.1 (from 1.9) and see how it looks. I also have two lx01 which I currently don’t use.
Overall I’m really excited that this is happening though.
Another thing i would like to use is a nice language specific wake word. The only one not sounding strange or english and get recogniced well is alexa. I dont like calling my rhasspy Alexa, because its especially NOT an Alexa.
I hope this comes with the year of voice
After 3 weeks only 20 votes, and few from people who consider themselves ‘developers’, so I wonder if it is representative of the full Rhasspy user base.
It does show fairly conclusively that
Base + Satellite is the main configuration for Rhasspy (85%)
Home Assistant integration is important (73%)
being a toolkit to integrate with other systems is also a main feature (52%)
Analysing the user base is harder because (a) the terms are vague, and (b) I suspect the forum is frequented more by new users seeking help than experienced users with working systems.
Hi Don, FYI this is my experience with linking HA with Rhasspy and node-RED. YMMV.
I started using Rhasspy with HA by sending the intents using the Home Assistant + Intents method, and it works fine (though I found that I needed to setup a long-lived access token). I documented this here
Since then I started using the HA node-RED add-on, and changed all my HA automations to node-RED because I found it easier to follow the flows in node-RED.
All my Rhasspy intents are running automations anyway, so I now have node-RED capturing and processing the MQTT messages for intents. I no longer have any automations or intent processing in Home Assistant, and my Rhasspy “Intent Handling” setting is set to “disabled” on all Rhasspy machines.
If you are already familiar with node-RED, you will probably find it pretty easy. However I won’t push anyone to go in that direction because … well, because Node-RED is yet another technology learning curve to climb, and I have learnt the hard way not to tackle more than one new technology at a time
Thanks for the advice. You were right, once I switched to NR, I found it much easier. I just realized that i forgot to answer one of your questions: I hope to have somewhere between 6 and 10 satellites (depends on how close I end up needing to be for them to pick up my requests – I’m using Android phones).